Esercitazione Python: Creare un modello per classificare i clienti con il Machine Learning in SQL
Si applica a: ![]() SQL Server 2017 (14.x) e versioni successive
SQL Server 2017 (14.x) e versioni successive ![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure
Nella terza parte di questa serie di esercitazioni in quattro parti verrà compilato un modello K-Means in Python per eseguire il clustering. Nella parte successiva della serie questo modello verrà distribuito in un database con Machine Learning Services per SQL Server oppure in cluster Big Data.
Nella terza parte di questa serie di esercitazioni in quattro parti verrà compilato un modello K-Means in Python per eseguire il clustering. Nella parte successiva della serie questo modello verrà distribuito in un database con Machine Learning Services per SQL Server.
Nella terza parte di questa serie di esercitazioni in quattro parti verrà compilato un modello K-Means in Python per eseguire il clustering. Nella parte successiva di questa serie questo modello verrà distribuito in un database con Machine Learning Services per Istanza gestita di SQL di Azure.
In questo articolo si apprenderà come:
- Definire il numero di cluster per un algoritmo K-Means
- Eseguire il clustering
- Analizzare i risultati
Nella prima parte sono stati installati i prerequisiti ed è stato ripristinato il database di esempio.
Nella seconda parte si è appreso come preparare i dati di un database per il clustering.
Nella quarta parte si apprenderà come creare una stored procedure in un database in grado di eseguire il clustering in Python in base ai nuovi dati.
Prerequisiti
- Nella terza parte di questa esercitazione si presuppone che siano stati soddisfatti i prerequisiti della prima parte e che siano stati completati i passaggi descritti nella seconda parte.
Definire il numero di cluster
Per raggruppare i dati dei clienti si userà l'algoritmo di clustering K-Means, una delle modalità di raggruppamento dei dati più semplici e note. Per altre informazioni su K-Means, vedere la guida completa all'algoritmo di clustering K-Means.
L’algoritmo accetta due input: i dati stessi e un numero predefinito "k" che rappresenta il numero di cluster da generare. L'output è k cluster con i dati di input partizionati tra i cluster.
L'obiettivo di K-Means consiste nel raggruppare gli elementi in k cluster in modo che tutti gli elementi nello stesso cluster siano simili tra loro e siano il più diversi possibile dagli elementi di altri cluster.
Per determinare il numero di cluster che l'algoritmo deve usare, usare un tracciato della media della somma dei quadrati all'interno dei gruppi, per numero di cluster estratti. Il numero appropriato di cluster da usare è quello in corrispondenza della curva o del "gomito" del tracciato.
################################################################################################
## Determine number of clusters using the Elbow method
################################################################################################
cdata = customer_data
K = range(1, 20)
KM = (sk_cluster.KMeans(n_clusters=k).fit(cdata) for k in K)
centroids = (k.cluster_centers_ for k in KM)
D_k = (sci_distance.cdist(cdata, cent, 'euclidean') for cent in centroids)
dist = (np.min(D, axis=1) for D in D_k)
avgWithinSS = [sum(d) / cdata.shape[0] for d in dist]
plt.plot(K, avgWithinSS, 'b*-')
plt.grid(True)
plt.xlabel('Number of clusters')
plt.ylabel('Average within-cluster sum of squares')
plt.title('Elbow for KMeans clustering')
plt.show()
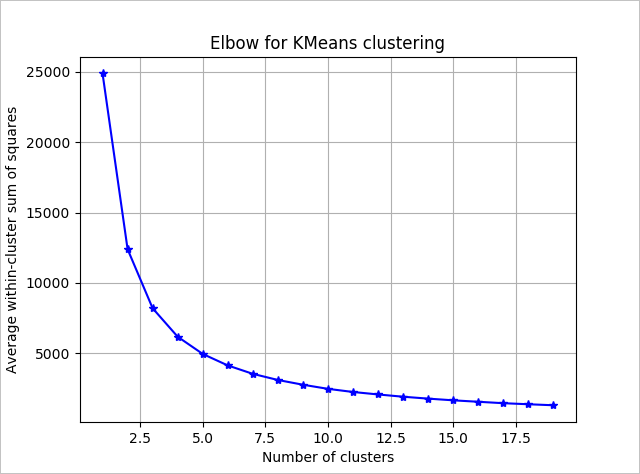
In base al grafico, k = 4 sembrerebbe un buon valore da provare. Questo valore di k raggruppa i clienti in quattro cluster.
Eseguire il clustering
Nello script Python seguente si userà la funzione KMeans del pacchetto sklearn.
################################################################################################
## Perform clustering using Kmeans
################################################################################################
# It looks like k=4 is a good number to use based on the elbow graph.
n_clusters = 4
means_cluster = sk_cluster.KMeans(n_clusters=n_clusters, random_state=111)
columns = ["orderRatio", "itemsRatio", "monetaryRatio", "frequency"]
est = means_cluster.fit(customer_data[columns])
clusters = est.labels_
customer_data['cluster'] = clusters
# Print some data about the clusters:
# For each cluster, count the members.
for c in range(n_clusters):
cluster_members=customer_data[customer_data['cluster'] == c][:]
print('Cluster{}(n={}):'.format(c, len(cluster_members)))
print('-'* 17)
print(customer_data.groupby(['cluster']).mean())
Analizzare i risultati
Una volta eseguito il clustering con K-Means, il passaggio successivo consiste nell'analizzare il risultato e verificare se è possibile trovare informazioni di utilità pratica.
Esaminare i valori medi per il clustering e le dimensioni dei cluster visualizzati nello script precedente.
Cluster0(n=31675):
-------------------
Cluster1(n=4989):
-------------------
Cluster2(n=1):
-------------------
Cluster3(n=671):
-------------------
customer orderRatio itemsRatio monetaryRatio frequency
cluster
0 50854.809882 0.000000 0.000000 0.000000 0.000000
1 51332.535779 0.721604 0.453365 0.307721 1.097815
2 57044.000000 1.000000 2.000000 108.719154 1.000000
3 48516.023845 0.136277 0.078346 0.044497 4.271237
Le medie dei quattro cluster si ottengono usando le variabili definite nella parte uno:
- orderRatio = rapporto ordini di reso (numero totale di ordini parzialmente o completamente resi rispetto al numero totale di ordini)
- itemsRatio = rapporto articoli resi (numero totale di articoli resi rispetto al numero di articoli acquistati)
- monetaryRatio = rapporto importi resi (importo monetario totale di articoli resi rispetto all'importo di articoli acquistati)
- frequency = frequenza dei resi
Il data mining con K-Means spesso richiede un'ulteriore analisi dei risultati e ulteriori passaggi per comprendere meglio ogni cluster, ma può fornire alcune indicazioni valide. Ecco alcuni modi in cui possono essere interpretati i risultati:
- Il cluster 0 sembra essere un gruppo di clienti non attivi (tutti i valori sono pari a zero).
- Il cluster 3 sembra essere un gruppo che si distingue per il comportamento relativo ai resi.
Il cluster 0 è un gruppo di clienti che non sono chiaramente attivi. Forse si potrebbero indirizzare le iniziative di marketing verso questo gruppo per suscitare un interesse per gli acquisti. Nel passaggio successivo si eseguirà una query sul database per ottenere gli indirizzi di posta elettronica dei clienti del cluster 0, in modo da poter inviare loro un messaggio di posta elettronica di marketing.
Pulire le risorse
Se non si intende continuare con questa esercitazione, eliminare il database tpcxbb_1gb.
Passaggi successivi
Nella terza parte di questa serie di esercitazioni sono stati completati i passaggi seguenti:
- Definire il numero di cluster per un algoritmo K-Means
- Eseguire il clustering
- Analizzare i risultati
Per distribuire il modello di Machine Learning creato, seguire la quarta parte di questa serie di esercitazioni:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per