Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server in Linux
SQL Server in Linux
Questo articolo illustra i concetti relativi alle istanze del cluster di failover di SQL Server in Linux.
Per creare un SQL Server FCI su Linux, vedere Configurare un'istanza del cluster di failover - SQL Server su Linux (RHEL)
Livello di clustering
In Red Hat Enterprise Linux (RHEL) il livello di clustering si basa sul componente aggiuntivo a disponibilità elevata di Red Hat Enterprise Linux (RHEL).
Nota
Per accedere al componente aggiuntivo ad alta disponibilità e alla documentazione di Red Hat, è richiesta una sottoscrizione.
In SUSE Linux Enterprise Server (SLES) il livello di clustering si basa su SUSE Linux Enterprise High Availability Extension (HAE).
Per altre informazioni su configurazione dei cluster, opzioni degli agenti delle risorse, gestione, procedure consigliate e suggerimenti, vedere SUSE Linux Enterprise High Availability Extension 15.
Sia l'add-on HA di RHEL che il SUSE HAE sono basati su Pacemaker.
Come illustrato nel diagramma seguente, la risorsa di archiviazione viene presentata a due server. I componenti di clustering, Corosync e Pacemaker, coordinano le comunicazioni e la gestione delle risorse. Uno dei server ha la connessione attiva alle risorse di archiviazione e a SQL Server. Quando Pacemaker rileva un errore, i componenti di clustering sono responsabili del trasferimento delle risorse nell'altro nodo.
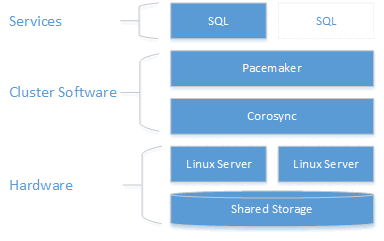
L'integrazione di SQL Server con Pacemaker in Linux non è associata come con il cluster WSFC in Windows. SQL Server non ha alcuna conoscenza della presenza del cluster. Tutte le orchestrazioni si trovano all'esterno e il servizio è controllato come istanza autonoma da Pacemaker. Inoltre, il nome della rete virtuale è specifico di WSFC e non esiste un equivalente in Pacemaker. È previsto che @@SERVERNAME e sys.servers restituiscano il nome del nodo, mentre le sys.dm_os_cluster_nodes e sys.dm_os_cluster_properties DMV del cluster non restituiscono record. Per usare una stringa di connessione che punta a un nome del server in formato stringa e non usare l'indirizzo IP, devono registrare nel server DNS l'IP usato per creare la risorsa IP virtuale (come illustrato nelle sezioni seguenti) con il nome del server scelto.
Numero di istanze e nodi
Una differenza fondamentale con SQL Server in Linux è data dalla presenza di una sola installazione di SQL Server per ogni server Linux. Tale installazione viene chiamata istanza. A differenza di Windows Server, che supporta fino a 25 istanze per ogni cluster di failover di Windows Server (WSFC), un FCI basato su Linux avrà solo un'istanza. Questa singola istanza è anche un'istanza predefinita. In Linux non esiste il concetto di istanza denominata.
Un cluster Pacemaker può avere solo fino a 16 nodi quando è coinvolto Corosync, quindi un singolo FCI può coprire un massimo di 16 server. Un'FCI implementata con SQL Server Standard Edition supporta fino a due nodi di un cluster, anche se il cluster Pacemaker consente un massimo di 16 nodi.
In una istanza FCI di SQL Server, l'istanza di SQL Server è attiva su uno dei due nodi.
Indirizzo IP e nome
In un cluster Pacemaker di Linux, ogni FCI di SQL Server necessita di un indirizzo IP e di un nome univoco. Se la configurazione dell'istanza FCI si estende su più sottoreti, è necessario un indirizzo IP per ogni sottorete. Il nome e gli indirizzi IP univoci vengono usati per accedere all'istanza del cluster di failover (FCI), evitando che le applicazioni e gli utenti finali debbano conoscere uno dei server sottostanti del cluster Pacemaker.
Il nome della FCI in DNS deve essere lo stesso del nome della risorsa FCI che viene creata nel cluster Pacemaker. Sia il nome che l'indirizzo IP devono essere registrati in DNS.
Archiviazione condivisa
Tutte le istanze del cluster di failover, che si trovino in Linux o in Windows Server, richiedono una forma di storage condiviso. Questa risorsa di archiviazione viene presentata a tutti i server che possono ospitare l'istanza del cluster di failover, ma, in un determinato momento, solo un server può usare lo spazio di archiviazione per l'istanza del cluster di failover. Le opzioni disponibili per l'archiviazione condivisa in Linux sono:
- iSCSI
- File system di rete (NFS)
- Protocollo SMB (Server Message Block)
In Windows Server sono disponibili opzioni leggermente diverse. Un'opzione attualmente non supportata per le istanze del cluster di failover basate su Linux è la possibilità di usare un disco locale per il nodo di tempdb, che è l'area di lavoro temporanea di SQL Server.
In una configurazione che si estende su più posizioni, ciò che viene archiviato in un data center deve essere sincronizzato con l'altro. In caso di failover, il FCI riesce a tornare online e lo spazio di archiviazione appare invariato. A questo scopo, è necessario un metodo esterno per la replica di archiviazione, indipendentemente dal fatto che venga eseguita tramite l'hardware di archiviazione sottostante o un'utilità basata su software.
Nota
Per SQL Server, le distribuzioni basate su Linux che usano dischi presentati direttamente a un server devono essere formattate con XFS o ext4. Gli altri file system attualmente non sono supportati. Eventuali modifiche verranno indicate qui.
Il processo di presentazione della risorsa di archiviazione condivisa è lo stesso per i diversi metodi supportati:
- Configurare la risorsa di archiviazione condivisa
- Montare lo storage come cartella nei server che fungeranno da nodi del cluster Pacemaker per il FCI
- Se necessario, spostare i database di sistema SQL Server nella risorsa di archiviazione condivisa
- Verificare che SQL Server funzioni da ogni server connesso alla risorsa di archiviazione condivisa
Una delle principali differenze con SQL Server in Linux è che, nonostante sia possibile configurare il percorso predefinito dei file di log e dei dati dell'utente, i database di sistema devono sempre essere presenti in /var/opt/mssql/data. In Windows Server, è possibile spostare i database di sistema, incluso tempdb. Ciò influisce sul modo in cui viene configurata l'archiviazione condivisa per una FCI.
I percorsi predefiniti per i database non di sistema possono essere modificati usando l'utilità mssql-conf. Per informazioni su come modificare le impostazione predefinite, vedere Modificare il percorso predefinito della directory dei dati o dei log. È anche possibile archiviare la transazione e i dati di SQL Server in altre posizioni, purché la sicurezza sia appropriata anche se non si tratta di un percorso predefinito. Il percorso deve essere dichiarato.