Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server in Linux
SQL Server in Linux
Questo articolo offre una panoramica delle soluzioni di continuità aziendale per la disponibilità elevata e il ripristino di emergenza in SQL Server.
Tutti gli utenti che distribuiscono SQL Server devono assicurarsi che tutte le istanze cruciali di SQL Server e i database all'interno di essi siano disponibili quando gli utenti aziendali e finali ne hanno bisogno, indipendentemente dal fatto che la disponibilità sia durante l'orario di ufficio normale o intorno al giorno. L'obiettivo è fare in modo che le interruzioni delle attività aziendali siano minime o inesistenti. Questo concetto è noto anche come continuità aziendale.
SQL Server 2017 (14.x) e versioni successive hanno introdotto funzionalità e miglioramenti per la disponibilità. L'aggiunta più grande è il supporto per SQL Server nelle distribuzioni Linux. Per un elenco completo delle nuove funzionalità in SQL Server, vedere gli argomenti seguenti:
| Versione | Sistema operativo |
|---|---|
| Novità di SQL Server 2025 (17.x) | Windows | Linux |
| Novità di SQL Server 2022 (16.x) | Windows | Linux |
| Novità di SQL Server 2019 (15.x) | Windows | Linux |
| Novità di SQL Server 2017 (14.x) | Windows | Linux |
Questo articolo è incentrato sugli scenari di disponibilità in SQL Server 2017 (14.x) e versioni successive, nonché sulle funzionalità di disponibilità nuove e avanzate. Gli scenari includono quelli ibridi che possono estendersi a distribuzioni di SQL Server in Windows Server e Linux e quelli che possono aumentare il numero di copie leggibili di un database.
Anche se questo articolo non tratta le opzioni di disponibilità esterne a SQL Server (ad esempio la virtualizzazione), tutti gli elementi descritti di seguito si applicano alle installazioni di SQL Server all'interno di una macchina virtuale guest, sia nel cloud pubblico che in un server hypervisor locale.
Scenari di SQL Server che usano le funzionalità di disponibilità
È possibile usare i gruppi di disponibilità Always On, le istanze del cluster di failover e il log shipping in modi diversi e non solo per la disponibilità. Esistono quattro modi principali per usare le funzionalità di disponibilità:
- Disponibilità elevata
- Ripristino di emergenza
- Migrazioni e aggiornamenti
- Distribuire copie leggibili di uno o più database
Le sezioni seguenti descrivono le funzionalità pertinenti per ogni scenario. Una funzionalità non coperta è la replica di SQL Server. Anche se la replica di SQL Server non è ufficialmente designata come funzionalità di disponibilità sotto l'ambito Always On, viene spesso usata per rendere ridondanti i dati in determinati scenari. La replica di tipo merge non è supportata per SQL Server in Linux. Per altre informazioni, vedere Replica di SQL Server in Linux.
Importante
Le funzionalità di disponibilità di SQL Server non sostituiscono il requisito di avere una strategia di backup e ripristino affidabile e ben testata. Una strategia di backup e ripristino è l'elemento costitutivo più fondamentale di qualsiasi soluzione per la disponibilità.
Disponibilità elevata
È importante assicurarsi che le istanze o i database di SQL Server siano disponibili se si verifica un problema locale in un data center o in una singola area nel cloud. Questa sezione illustra come le funzionalità di disponibilità di SQL Server possono essere utili. Tutte le funzionalità descritte sono disponibili sia in Windows Server che in Linux.
Gruppi di disponibilità
I gruppi di disponibilità forniscono protezione a livello di database inviando ogni transazione di un database a un'altra istanza o replica, che contiene una copia del database in uno stato speciale. È possibile distribuire un gruppo di disponibilità nelle edizioni Standard o Enterprise. Le istanze che fanno parte di un AG (gruppo di disponibilità) possono essere autonome o istanze del cluster di failover (FCI), descritte nella sezione successiva. Poiché le transazioni vengono inviate a una replica in tempo reale, i gruppi di disponibilità sono consigliati in situazioni che richiedono valori inferiori per il punto di recupero e gli obiettivi del tempo di recupero. Lo spostamento dei dati tra le repliche può essere sincrono o asincrono. L’edizione Enterprise consente fino a tre repliche, inclusa quella primaria, sincrone. Un AG (Gruppo di Disponibilità) ha una copia completa del database con funzioni di lettura/scrittura nella replica primaria, mentre tutte le repliche secondarie non possono ricevere transazioni direttamente dagli utenti finali o dalle applicazioni.
Nota
Always On è un termine generico per le funzionalità di disponibilità in SQL Server e si riferisce sia ai gruppi di disponibilità che alle istanze del cluster di failover. Always On non è il nome della funzionalità AG.
Prima di SQL Server 2022 (16.x), i gruppi di disponibilità fornivano protezione solo a livello di database e non a livello di istanza. Qualsiasi elemento non acquisito nel log delle transazioni o configurato nel database deve essere sincronizzato manualmente per ogni replica secondaria. Alcuni esempi di oggetti che devono essere sincronizzati manualmente sono gli accessi a livello di istanza, i server collegati e SQL Server Agent - processi.
In SQL Server 2022 (16.x) e versioni successive, è possibile gestire gli oggetti di metadati, inclusi utenti, login, autorizzazioni e processi dell'agente SQL Server a livello di AG (gruppo di disponibilità) oltre al livello di istanza. Per altre informazioni, vedere Che cos'è un gruppo di disponibilità indipendente?
Un Availability Group ha anche un altro componente denominato listener, che consente alle applicazioni e agli utenti finali di connettersi senza dover sapere quale istanza di SQL Server ospita la replica primaria. Ogni gruppo di disponibilità ha un proprio listener. Anche se le implementazioni del listener sono leggermente diverse in Windows Server rispetto a Linux, entrambe offrono le stesse funzionalità e usabilità. Il diagramma seguente mostra un gruppo di disponibilità basato su Windows Server che utilizza un cluster di failover di Windows Server (WSFC). Un cluster sottostante a livello di sistema operativo è necessario per la disponibilità, indipendentemente dal fatto che si tratti di in Linux o Windows Server. L'esempio illustra una configurazione semplice a due server, o nodi, in cui il cluster sottostante è un cluster di failover di Windows Server.
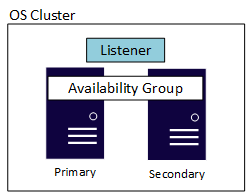
Edizione Standard ed edizione Enterprise hanno valori massimi diversi per quanto riguarda le repliche. Un Availability Group (AG) nell'edizione Standard, noto come gruppo di disponibilità di base, supporta due repliche (una primaria e una secondaria) con un singolo database nell'AG. L'edizione Enterprise non solo consente la configurazione di più database in un singolo AG (gruppo di disponibilità), ma può anche avere fino a nove repliche in totale, una primaria e otto secondarie. L'edizione Enterprise offre anche altri vantaggi facoltativi, ad esempio le repliche secondarie leggibili, la possibilità di eseguire copie di backup da una replica secondaria e altro ancora.
Nota
Il mirroring del database, deprecato in SQL Server 2012 (11.x), non è disponibile nella versione Linux di SQL Server, né viene aggiunto. I clienti che usano ancora il mirroring del database devono iniziare a pianificare la migrazione ai gruppi di disponibilità, che sostituiscono il mirroring del database.
Rispetto alla disponibilità, i gruppi di disponibilità possono offrire il failover automatico o manuale. Il failover automatico può verificarsi se è configurato lo spostamento sincrono dei dati e i database nella replica primaria e secondaria sono in uno stato sincronizzato. Se si usa il listener e l'applicazione usa una versione supportata di .NET Framework (3.5 con Service Pack 1 o 4.6.2 e versioni successive), il failover deve essere gestito con un minimo di nessun effetto sugli utenti finali se viene utilizzato un listener. Il failover per trasformare una replica secondaria nella nuova replica primaria può essere configurato in modo da essere automatico o manuale e in genere viene misurato in secondi.
L'elenco seguente evidenzia alcune differenze con i gruppi di disponibilità in Windows Server rispetto a Linux:
A causa del funzionamento del cluster sottostante su Linux e Windows Server, tutti i failover dei gruppi di disponibilità (manuali o automatici) vengono eseguiti tramite il cluster su Linux. Nelle distribuzioni dei gruppi di disponibilità basati su Windows Server i failover manuali devono essere eseguiti usando SQL Server. I failover automatici vengono gestiti dal cluster sottostante sia in Windows Server che in Linux.
Per SQL Server su Linux, è necessario configurare un gruppo di disponibilità con almeno tre repliche, a causa del modo in cui funziona il clustering sottostante.
In Linux il nome comune usato da ogni listener è definito in DNS e non nel cluster come in Windows Server.
SQL Server 2017 (14.x) ha introdotto le seguenti funzionalità e miglioramenti agli Availability Groups:
- Tipi di cluster
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT- Supporto ottimizzato di Microsoft Distributed Transaction Coordinator (DTC) per le configurazioni basate su Windows Server
- Scenari di scalabilità orizzontale aggiuntivi per i database di sola lettura (descritti più avanti in questo articolo)
Tipi di cluster dei gruppi di disponibilità
Il modulo incorporato di disponibilità del clustering in Windows Server è abilitato da una funzionalità nota come Failover Clustering. Consente di creare un Windows Server Failover Cluster (WSFC) da usare con un Availability Group (AG) o un'istanza del cluster di failover (FCI). SQL Server distribuisce DLL di risorse compatibili con il cluster che forniscono l'integrazione per i gruppi di disponibilità Always On e le istanze del cluster di failover.
SQL Server in Linux supporta più tecnologie di clustering. Microsoft supporta i componenti di SQL Server, mentre i nostri partner supportano la tecnologia di clustering pertinente. Ad esempio, insieme a Pacemaker, SQL Server in Linux supporta anche HPE Serviceguard e DH2i DxEnterprise come soluzione cluster.
Un cluster di failover basato su Windows e una soluzione cluster Linux sono più simili che diversi. Entrambi consentono di prendere singoli server e combinarli in una configurazione per garantire la disponibilità e si basano su concetti come risorse, vincoli (anche se implementati in modo diverso), failover e così via.
Per esempio, per supportare Pacemaker sia per le configurazioni AG che FCI, incluse funzionalità come il failover automatico, Microsoft offre il pacchetto mssql-server-ha, che è simile ma non esattamente identico alle DLL delle risorse in un WSFC, per Pacemaker. Una delle differenze tra un cluster di failover di Windows Server e Pacemaker è che non esiste una risorsa nome rete in Pacemaker, il componente che consente di gestire in modo astratto il nome del listener (o il nome dell'FCI) in un cluster di failover di Windows Server. Usare DNS per la risoluzione dei nomi in Linux.
A causa della differenza nello stack di cluster, i gruppi di disponibilità in SQL Server 2017 (14.x) e versioni successive devono gestire alcuni dei metadati gestiti in modo nativo da un cluster WSFC. Ad esempio, esistono tre tipi di cluster per un gruppo di disponibilità, archiviati nelle sys.availability_groupscluster_type colonne e cluster_type_desc :
- WSFC
- Esterno
- Nessuno
Tutti i Availability Groups (AG) che richiedono un'elevata disponibilità devono utilizzare un cluster di base, il che nel caso di SQL Server 2017 (14.x) e versioni successive significa WSFC o un agente di clustering Linux. Per i gruppi di disponibilità basati su Windows Server che usano un cluster WSFC sottostante, il tipo di cluster predefinito è WSFC e non è necessario impostarlo. Per i gruppi di disponibilità basati su Linux, è necessario impostare il tipo di cluster su Esterno durante la creazione del gruppo di disponibilità. L'integrazione con una soluzione cluster esterna su Linux viene configurata dopo la creazione del gruppo di disponibilità (AG), mentre su un cluster di failover di Windows Server (WSFC), viene configurata durante il processo di creazione.
Un tipo di cluster "None" può essere usato con i gruppi di disponibilità sia di Windows Server che di Linux. Impostare il tipo di cluster su None indica che il gruppo di disponibilità non richiede un cluster sottostante. Ciò significa che SQL Server 2017 (14.x) è la prima versione di SQL Server che supporta i gruppi di disponibilità senza un cluster, ma questo vantaggio è controbilanciato dal fatto che questa configurazione non è supportata come soluzione a disponibilità elevata.
Importante
In SQL Server 2017 (14.x) e versioni successive, non è possibile modificare il tipo di cluster di un gruppo di disponibilità dopo che è stato creato. Questa restrizione significa che un gruppo di disponibilità (AG) non può essere cambiato da Nessuno a Esterno o WSFC e viceversa.
Se si desidera aggiungere solo copie di sola lettura aggiuntive di un database o se si vuole che un gruppo di disponibilità fornisca la migrazione e gli aggiornamenti, ma non si voglia gestire la complessità di un cluster sottostante o anche la replica, è consigliabile configurare un gruppo di disponibilità con un tipo di cluster None. Per altre informazioni, vedere le sezioni Migrazioni e aggiornamenti e scala di lettura.
Lo screenshot seguente mostra il supporto per i diversi tipi di cluster in SQL Server Management Studio (SSMS). È necessario che sia in esecuzione la versione 17.1 o successiva. Lo screenshot seguente è della versione 17.2:

SECONDARI_RICHIESTI_SINCRONIZZATI_PER_CONVALIDARE
SQL Server 2016 (13.x) ha incrementato il supporto per il numero di repliche sincrone da due a tre nell'edizione Enterprise. Tuttavia, se una replica secondaria è sincronizzata, ma l'altra replica presenta un problema, non è possibile controllare il comportamento per indicare al database primario di attendere la replica errata o di consentirgli di spostarsi. In questo scenario, la replica primaria potrebbe comunque ricevere traffico di scrittura anche se la replica secondaria non è in uno stato sincronizzato, causando la perdita di dati nella replica secondaria.
In SQL Server 2017 (14.x) e versioni successive è possibile controllare il comportamento di cosa accade quando sono presenti repliche sincrone con REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT. L'opzione funziona come indicato di seguito:
- Sono disponibili tre valori possibili:
0,1e2. - Il valore è il numero di repliche secondarie che devono essere sincronizzate, con implicazioni per la perdita di dati, la disponibilità dell'AG e il failover.
- Per I WSFCs e un tipo di cluster None, il valore predefinito è
0e è possibile impostarlo manualmente su1o2. - Per un tipo di cluster External, il meccanismo del cluster imposta questo valore per impostazione predefinita ed è possibile eseguirne l'override manualmente. Per tre repliche sincrone, il valore predefinito è
1.
In Linux si configura il valore per REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT nella risorsa del Availability Group nel cluster. In Windows è possibile impostarla tramite Transact-SQL.
Un valore maggiore di 0 garantisce una maggiore protezione dei dati, perché se il numero richiesto di repliche secondarie non è disponibile, il database primario non è disponibile finché tale condizione non viene risolta.
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT influisce anche sul comportamento del failover perché il failover automatico non può verificarsi se il numero corretto di repliche secondarie non è nello stato corretto. In Linux, un valore di 0 non permette il failover automatico, perciò quando si usa il failover sincrono e automatico, è necessario impostare il valore superiore a 0 per ottenere il failover automatico.
0 in Windows Server è il comportamento di SQL Server 2016 (13.x) e versioni precedenti.
Supporto avanzato per Microsoft Distributed Transaction Coordinator
Prima di SQL Server 2016 (13.x), l'unico modo per ottenere la disponibilità in SQL Server per le applicazioni che richiedono transazioni distribuite e che usano DTC a livello sottostante, era implementare le istanze del cluster di failover (ICF). Una transazione distribuita può essere eseguita in due modi:
- Transazione che si estende su più database nella stessa istanza di SQL Server.
- Una transazione che si estende su più di un'istanza di SQL Server o può comportare un'origine dati non SQL Server.
SQL Server 2016 (13.x) ha introdotto un supporto parziale per DTC con i Gruppi di Disponibilità per affrontare il secondo scenario. SQL Server 2017 (14.x) rappresenta un ulteriore passo avanti poiché supporta entrambi gli scenari con il controllo DTC.
In SQL Server 2017 (14.x) e versioni successive è possibile aggiungere il supporto per DTC a un AG dopo la creazione. In SQL Server 2016 (13.x) è possibile abilitare il supporto DTC solo durante la creazione dell'Availability Group.
Istanze del cluster di failover
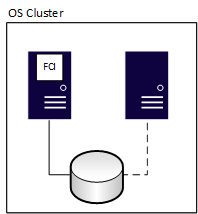
Le istanze di cluster di failover (FCI) forniscono disponibilità per l'intera installazione di SQL Server, nota come un'istanza. Con gli FCI, se il server di base rileva un problema, tutti gli elementi all'interno dell'istanza vengono spostati in un altro server, inclusi i database, i processi di SQL Server Agent, i server collegati e altro ancora. Tutte le FCIs (istanze del cluster di failover) richiedono un'archiviazione condivisa, anche quando è definita dalla rete. Un nodo può gestire e possedere le risorse dell'FCI in qualsiasi momento. Nel diagramma seguente, il primo nodo del cluster possiede l'FCI. Possiede anche le risorse di archiviazione condivise associate, che la linea continua per l'archiviazione indica.
Dopo un failover, la proprietà cambia, come illustrato nel diagramma seguente:
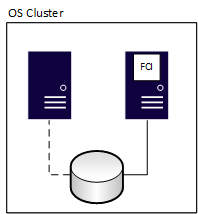
Un'istanza del cluster di failover ha una perdita di dati pari a zero, ma l'archiviazione condivisa sottostante è un singolo punto di errore perché è presente una copia dei dati. Per avere copie ridondanti dei database, combinare le istanze del Failover Cluster con un altro metodo di disponibilità, ad esempio un gruppo di disponibilità o il log shipping. L'altro metodo deve usare un'archiviazione fisicamente separata dall'istanza del cluster di failover (FCI). Quando l'FCI esegue il failover su un altro nodo, si arresta su un nodo e si avvia su un altro. Questo processo è simile allo spegnimento e alla riaccensione di un server.
Un FCI passa attraverso il normale processo di ripristino. Esegue il rollforward di tutte le transazioni che devono essere inoltrate ed esegue il rollback di tutte le transazioni incomplete. Di conseguenza, il database è coerente da un punto dati al momento dell'errore o del failover manuale, quindi non si verifica alcuna perdita di dati. I database sono disponibili solo dopo il completamento del ripristino. Il tempo di ripristino dipende da molti fattori e generalmente è più lungo di un AG di failover. Lo svantaggio è che, quando si esegue il failover di un gruppo di disponibilità, potrebbero essere necessarie attività aggiuntive per rendere utilizzabile un database, come ad esempio attivare un processo dell'agent SQL Server.
Nota
Il ripristino accelerato del database (ADR) può ridurre il tempo di ripristino. Per altre informazioni, vedere Ripristino accelerato del database.
Come un gruppo di disponibilità (AG), le istanze del cluster di failover (FCIs) individuano quale nodo del cluster sottostante le sta ospitando. Un FCI mantiene sempre lo stesso nome. Le applicazioni e gli utenti finali non si connettono mai ai nodi. Usano invece il nome univoco assegnato all'FCI. Un FCI può partecipare a un AG come una delle istanze che ospitano una replica principale o secondaria.
L'elenco seguente evidenzia alcune differenze tra le FCI su Windows Server e Linux.
- In Windows Server un'istanza FCI è parte del processo di installazione. Dopo l'installazione di SQL Server, si configura un'istanza del cluster di failover (FCI) su Linux.
- Linux supporta solo una singola installazione di SQL Server per host, quindi tutte le istanze del Failover Cluster sono istanze predefinite. Windows Server supporta fino a 25 FCI per WSFC.
- Il nome comune usato dalle istanze FCI in Linux è definito in DNS e deve essere lo stesso della risorsa creata per l'istanza FCI.
Trasferimento dei log
Se gli obiettivi del punto di ripristino e del tempo di ripristino sono più flessibili o i database non sono estremamente cruciali, il log shipping è un'altra funzionalità di disponibilità comprovata in SQL Server. In base ai backup nativi di SQL Server, il processo per il log shipping genera automaticamente i backup del log delle transazioni, li copia in una o più istanze, note come warm standby, e applica automaticamente i backup del log delle transazioni a tale standby. Il log shipping utilizza processi di SQL Server Agent per automatizzare i processi di eseguire, copiare e applicare i backup del registro delle transazioni.
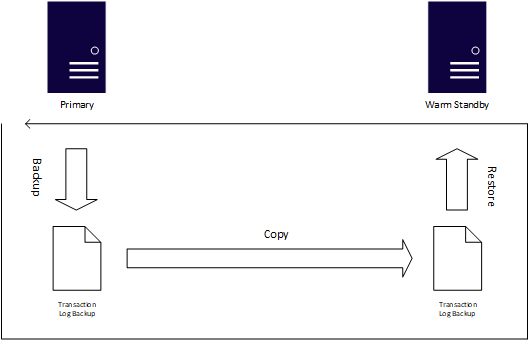
Il vantaggio principale dell'uso del log shipping è che permette di tenere conto degli errori umani, poiché è possibile ritardare l'applicazione dei log delle transazioni. Ad esempio, se un utente emette una UPDATE clausola senza una WHERE clausola, lo standby potrebbe non avere la modifica, in modo da poter passare a tale parametro durante il ripristino del sistema primario. Anche se il log shipping è facile da configurare, il passaggio dal database primario a un warm standby, noto come modifica del ruolo, è sempre manuale. Avvii una modifica del ruolo tramite Transact-SQL e, come un AG (gruppo di disponibilità), è necessario sincronizzare manualmente tutti gli oggetti non acquisiti nel log delle transazioni. È necessario configurare il log shipping per ciascun database, poiché un singolo gruppo di disponibilità (AG) può includere più database.
A differenza di un AG o di un FCI, il log shipping non offre astrazioni per una modifica del ruolo, che le applicazioni devono essere in grado di gestire. È possibile ricorrere a tecniche come l'alias DNS (CNAME), ma esistono pro e contro, ad esempio il tempo necessario per l'aggiornamento di DNS dopo il passaggio.
Ripristino di emergenza
Quando la località di disponibilità primaria è interessata da un evento catastrofico come un terremoto o un'inondazione, l'azienda deve essere pronta a portare i propri sistemi online in altre località. Questa sezione illustra in che modo le funzionalità di disponibilità di SQL Server possono essere utili per la continuità aziendale.
Gruppi di disponibilità
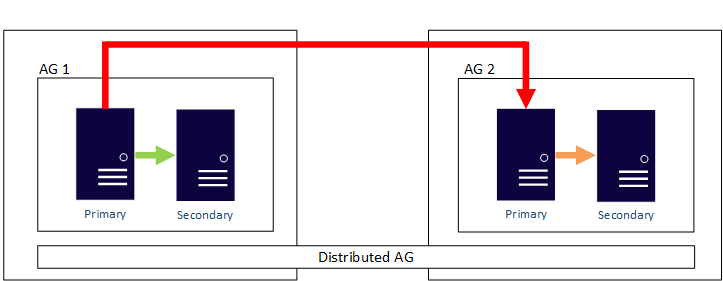
Uno dei vantaggi degli Availability Groups è la possibilità di configurare sia l'Alta Disponibilità (HA) che il Disaster Recovery (DR) utilizzando una singola funzionalità. Se non è necessario garantire la disponibilità elevata anche per l'archiviazione condivisa, è molto più semplice avere repliche che sono locali in un data center per la disponibilità elevata e remote in altri data center per il ripristino di emergenza, ognuna con archiviazione separata. Avere copie aggiuntive del database è il giusto compromesso per garantire la ridondanza. Un esempio di un AG che copre più data center è illustrato nel diagramma seguente. Una sola replica primaria è responsabile della sincronizzazione costante di tutte le repliche secondarie.

Al di fuori di un gruppo di disponibilità con un tipo di cluster impostato su Nessuno, un gruppo di disponibilità richiede che tutte le repliche siano parte dello stesso cluster sottostante, sia esso un WSFC o una soluzione basata su un cluster esterno. Nel diagramma precedente, il cluster WSFC viene esteso per funzionare in due data center diversi, che aggiunge complessità indipendentemente dalla piattaforma (Windows Server o Linux). L'estensione dei cluster oltre una certa distanza aggiunge complessità.
Introdotto in SQL Server 2016 (13.x), un gruppo di disponibilità distribuito consente a un gruppo di disponibilità di estendersi su gruppi di disponibilità configurati in cluster diversi. I gruppi di disponibilità distribuiti disaccoppiano il requisito in base al quale tutti i nodi devono far parte dello stesso cluster e si semplifica notevolmente la configurazione del ripristino di emergenza. Per altre informazioni sui gruppi di disponibilità distribuiti, vedere Gruppi di disponibilità distribuiti.
Istanze del cluster di failover
È possibile utilizzare le istanze del cluster di failover per il ripristino di emergenza. Come per un gruppo di disponibilità normale (AG), è necessario estendere il meccanismo del cluster sottostante a tutte le posizioni, il che aggiunge complessità. Per le istanze del cluster di failover, è necessario anche considerare l'archiviazione condivisa. I siti primari e secondari devono accedere agli stessi dischi. Per assicurarsi che l'archiviazione utilizzata dal FCI sia nei due siti, utilizzare un metodo esterno come la funzionalità fornita dal fornitore di soluzioni di storage a livello hardware. In alternativa, utilizzare Replica di archiviazione in Windows Server.
Diagramma di un'istanza del cluster di failover (FCI) distribuita su data center.
Trasferimento dei log
Il log shipping è uno dei metodi meno recenti per fornire il ripristino di emergenza per i database di SQL Server. Il log shipping viene spesso utilizzato con i gruppi di disponibilità (AG) e le istanze del cluster di failover (FCI) per fornire un ripristino di emergenza più economico e semplice, laddove altre opzioni potrebbero risultare complesse a causa dell'ambiente, delle competenze amministrative o del budget. Analogamente alla storia di disponibilità elevata per il log shipping, molti ambienti ritardano il caricamento di un log delle transazioni per tenere conto dell'errore umano.
Migrazioni e aggiornamenti
Quando un'organizzazione distribuisce nuove istanze o aggiorna quelle precedenti, non può tollerare interruzioni lunghe. Questa sezione illustra come usare le funzionalità di disponibilità di SQL Server per ridurre al minimo il tempo di inattività in una modifica dell'architettura pianificata, cambio di server, modifica della piattaforma (ad esempio Windows Server in Linux o viceversa) o durante l'applicazione di patch.
Nota
È anche possibile usare altri metodi, ad esempio backup e ripristini, per le migrazioni e gli aggiornamenti. Questo articolo non illustra questi metodi.
Gruppi di disponibilità
È possibile aggiornare un'istanza esistente che contiene uno o più gruppi di disponibilità (AG) sul posto, a versioni successive di SQL Server. Anche se questo aggiornamento richiede una certa quantità di tempo di inattività, può essere ridotto al minimo con la giusta quantità di pianificazione.
Se si vuole eseguire la migrazione a nuovi server senza modificare la configurazione (incluso il sistema operativo o la versione di SQL Server), aggiungere tali server come nodi al cluster sottostante esistente, quindi aggiungerli al gruppo di disponibilità. Quando la replica o le repliche sono nello stato corretto, eseguire il failover manuale su un nuovo server. Rimuovere quindi i server precedenti dal gruppo di disponibilità e disattivarli.
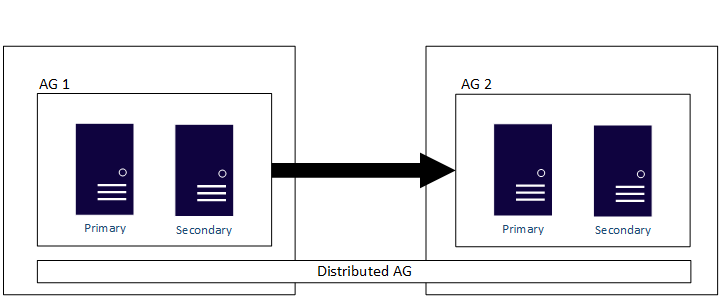
I gruppi di disponibilità distribuiti sono anche un altro metodo per eseguire la migrazione a una nuova configurazione o l'aggiornamento di SQL Server. Poiché un gruppo di disponibilità distribuito supporta diversi gruppi di disponibilità sottostanti in architetture diverse, è possibile passare da SQL Server 2019 (15.x) in esecuzione in Windows Server 2019 a SQL Server 2025 (17.x) in esecuzione in Windows Server 2025.
Infine, i gruppi di disponibilità con un tipo di cluster "nessuno" sono utili per la migrazione o l'aggiornamento. Non è possibile combinare e associare i tipi di cluster in una configurazione tipica del gruppo di disponibilità, quindi tutte le repliche devono essere un tipo none. Un AG distribuito può essere utilizzato per estendere gli AG configurati con diversi tipi di cluster. Questo metodo è supportato anche in piattaforme diverse del sistema operativo.
Tutte le varianti dei gruppi di disponibilità per le migrazioni e gli aggiornamenti consentono di distribuire la sincronizzazione dei dati, che rappresenta la fase più lunga del lavoro, nel tempo. Quando si tratta di avviare il passaggio alla nuova configurazione, il cutover è una breve interruzione, rispetto a un lungo periodo di inattività in cui tutto il lavoro, inclusa la sincronizzazione dei dati, deve essere completato.
I Availability Group (AG) possono ridurre al minimo i tempi di inattività durante l'applicazione delle patch del sistema operativo sottostante. Questo viene eseguito manualmente trasferendo il ruolo primario a una replica secondaria mentre l'applicazione delle patch è in corso. Dal punto di vista del sistema operativo, questa operazione è più comune in Windows Server, perché la manutenzione del sistema operativo sottostante può richiedere un riavvio. L'applicazione di patch a Linux a volte richiede un riavvio, ma è meno comune.
Un altro modo per ridurre al minimo i tempi di inattività consiste nell'applicare patch alle istanze di SQL Server che partecipano a un gruppo di disponibilità, a seconda della complessità dell'architettura del gruppo di disponibilità. Prima di tutto, patchare una replica secondaria. Dopo aver applicato le patch al numero corretto di repliche, eseguire manualmente il failover della replica primaria su un altro nodo per procedere con l'aggiornamento. Aggiornare tutte le repliche secondarie rimanenti a quel punto.
Istanze del cluster di failover
Le FCIs da sole non possono essere utili per una migrazione o un aggiornamento tradizionale. Devi configurare un gruppo di disponibilità (AG) o un log shipping per i database nell'istanza del cluster di failover e considerare tutti gli altri oggetti. Tuttavia, le FCIs sotto Windows Server sono ancora un'opzione comune per quando è necessario applicare patch ai server Windows sottostanti. Quando si avvia un failover manuale, la breve interruzione prende il posto dell'indisponibilità dell'istanza per l'intera durata dell'applicazione delle patch a Windows Server.
È possibile aggiornare direttamente un'FCI a versioni successive di SQL Server. Per ulteriori informazioni, consultare Aggiornare un'istanza del cluster di failover.
Trasferimento dei log
Il log shipping è ancora un'opzione molto diffusa per eseguire sia la migrazione che l'aggiornamento dei database. Simile ai gruppi di disponibilità server (AGs), ma questa volta utilizzando il log delle transazioni come metodo di sincronizzazione, la propagazione dei dati può essere avviata con largo anticipo rispetto al passaggio da un server all’altro. Al momento del passaggio, dopo che tutto il traffico è stato interrotto in corrispondenza dell'origine, è necessario estrarre, copiare e applicare un log delle transazioni finale alla nuova configurazione. A questo punto, il database può essere portato online.
Il log shipping è spesso più tollerante delle reti più lente e, sebbene il passaggio potrebbe richiedere leggermente più tempo rispetto a uno eseguito usando un gruppo di disponibilità Always On o un gruppo di disponibilità distribuito, di solito si misura in minuti, non in ore, giorni o settimane.
Analogamente ai gruppi di disponibilità, il log shipping può consentire il passaggio a un altro server durante una finestra di manutenzione.
Altri metodi di distribuzione di SQL Server e disponibilità
Esistono altri due metodi di distribuzione per SQL Server in Linux: contenitori e uso di Azure (o un altro provider di cloud pubblico). La necessità generale di disponibilità esiste indipendentemente dalla modalità di distribuzione di SQL Server. Questi due metodi hanno alcune considerazioni speciali quando si rende SQL Server a disponibilità elevata.
Contenitori di SQL Server e opzioni di disponibilità elevata/ripristino di emergenza
La distribuzione di contenitori di SQL Server è un modo per semplificare il provisioning, il ridimensionamento e la gestione del ciclo di vita di SQL Server in ambienti diversi. Un contenitore è un'immagine completa pronta per l'esecuzione di SQL Server.
A seconda della piattaforma contenitore, ad esempio quando si usa un agente di orchestrazione del contenitore come Kubernetes, se il contenitore viene perso, può essere distribuito di nuovo e collegato all'archiviazione condivisa usata. Sebbene ciò fornisca una certa resilienza, si verifica un tempo di inattività associato al ripristino del database e questo non offre una vera alta disponibilità, come avverrebbe utilizzando un gruppo di disponibilità o un'istanza di un cluster di failover.
Se si desidera configurare l'alta disponibilità per i container di SQL Server distribuiti su piattaforme Kubernetes o non Kubernetes, è possibile utilizzare DH2i DxEnterprise come una delle soluzioni di clustering, sopra cui è possibile configurare un AG in modalità di alta disponibilità. Questa opzione offre l'obiettivo del punto di ripristino (RPO) e l'obiettivo del tempo di ripristino (RTO) previsti da una soluzione a disponibilità elevata.
Distribuzione di macchine virtuali basate su Linux
Linux può essere distribuito con SQL Server in macchine virtuali Linux di Azure. Come per le installazioni locali, un'installazione supportata richiede l'uso della recinzione di un nodo guasto che è esterno rispetto all'agente del cluster stesso. L'isolamento dei nodi viene fornito tramite agenti di disponibilità di isolamento. Alcune distribuzioni li includono come parte della piattaforma, altri si affidano a fornitori esterni di hardware e software. Verificare con la distribuzione linux preferita per verificare quali forme di isolamento dei nodi sono disponibili in modo che una soluzione supportata possa essere distribuita nel cloud pubblico.
Per le distribuzioni seguenti sono disponibili guide per l'installazione di SQL Server in Linux:
- Avvio rapido: Installare SQL Server e creare un database in Red Hat
- Avvio rapido: Installare SQL Server e creare un database in Ubuntu
- Avvio rapido: Installare SQL Server e creare un database in SUSE Linux Enterprise Server
Scalabilità delle operazioni di lettura
Le repliche secondarie hanno la capacità di essere utilizzate per query di sola lettura. Esistono due modi che possono essere ottenuti con un AG:
- Consentire l'accesso diretto al database secondario
- Configurazione dell'instradamento di sola lettura, che richiede l'uso del listener. SQL Server 2016 (13.x) ha introdotto la possibilità di bilanciare il carico delle connessioni di sola lettura attraverso il listener usando un algoritmo round robin, che consente la diffusione delle richieste di sola lettura in tutte le repliche leggibili.
Nota
Le repliche secondarie leggibili sono disponibili solo in Enterprise Edition. Ogni istanza che ospita una replica leggibile richiede una licenza di SQL Server.
La scalabilità delle copie leggibili di un database tramite gruppi di disponibilità è stata introdotta per la prima volta con i gruppi di disponibilità distribuiti in SQL Server 2016 (13.x). Questa funzionalità offre copie di sola lettura del database non solo in locale, ma anche a livello di area e a livello globale, con una configurazione minima. Questa configurazione riduce il traffico di rete e la latenza grazie all'esecuzione delle query in locale. Ogni replica primaria di un gruppo di disponibilità può eseguire il seeding di due altri gruppi di disponibilità, anche se non è la copia di lettura/scrittura completa e ogni gruppo di disponibilità distribuito può supportare fino a 27 copie leggibili dei dati.

In SQL Server 2017 (14.x) e versioni successive, è possibile creare una soluzione quasi in tempo reale, di sola lettura, con Gruppi di Disponibilità configurati con un tipo di cluster "Nessuno." Se l'obiettivo è usare gli AG per repliche secondarie leggibili e non per scopi di disponibilità, questo approccio rimuove la complessità dell'uso di un cluster WSFC o di una soluzione cluster esterna su Linux. Offre i chiari vantaggi di un AG in una modalità di distribuzione più semplice.
L'unica avvertenza principale è che, dato che non esiste un cluster di tipo None, la configurazione del routing di sola lettura è leggermente diversa. Dalla prospettiva di SQL Server, è comunque necessario un listener per il routing delle richieste anche se non è presente un cluster. Anziché configurare un listener tradizionale, usare l'indirizzo IP o il nome della replica primaria. Successivamente, la replica primaria instrada le richieste di sola lettura.
Un warm standby per il log shipping può essere configurato tecnicamente per l'utilizzo leggibile ripristinando il database WITH STANDBY. Tuttavia, poiché i log delle transazioni richiedono l'uso esclusivo del database per il ripristino, ciò significa che gli utenti non possono accedere al database durante il processo. Per questo motivo il log shipping non è affatto la soluzione ideale, soprattutto se sono richiesti dati near real time.
A differenza della replica transazionale in cui tutti i dati sono in tempo reale, ogni replica secondaria in uno scenario con scalabilità in lettura è una copia esatta del database primario. La replica non è in uno stato in cui è possibile applicare indici univoci. Se sono necessari indici per la creazione di report o se è necessario modificare i dati, è necessario creare tali indici nei database nella replica primaria. Se è necessaria questa flessibilità, la replica è una soluzione migliore per i dati leggibili.
Interoperabilità della distribuzione Linux e multipiattaforma
Con il supporto di SQL Server sia in Windows Server che in Linux, questa sezione illustra come interagiscono per la disponibilità oltre ad altri scopi. Illustra anche la storia delle soluzioni che incorporano più distribuzioni Linux.
Nota
Non esistono scenari in cui un'istanza del cluster di failover basata su WSFC o un gruppo di disponibilità (AG) funziona direttamente con un'istanza del cluster di failover o un gruppo di disponibilità basato su Linux. Un cluster di failover di Windows Server (WSFC) non può essere esteso da un nodo Pacemaker e viceversa.
Gruppi di disponibilità distribuiti
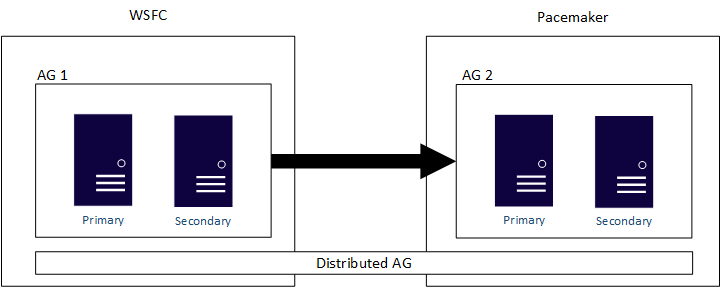
I gruppi di disponibilità distribuiti sono progettati in modo da estendere le configurazioni dei gruppi, indipendentemente dal fatto che i due cluster sottostanti siano due WSFC, due distribuzioni Linux o un WSFC e una distribuzione Linux. Un AG distribuito è il metodo principale per ottenere una soluzione multipiattaforma. Un gruppo di disponibilità distribuito è anche la soluzione principale per le migrazioni, come la conversione di un'infrastruttura SQL Server basata su Windows Server in una su Linux, qualora l'azienda lo desideri. Come indicato in precedenza, i gruppi di disponibilità e, in particolare, i gruppi di disponibilità distribuiti riducono al minimo il tempo in cui un'applicazione non sarebbe disponibile per l'uso. Un esempio di AG distribuito che si estende su un cluster WSFC e Pacemaker è illustrato nel diagramma seguente:
Se si configura un gruppo di disponibilità con un tipo di cluster None, può estendersi su Windows Server e Linux e su più distribuzioni Linux. Poiché questa configurazione non è vera disponibilità elevata, non usarla per le distribuzioni cruciali. Usarlo invece per scenari di migrazione, aggiornamento e scalabilità della lettura.
Trasferimento dei log
Il log shipping è basato su backup e ripristino, quindi non esistono differenze nei database, nelle strutture di file e in altri elementi per SQL Server in Windows Server rispetto a SQL Server in Linux. È possibile configurare il log shipping tra un'installazione di SQL Server basata su Windows Server e una linux e tra le distribuzioni di Linux. Tutti gli altri elementi rimangono invariati.
Proprio come con un Availability Group (AG), il log shipping non funziona quando il server di origine si trova a una versione principale superiore di SQL Server, rispetto a una destinazione con una versione principale inferiore.
Riepilogo
È possibile creare istanze e database di SQL Server 2017 (14.x) e versioni successive a disponibilità elevata usando le stesse funzionalità in Windows Server e Linux. Oltre agli scenari di disponibilità standard di disponibilità elevata locale e ripristino di emergenza, è possibile ridurre al minimo i tempi di inattività associati agli aggiornamenti e alle migrazioni usando le funzionalità di disponibilità in SQL Server. I gruppi di disponibilità possono anche fornire copie aggiuntive di un database come parte della stessa architettura per scalare le copie leggibili. Se si distribuisce una nuova soluzione o si prevede di eseguire un aggiornamento, SQL Server offre la disponibilità e l'affidabilità necessarie.