Aggiornare repliche del gruppo di disponibilità
Si applica a: ![]() SQL Server
SQL Server
Quando si aggiorna un'istanza di SQL Server che ospita un gruppo di disponibilità Always On a una nuova versione di SQL Server, a un nuovo Service Pack o aggiornamento cumulativo di SQL Server oppure quando la si installa in un nuovo Service Pack o aggiornamento cumulativo di Windows, è possibile ridurre i tempi di inattività per la replica primaria a un singolo failover manuale eseguendo un aggiornamento in sequenza (o a due failover manuali in caso di failback sulla replica primaria originale).
Durante il processo di aggiornamento, non sarà disponibile una replica secondaria per il failover o le operazioni di sola lettura e, dopo l'aggiornamento, a seconda del volume di attività nel nodo della replica primaria, l'aggiornamento della replica secondaria al nodo della replica primaria potrebbe richiedere un po' di tempo (è dunque prevedibile un traffico di rete elevato).
Occorre sapere anche che dopo il failover iniziale in una replica secondaria che esegue una versione più recente di SQL Server, i database di tale gruppo di disponibilità saranno sottoposti a un processo di aggiornamento affinché la versione adottata sia la più recente. Durante questa operazione le repliche non saranno leggibili per nessuno di questi database. Il tempo di inattività dopo il failover iniziale dipenderà dal numero di database contenuti nel gruppo di disponibilità. Se si prevede di eseguire il failback sulla replica primaria originale, questo passaggio non sarà ripetuto durante il failback.
Nota
Questo articolo si limita a illustrare l'aggiornamento di SQL Server. Non viene descritto l'aggiornamento del sistema operativo che contiene WSFC (Windows Server Failover Cluster). L'aggiornamento del sistema operativo Windows che ospita il cluster di failover non è supportato per i sistemi operativi precedenti a Windows Server 2012 R2. Per aggiornare un nodo del cluster in esecuzione in Windows Server 2012 R2, vedere Aggiornamento in sequenza del sistema operativo del cluster.
Prerequisiti
Prima di iniziare, esaminare le informazioni seguenti:
Aggiornamenti di versione ed edizione supportati: verificare che sia possibile eseguire l'aggiornamento all’ultima versione di SQL Server 2016 dalla versione in uso del sistema operativo Windows e di SQL Server. Ad esempio, se si esegue l'aggiornamento direttamente da un'istanza di SQL Server 2005, il livello di compatibilità del database verrà aggiornato.
Scegliere un metodo di aggiornamento del motore di database: per il corretto ordine di aggiornamento, selezionare il metodo e la procedura di aggiornamento appropriati in base alla verifica degli aggiornamenti di versione ed edizione supportati e anche agli altri componenti installati nell'ambiente.
Pianificare e testare il piano di aggiornamento del motore di database: esaminare le note sulla versione, i problemi di aggiornamento noti e l'elenco di controllo pre-aggiornamento e sviluppare e testare il piano di aggiornamento.
Requisiti hardware e software per l'installazione di SQL Server: esaminare i requisiti software per l'installazione di SQL Server. Se è necessario software aggiuntivo, installarlo in ogni nodo prima di iniziare il processo di aggiornamento per ridurre al minimo eventuali tempi di inattività.
Verificare se Change Data Capture o la replica vengono usati per i database del gruppo di disponibilità: se un database all'interno del gruppo di disponibilità è abilitato per Change Data Capture (CDC), seguire queste istruzioni.
Nota
L'uso di più versioni delle istanze di SQL Server nello stesso gruppo di disponibilità è supportato solo nel contesto di un aggiornamento in sequenza e non deve rimanere in tale stato per periodi di tempo prolungati perché l'aggiornamento deve essere eseguito rapidamente. L'altra opzione per eseguire l'aggiornamento di SQL Server 2016 (13.x) e versioni successive prevede l'uso di un gruppo di disponibilità distribuito.
Nota
L'uso della funzionalità aggiornamento compatibile con cluster per aggiornare i gruppi di disponibilità AlwaysOn non è supportato.
Introduzione agli aggiornamenti in sequenza per i gruppi di disponibilità
Per ridurre al minimo i tempi di inattività e la perdita di dati per i gruppi di disponibilità, osservare le linee guida seguenti quando si eseguono gli aggiornamenti dei server:
Prima di iniziare l'aggiornamento in sequenza:
Eseguire un failover manuale di prova su almeno una delle istanze di replica con commit sincrono
Proteggere i dati eseguendo un backup completo di ogni database di disponibilità
Eseguire
DBCC CHECKDBsu ogni database di disponibilità
Aggiornare sempre prima le istanze di replica secondaria remota, quindi quelle di replica secondaria locale e, infine, l'istanza di replica primaria.
Non è possibile eseguire backup su un database in corso di aggiornamento. Prima di eseguire l'aggiornamento delle repliche secondarie, configurare la preferenza per i backup automatici in modo che vengano eseguiti solo sulla replica primaria. Durante un aggiornamento di versione, le repliche non sono né leggibili né disponibili per i backup. Durante un aggiornamento non di versione, è possibile configurare l'esecuzione di backup automatici sulle repliche secondarie prima di aggiornare la replica primaria.
Durante un aggiornamento di versione, non è possibile leggere repliche secondarie leggibili dopo il relativo aggiornamento e prima che venga eseguito il failover della replica primaria su una replica secondaria aggiornata o che venga aggiornata la replica primaria.
Per evitare failover accidentali del gruppo di disponibilità durante il processo di aggiornamento, rimuovere il failover da tutte le repliche con commit sincrono prima di iniziare.
Non aggiornare l'istanza di replica primaria prima di aver eseguito il failover del gruppo di disponibilità su un'istanza aggiornata con una replica secondaria. In caso contrario, le applicazioni client potrebbero subire tempi di inattività prolungati durante l'aggiornamento sull'istanza di replica primaria.
Eseguire sempre il failover del gruppo di disponibilità su un'istanza di replica secondaria con commit sincrono. Se si esegue il failover su un'istanza di replica secondaria con commit asincrono, i database sono soggetti alla perdita di dati e lo spostamento dei dati viene automaticamente sospeso fino a quando non viene ripreso manualmente.
Non aggiornare l'istanza di replica primaria prima di aver aggiornato tutte le altre istanze di replica secondaria. Non è più possibile recapitare log tramite una replica primaria aggiornata alle repliche secondarie la cui istanza di SQL Server non è ancora stata aggiornata alla stessa versione. Se viene sospeso lo spostamento dei dati in una replica secondaria, il failover automatico per quest'ultima non può essere eseguito e nei database di disponibilità possono verificarsi perdite di dati. Questo vale anche per un aggiornamento in sequenza in cui si esegue manualmente il failover da una replica primaria precedente a una nuova replica primaria. In quanto tale, dopo aver aggiornato la replica primaria precedente, potrebbe essere necessario riprendere la sincronizzazione.
Prima di eseguire il failover di un gruppo di disponibilità, verificare che lo stato di sincronizzazione della destinazione di failover sia
SYNCHRONIZED.Avviso
L'installazione di una nuova istanza o di una nuova versione di SQL Server in un server in cui è installata una versione precedente di SQL Server potrebbe inavvertitamente causare un'interruzione di qualsiasi gruppo di disponibilità ospitato dalla versione precedente di . Infatti, durante l'installazione dell'istanza o della versione di SQL Server, viene aggiornato il modulo di disponibilità elevata di SQL Server (RHS.EXE). Questo aggiornamento determina un'interruzione temporanea dei gruppi di disponibilità esistenti nel ruolo primario del server. Quando si installa una versione più recente di SQL Server in un sistema che ospita già una versione precedente di SQL Server con un gruppo di disponibilità è pertanto consigliabile seguire una delle procedure seguenti:
Installare la nuova versione di SQL Server durante una finestra di manutenzione.
Eseguire il failover del gruppo di disponibilità nella replica secondaria in modo che non risulti primaria durante l'installazione della nuova istanza di SQL Server.
Processo di aggiornamento in sequenza
Il processo effettivo dipende da fattori quali la topologia di distribuzione dei gruppi di disponibilità e la modalità di commit di ogni replica. Nello scenario più semplice, l'aggiornamento in sequenza è articolato in un processo a più fasi che nella sua forma essenziale prevede i passaggi seguenti:

- Rimuovere il failover automatico in tutte le repliche con commit sincrono
- Aggiornare tutte le istanze di replica secondaria con commit asincrono.
- Aggiornare tutte le istanze di replica secondaria con commit sincrono remote.
- Aggiornare tutte le istanze di replica secondaria con commit sincrono locali.
- Eseguire manualmente il failover del gruppo di disponibilità su una replica secondaria con commit sincrono locale appena aggiornata.
- Aggiornare l'istanza di replica locale in cui, in precedenza, era ospitata la replica primaria.
- Configurare i partner di failover automatico in base alle proprie preferenze.
Se necessario, è possibile eseguire un ulteriore failover manuale per ripristinare la configurazione originale del gruppo di disponibilità.
Nota
L'aggiornamento di una replica con commit sincrono e la relativa impostazione offline non comporteranno un ritardo delle transazioni nella replica primaria. Dopo che la replica secondaria è stata disconnessa, il commit delle transazioni avviene nella replica primaria senza attendere la finalizzazione dei log nella replica secondaria.
Se REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT è impostato su 1 o 2, la replica primaria può non risultare disponibile per le operazioni di lettura/scrittura quando non è disponibile un numero corrispondente di repliche secondarie di sincronizzazione durante il processo di aggiornamento.
Nota
Quando si esegue un aggiornamento sul posto di una replica secondaria a una versione più recente di SQL Server, il database all'interno del gruppo di disponibilità rimane nello stato Synchronizing/In recovery o Synchronized/In Recovery finché sul gruppo di disponibilità non viene eseguito manualmente il failover, che termina il ripristino e aggiorna il database. Una replica primaria aggiornata non può più spedire i log a qualsiasi replica secondaria di versione precedente e lo spostamento dei dati si arresta e non può verificarsi alcun failover automatico per tale replica e i database di disponibilità sono vulnerabili alla perdita di dati. Dopo aver aggiornato la replica primaria precedente, potrebbe essere necessario riprendere la sincronizzazione. È consigliabile aggiornare tutte le repliche secondarie prima del failover a una replica con la nuova versione. In questo modo è possibile eseguire un failover dopo l'aggiornamento del database al nuovo formato.
Gruppo di disponibilità con una replica secondaria remota
Se è stato distribuito un gruppo di disponibilità solo a fini di ripristino di emergenza potrebbe essere necessario eseguirne il failover su una replica secondaria con commit asincrono. Questo tipo di configurazione è illustrato nella figura seguente:

In questo caso è necessario eseguire il failover del gruppo di disponibilità su una replica secondaria con commit asincrono durante l'aggiornamento in sequenza. Per evitare perdite di dati, modificare la modalità di commit impostando il commit sincrono e attendere che venga completata la sincronizzazione della replica secondaria prima di eseguire il failover del gruppo di disponibilità. Il processo di aggiornamento in sequenza può quindi avvenire come segue:
- Aggiornare l'istanza di replica secondaria sul sito remoto
- Impostare la modalità di commit sincrono
- Attendere che lo stato di sincronizzazione sia
SYNCHRONIZED - Eseguire il failover del gruppo di disponibilità sulla replica secondaria nel sito remoto
- Aggiornare l'istanza di replica (sito primario) locale
- Eseguire di nuovo il failover del gruppo di disponibilità sul sito primario
- Impostare la modalità di commit asincrono
Poiché la modalità di commit sincrono non è consigliata per la sincronizzazione dei dati con un sito remoto, tramite le applicazioni client potrebbe essere rilevato un aumento immediato della latenza del database in seguito alla modifica dell'impostazione. L'esecuzione di un failover causa inoltre la rimozione di tutti i messaggi di log non riconosciuti. Il numero di messaggi di log rimossi può essere notevole a causa dell'elevata latenza di rete tra i due siti determinando un numero elevato di errori delle transazioni nei client. È possibile ridurre l’effetto sulle applicazioni client con le azioni seguenti:
Scegliere con attenzione una finestra di manutenzione nei periodi di minore traffico client
Durante l'aggiornamento di SQL Server nel sito primario, impostare di nuovo la modalità di commit asincrono, quindi ripristinare il commit sincrono una volta pronti a effettuare nuovamente il failover al sito primario
Gruppo di disponibilità con nodi di istanze del cluster di failover
Se in un gruppo di disponibilità sono contenuti nodi di istanze del cluster di failover, è consigliabile aggiornare i nodi inattivi prima di quelli attivi. Nella figura seguente è illustrato uno scenario comune di gruppi di disponibilità con istanze del cluster di failover per la disponibilità elevata locale e il commit asincrono tra le istanze stesse ai fini del ripristino di emergenza remoto ed è indicata la relativa sequenza di aggiornamento.
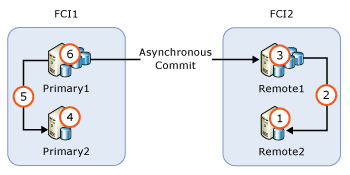
- Aggiornamento
REMOTE2 - Failover di FCI2 in
REMOTE2 - Aggiornamento
REMOTE1 - Aggiornamento
PRIMARY2 - Failover di FCI1 in
PRIMARY2 - Aggiornamento
PRIMARY1
Aggiornare le istanze di SQL Server con più gruppi di disponibilità
Se si eseguono più gruppi di disponibilità con repliche primarie su nodi server distinti (configurazione Attiva/Attiva), il percorso di aggiornamento prevede altri passaggi di failover per preservare la disponibilità elevata durante il processo. Si supponga di avere tre gruppi di disponibilità in tre nodi server con tutte le repliche in modalità commit sincrono come illustrato nella tabella seguente:
| AG | Node1 | Node2 | Nodo3 |
|---|---|---|---|
| AG1 | Server/istanza primaria | ||
| AG2 | Server/istanza primaria | ||
| AG3 | Server/istanza primaria |
In determinate situazioni potrebbe essere opportuno eseguire un aggiornamento in sequenza con bilanciamento del carico articolato come segue:
- Effettuare il failover di AG2 a
Node3(per liberareNode2) - Aggiornamento
Node2 - Effettuare il failover di AG1 a
Node2(per liberareNode1) - Aggiornamento
Node1 - Effettuare il failover di AG2 e AG3 a
Node1(per liberareNode3) - Aggiornamento
Node3 - Eseguire il failover di AG3 in
Node3
Questa sequenza di aggiornamento implica un tempo di inattività medio inferiore alla durata di due failover per gruppo di disponibilità. La configurazione risultante è illustrata nella tabella seguente.
| AG | Node1 | Node2 | Nodo3 |
|---|---|---|---|
| AG1 | Server/istanza primaria | ||
| AG2 | Server/istanza primaria | ||
| AG3 | Server/istanza primaria |
Il percorso di aggiornamento e i tempi di inattività per le applicazioni client possono variare a seconda della specifica implementazione in uso.
Nota
In molti casi, dopo aver completato l'aggiornamento in sequenza, sarà possibile eseguire il failback sulla replica primaria originale.
Aggiornamento in sequenza di un gruppo di disponibilità distribuito
Per eseguire un aggiornamento in sequenza di un gruppo di disponibilità distribuito, aggiornare prima tutte le repliche secondarie. Quindi eseguire il failover dell'istanza di inoltro e aggiornare l'ultima istanza rimanente del secondo gruppo di disponibilità. Dopo che tutte le altre repliche sono state aggiornate, eseguire il failover della replica primaria globale e quindi aggiornare l'ultima istanza rimanente del primo gruppo di disponibilità. Di seguito è riportato un diagramma dettagliato con questa procedura.
Il percorso di aggiornamento e i tempi di inattività per le applicazioni client possono variare a seconda della specifica implementazione in uso.
Nota
In molti casi, dopo aver completato l'aggiornamento in sequenza sarà possibile eseguire il failback sulla replica primaria originale.
Procedura generica per l'aggiornamento di un gruppo di disponibilità distribuito
- Eseguire il backup di tutti i database, inclusi i database di sistema e quelli che fanno parte del gruppo di disponibilità.
- Eseguire l'aggiornamento e riavviare tutte le repliche secondarie del secondo gruppo di disponibilità (downstream).
- Eseguire l'aggiornamento e riavviare tutte le repliche secondarie del primo gruppo di disponibilità (upstream).
- Eseguire il failover dell'istanza di inoltro primaria a una replica secondaria aggiornata del gruppo di disponibilità secondario.
- Attendere la sincronizzazione dei dati. I database devono risultare sincronizzati in tutte le repliche con commit sincrono e l'istanza primaria globale deve essere sincronizzata con l'istanza di inoltro.
- Eseguire l'aggiornamento e riavviare l'ultima istanza rimanente del gruppo di disponibilità secondario.
- Effettuare il failover dell'istanza primaria globale a un'istanza secondaria aggiornata del primo gruppo di disponibilità.
- Aggiornare l'ultima istanza rimanente del gruppo di disponibilità primario.
- Riavviare il server appena aggiornato.
- (Facoltativo) Eseguire il failback di entrambi i gruppi di disponibilità alle repliche primarie originali.
Importante
Verificare sempre il completamento della sincronizzazione tra i singoli passaggi. Prima di procedere con il passaggio seguente, verificare che all'interno del gruppo di disponibilità le repliche con commit sincrono siano sincronizzate e che l'istanza primaria globale sia sincronizzata con l'istanza di inoltro nel gruppo di disponibilità distribuito.
Consiglio: durante la verifica della sincronizzazione, aggiornare sia il nodo del database sia il nodo del gruppo di disponibilità distribuito in SQL Server Management Studio. Dopo il completamento della sincronizzazione, salvare uno screenshot degli stati di ogni replica. In tal modo è possibile tenere traccia della fase in corso, garantire che tutto funzioni correttamente prima del passaggio successivo e facilitare la risoluzione dei problemi in caso di errori.
Diagramma di esempio per l'aggiornamento in sequenza di un gruppo di disponibilità distribuito
| Gruppo di disponibilità | Replica primaria | Replica secondaria |
|---|---|---|
| AG1 | NODE1\SQLAG |
NODE2\SQLAG |
| AG2 | NODE3\SQLAG |
NODE4\SQLAG |
| DistributedAG | AG1 (globale) | AG2 (istanza di inoltro) |

Procedura per aggiornare le istanze in questo diagramma:
- Eseguire il backup di tutti i database, inclusi i database di sistema e quelli che fanno parte del gruppo di disponibilità.
- Aggiornare
NODE4\SQLAG(replica secondaria di AG2) e riavviare il server. - Aggiornare
NODE2\SQLAG(replica secondaria di AG1) e riavviare il server. - Eseguire il failover di AG2 da
NODE3\SQLAGaNODE4\SQLAG. - Aggiornare
NODE3\SQLAGe riavviare il server. - Eseguire il failover di AG1 da
NODE1\SQLAGaNODE2\SQLAG. - Aggiornare
NODE1\SQLAGe riavviare il server. - (Facoltativo) Eseguire il failback alle repliche primarie originali.
- Eseguire il failover di AG2 da
NODE4\SQLAGaNODE3\SQLAG. - Eseguire il failover di AG1 da
NODE2\SQLAGaNODE1\SQLAG.
- Eseguire il failover di AG2 da
Se in ogni gruppo di disponibilità esisteva una terza replica, questa verrà aggiornata prima di NODE3\SQLAG e NODE1\SQLAG.
Importante
Verificare sempre il completamento della sincronizzazione tra i singoli passaggi. Prima di procedere con il passaggio seguente, verificare che all'interno del gruppo di disponibilità le repliche con commit sincrono siano sincronizzate e che l'istanza primaria globale sia sincronizzata con l'istanza di inoltro nel gruppo di disponibilità distribuito.
Consiglio: ogni volta che si verifica la sincronizzazione, aggiornare sia il nodo del database sia il nodo del gruppo di disponibilità distribuito in SQL Server Management Studio. Dopo il completamento della sincronizzazione, salvare uno screenshot dello stato complessivo. In tal modo è possibile tenere traccia della fase in corso, garantire che tutto funzioni correttamente prima del passaggio successivo e facilitare la risoluzione dei problemi in caso di errori.
Passaggi speciali per Change Data Capture o la replica
A seconda dell'aggiornamento che si sta applicando, possono essere necessari passaggi aggiuntivi per i database di replica del gruppo di disponibilità abilitati per Change Data Capture o la replica. Fare riferimento alle note sulla versione relative all'aggiornamento per stabilire se i passaggi seguenti sono necessari:
Aggiornare ogni replica secondaria.
Al termine dell'aggiornamento di tutte le repliche secondarie, eseguire il failover del gruppo di disponibilità su un'istanza aggiornata.
Eseguire l'istruzione Transact-SQL seguente sull'istanza che ospita la replica primaria:
EXECUTE [master].[sys].[sp_vupgrade_replication];Nota
L'esecuzione di questo comando potrebbe richiedere alcuni minuti. Ignorare questo passaggio se si usa SQL Server 2019 CU1 o versione successiva. Per altre informazioni, vedere KB4530283.
Aggiornare l'istanza che era in origine la replica primaria.
Per informazioni di carattere generale, vedere l'articolo sulla possibilità che la funzionalità CDC non funzioni dopo che è stato applicato l'aggiornamento cumulativo più recente.