Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server 2017 (14.x) e versioni successive
SQL Server 2017 (14.x) e versioni successive
Questo articolo descrive l'estensione Python per l'esecuzione di script Python esterni con Machine Learning Services per SQL Server. L'estensione aggiunge:
- Ambiente di esecuzione Python
- Distribuzione Anaconda con il runtime e l'interprete Python 3.5
- Librerie e strumenti standard
- Pacchetti Python Microsoft:
- revoscalepy per l'analisi su larga scala.
- microsoftml per gli algoritmi di Machine Learning.
L'installazione del runtime e dell'interprete Python 3.5 garantisce la compatibilità quasi completa con le soluzioni Python standard. Python viene eseguito in un processo separato da SQL Server, per garantire che le operazioni di database non vengano compromesse.
Componenti Python
SQL Server include pacchetti sia open source che proprietari. Il runtime Python installato dal programma di installazione è Anaconda 4.2 con Python 3.5. Il runtime Python viene installato indipendentemente dagli strumenti SQL e viene eseguito all'esterno dei processi del motore di base, nel framework di estendibilità. Nell'ambito dell'installazione di Machine Learning Services con Python, è necessario accettare i termini della licenza GNU Public License.
SQL Server non modifica i file eseguibili Python, ma è necessario usare la versione di Python installata dal programma di installazione perché è quella su cui vengono compilati e testati i pacchetti proprietari. Per un elenco dei pacchetti supportati dalla distribuzione Anaconda, vedere il sito di analisi Continuum: Elenco dei pacchetti Anaconda.
La distribuzione Anaconda associata a una specifica istanza del motore di database è disponibile nella cartella associata all'istanza. Se, ad esempio, è stato installato il motore di database SQL Server 2017 con Machine Learning Services e Python nell'istanza predefinita, cercare in C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES.
I pacchetti Python aggiunti da Microsoft per i carichi di lavoro paralleli e distribuiti includono le librerie elencate di seguito.
| Libreria | Descrizione |
|---|---|
| revoscalepy | Supporta gli oggetti origine dati e anche l'esplorazione, la manipolazione, la trasformazione e la visualizzazione dei dati. Supporta inoltre la creazione di contesti di calcolo remoti e diversi modelli di Machine Learning scalabili, ad esempio rxLinMod. Per altre informazioni, vedere Modulo revoscalepy con SQL Server. |
| microsoftml | Contiene gli algoritmi di Machine Learning ottimizzati per la velocità e l'accuratezza, nonché le trasformazioni inline per l'utilizzo di testo e immagini. Per altre informazioni, vedere Modulo microsoftml con SQL Server. |
Microsoftml e revoscalepy sono strettamente collegati. Le origini dati usate in microsoftml sono definite come oggetti revoscalepy. Le limitazioni del contesto di calcolo in revoscalepy vengono trasferite a microsoftml. In particolare, tutte le funzionalità sono disponibili per le operazioni locali, ma per passare a un contesto di calcolo remoto è necessario RxInSqlServer.
Uso di Python in SQL Server
Si importa il modulo revoscalepy nel codice Python e quindi si chiamano le funzioni dal modulo, come qualsiasi altra funzione Python.
Le origini dati supportate includono i database ODBC, SQL Server e il formato di file XDF per lo scambio di dati con altre origini o con soluzioni R. I dati di input per Python devono essere in formato tabulare. Tutti i risultati di Python devono essere restituiti sotto forma di un dataframe pandas.
I contesti di calcolo supportati includono il contesto di calcolo di SQL Server, locale o remoto. Un contesto di calcolo remoto fa riferimento all'esecuzione del codice avviata in un computer, ad esempio una workstation, per poi passare l'esecuzione dello script a un computer remoto. Per cambiare il contesto di calcolo è necessario che entrambi i sistemi abbiano la stessa libreria revoscalepy.
Il contesto di calcolo locale, come si può prevedere, include l'esecuzione del codice Python sullo stesso server dell'istanza del motore di database, con il codice all'interno di T-SQL o incorporato in una stored procedure. È anche possibile eseguire il codice da un IDE di Python locale e far eseguire lo script nel computer SQL Server, definendo un contesto di calcolo remoto.
Architettura di esecuzione
I diagrammi seguenti illustrano l'interazione dei componenti di SQL Server con il runtime Python in ognuno degli scenari supportati: esecuzione di script nel database ed esecuzione remota da una riga di comando Python, usando un contesto di calcolo di SQL Server.
Script Python eseguiti nel database
Quando si esegue il codice Python "all'interno" di SQL Server, è necessario incapsulare lo script Python in una stored procedure speciale, sp_execute_external_script.
Dopo che lo script è stato incorporato nella stored procedure, qualsiasi applicazione che può eseguire una chiamata alla stored procedure può avviare l'esecuzione del codice Python. Successivamente, SQL Server gestisce l'esecuzione del codice, come riepilogato nel diagramma seguente.
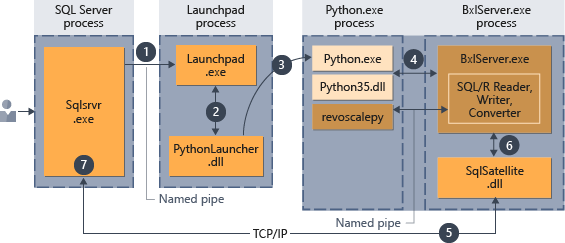
- Una richiesta per il runtime Python è indicata dal parametro
@language='Python'passato alla stored procedure. SQL Server invia la richiesta al servizio launchpad. In Linux, SQL usa un servizio launchpadd per comunicare con un processo launchpad separato per ogni utente. Per informazioni dettagliate, vedere il diagramma dell'architettura di estendibilità. - Il servizio launchpad avvia l'utilità di avvio appropriata, in questo caso PythonLauncher.
- PythonLauncher avvia il processo Python35 esterno.
- BxlServer si coordina con il runtime Python per gestire gli scambi di dati e l'archiviazione dei risultati.
- SQL Satellite gestisce le comunicazioni relative ad attività e processi correlati con SQL Server.
- BxlServer usa SQL Satellite per comunicare lo stato e i risultati a SQL Server.
- SQL Server ottiene i risultati e chiude le attività e i processi correlati.
Gli script Python eseguiti da un client remoto
È possibile eseguire script Python da un computer remoto, ad esempio un portatile, e fare in modo che vengano eseguiti nel contesto del computer con SQL Server, se sono soddisfatte le condizioni seguenti:
- Progettare gli script in modo appropriato
- Nel computer remoto sono installate le librerie di estendibilità usate da Machine Learning Services. Per usare i contesti di calcolo remoti è necessario il pacchetto revoscalepy.
Nel diagramma seguente è riportato un riepilogo del flusso di lavoro complessivo quando gli script vengono inviati da un computer remoto.
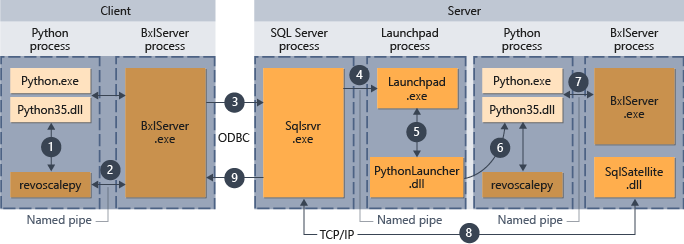
- Per le funzioni supportate in revoscalepy, il runtime Python chiama una funzione di collegamento, che a sua volta chiama BxlServer.
- BxlServer è incluso in Machine Learning Services (In-Database) e viene eseguito in un processo separato dal runtime Python.
- BxlServer determina la destinazione della connessione e avvia una connessione tramite ODBC, passando le credenziali fornite come parte della stringa di connessione nello script Python.
- BxlServer apre una connessione all'istanza di SQL Server.
- Quando viene chiamato un runtime di script esterno, viene richiamato il servizio launchpad, che a sua volta avvia l'utilità di avvio appropriata, in questo caso PythonLauncher.dll. Successivamente, l'elaborazione del codice Python viene gestita in un flusso di lavoro simile a quando il codice Python viene richiamato da una stored procedure in T-SQL.
- PythonLauncher effettua una chiamata all'istanza di Python installata nel computer SQL Server.
- I risultati vengono restituiti a BxlServer.
- SQL Satellite gestisce la gestione delle comunicazioni con SQL Server e la ripulitura degli oggetti processo correlati.
- SQL Server passa i risultati al client.