Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server in Linux
SQL Server in Linux
Questo documento descrive come eseguire le attività seguenti per SQL Server in un cluster di failover di dischi condivisi con Red Hat Enterprise Linux.
- Effettuare il failover manuale del cluster
- Monitorare un servizio SQL Server del cluster di failover
- Aggiungere un nodo del cluster
- Rimuovere un nodo del cluster
- Modificare la frequenza di monitoraggio delle risorse di SQL Server
Descrizione dell'architettura
Il livello di clustering si basa sul componente aggiuntivo a disponibilità elevata di Red Hat Enterprise Linux (RHEL), basato a sua volta su Pacemaker. Corosync e Pacemaker coordinano le comunicazioni del cluster e la gestione delle risorse. L'istanza di SQL Server è attiva in un nodo o nell'altro.
Il diagramma seguente illustra i componenti in un cluster Linux con SQL Server.
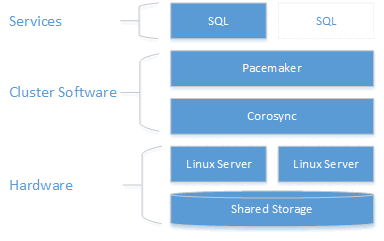
Per altre informazioni sulla configurazione del cluster, sulle opzioni degli agenti delle risorse e sulla gestione, vedere la documentazione di riferimento di RHEL.
Effettuare il failover manuale del cluster
Il comando resource move crea un vincolo che forza l'avvio della risorsa nel nodo di destinazione. Dopo l'esecuzione del comando move, l'esecuzione di clear per la risorsa rimuoverà il vincolo e sarà possibile spostare nuovamente la risorsa o effettuare il failover automatico della risorsa.
sudo pcs resource move <sqlResourceName> <targetNodeName>
sudo pcs resource clear <sqlResourceName>
L'esempio seguente sposta la risorsa mssqlha in un nodo denominato sqlfcivm2 e quindi rimuove il vincolo in modo che la risorsa possa passare in un nodo diverso in un secondo momento.
sudo pcs resource move mssqlha sqlfcivm2
sudo pcs resource clear mssqlha
Monitorare un servizio SQL Server del cluster di failover
Visualizzare lo stato corrente del cluster:
sudo pcs status
Visualizzare lo stato in tempo reale del cluster e delle risorse:
sudo crm_mon
Visualizza il log degli agenti delle risorse in /var/log/cluster/corosync.log
Aggiungere un nodo a un cluster
Controllare l'indirizzo IP per ogni nodo. Lo script seguente mostra l'indirizzo IP del nodo corrente.
ip addr showIl nuovo nodo deve avere un nome univoco di 15 caratteri o meno. Per impostazione predefinita, in Red Hat Linux il nome computer è
localhost.localdomain. Questo nome predefinito potrebbe non essere univoco ed è troppo lungo. Imposta il nome del computer per il nuovo nodo. Imposta il nome del computer aggiungilo a/etc/hosts. Lo script seguente consente di modificare/etc/hostsconvi.sudo vi /etc/hostsL'esempio seguente mostra
/etc/hostscon aggiunte per tre nodi denominatisqlfcivm1,sqlfcivm2esqlfcivm3.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 fcivm1 10.128.16.77 fcivm2 10.128.14.26 fcivm3Il file deve essere lo stesso in ogni nodo.
Arrestare il servizio SQL Server nel nuovo nodo.
Seguire le istruzioni per montare la directory del file di database nel percorso condiviso:
Dal server NFS, installare
nfs-utils:sudo yum -y install nfs-utilsAprire il firewall nei client e nel server NFS:
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadModificare il file
/etc/fstabper includere il comando mount:<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrEseguire
mount -aper rendere effettive le modifiche.Nel nuovo nodo creare un file per archiviare nome utente e password di SQL Server per l'accesso a Pacemaker. Il comando seguente crea e popola questo file:
sudo touch /var/opt/mssql/passwd sudo echo "<loginName>" >> /var/opt/mssql/secrets/passwd sudo echo "<password>" >> /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/passwd sudo chmod 600 /var/opt/mssql/passwdAttenzione
La password deve seguire i criteri password predefiniti di SQL Server. Per impostazione predefinita, la password deve essere composta da almeno otto caratteri e contenere caratteri di tre delle quattro categorie seguenti: lettere maiuscole, lettere minuscole, cifre in base 10 e simboli. Le password possono contenere fino a 128 caratteri. Usare password il più possibile lunghe e complesse.
Nel nuovo nodo aprire le porte del firewall di Pacemaker. Per aprire queste porte con
firewalld, eseguire il comando seguente:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadSe si sta usando un altro firewall che non ha una configurazione a disponibilità elevata predefinita, è necessario aprire le porte seguenti per consentire a Pacemaker di comunicare con altri nodi del cluster
- TCP: porte 2224, 3121, 21064
- UDP: porta 5405
Installare i pacchetti Pacemaker nel nuovo nodo.
sudo yum install pacemaker pcs fence-agents-all resource-agentsImpostare la password per l'utente predefinito creato durante l'installazione dei pacchetti Pacemaker e Corosync. Usare la stessa password dei nodi esistenti.
sudo passwd haclusterAbilitare e avviare il servizio
pcsde Pacemaker. In questo modo, il nuovo nodo potrà nuovamente unirsi al cluster dopo il riavvio. Eseguire il comando seguente nel nuovo nodo.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstallare l'agente delle risorse FCI per SQL Server. Eseguire i comandi seguenti nel nuovo nodo.
sudo yum install mssql-server-haIn un nodo esistente del cluster autenticare il nuovo nodo e aggiungerlo al cluster:
sudo pcs cluster auth <nodeName3> -u hacluster sudo pcs cluster node add <nodeName3>L'esempio seguente aggiunge un nodo denominato vm3 al cluster.
sudo pcs cluster auth sudo pcs cluster start
Rimuovere i nodi da un cluster
Per rimuovere un nodo da un cluster, eseguire il comando seguente:
sudo pcs cluster node remove <nodeName>
Modificare la frequenza dell'intervallo di monitoraggio della risorsa sqlservr
sudo pcs resource op monitor interval=<interval>s <sqlResourceName>
L'esempio seguente imposta l'intervallo di monitoraggio su 2 secondi per la risorsa mssql:
sudo pcs resource op monitor interval=2s mssqlha
Risolvere i problemi del cluster di dischi condivisi Red Hat Enterprise Linux per SQL Server
Nella risoluzione dei problemi del cluster, può essere utile conoscere il modo in cui i tre daemon interagiscono per gestire le risorse cluster.
| Daemon | Descrizione |
|---|---|
| Corosync | Fornisce l'appartenenza al quorum e la messaggistica tra i nodi del cluster. |
| Stimolatore cardiaco | Funziona sopra Corosync e fornisce le macchine a stati per le risorse. |
| PCSD | Gestisce sia Pacemaker che Corosync tramite gli strumenti pcs |
Per usare gli strumenti pcs, è necessario che PCSD sia in esecuzione.
Stato corrente del cluster
sudo pcs status restituisce le informazioni di base sullo stato di cluster, quorum, nodi, risorse e daemon per ogni nodo.
Un esempio di output del quorum di Pacemaker integro è:
Cluster name: MyAppSQL
Last updated: Wed Oct 31 12:00:00 2016 Last change: Wed Oct 31 11:00:00 2016 by root via crm_resource on sqlvmnode1
Stack: corosync
Current DC: sqlvmnode1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
3 nodes and 1 resource configured
Online: [ sqlvmnode1 sqlvmnode2 sqlvmnode3 ]
Full list of resources:
mssqlha (ocf::sql:fci): Started sqlvmnode1
PCSD Status:
sqlvmnode1: Online
sqlvmnode2: Online
sqlvmnode3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
Nell'esempio, partition with quorum indica che un quorum di maggioranza dei nodi è online. Se il cluster perde un quorum di maggioranza dei nodi, pcs status restituisce partition WITHOUT quorum e tutte le risorse vengono arrestate.
online: [sqlvmnode1 sqlvmnode2 sqlvmnode3] restituisce il nome di tutti i nodi che attualmente partecipano al cluster. Se un nodo non partecipa, pcs status restituisce OFFLINE: [<nodename>].
PCSD Status mostra lo stato del cluster per ogni nodo.
Motivi per cui un nodo potrebbe essere offline
Quando un nodo è offline, controllare gli elementi seguenti.
Firewall
Le porte seguenti devono essere aperte in tutti i nodi perché Pacemaker riesca a comunicare.
- **TCP: 2224, 3121, 21064
Servizi Pacemaker o Corosync in esecuzione
Comunicazione tra nodi
Mappatura dei nomi dei nodi