Esercitazione: Creare un modello di clustering in R con Machine Learning in SQL
Si applica a: ![]() SQL Server 2016 (13.x) e versioni successive
SQL Server 2016 (13.x) e versioni successive ![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure
Nella terza parte di questa serie di esercitazioni in quattro parti si creerà un modello K-Means in R per eseguire il clustering. Nella parte successiva della serie questo modello verrà distribuito in un database con Machine Learning Services per SQL Server oppure in cluster Big Data.
Nella terza parte di questa serie di esercitazioni in quattro parti si creerà un modello K-Means in R per eseguire il clustering. Nella parte successiva della serie questo modello verrà distribuito in un database con Machine Learning Services per SQL Server.
Nella terza parte di questa serie di esercitazioni in quattro parti si creerà un modello K-Means in R per eseguire il clustering. Nella parte successiva della serie questo modello verrà distribuito in un database con R Services per SQL Server.
Nella terza parte di questa serie di esercitazioni in quattro parti si creerà un modello K-Means in R per eseguire il clustering. Nella parte successiva di questa serie questo modello verrà distribuito in un database con Machine Learning Services per Istanza gestita di SQL di Azure.
In questo articolo si apprenderà come:
- Definire il numero di cluster per un algoritmo K-Means
- Eseguire il clustering
- Analizzare i risultati
Nella prima parte sono stati installati i prerequisiti ed è stato ripristinato il database di esempio.
Nella seconda parte si è appreso come preparare i dati di un database per il clustering.
Nella quarta parte si apprenderà come creare una stored procedure in un database in grado di eseguire il clustering in R in base ai nuovi dati.
Prerequisiti
- Nella terza parte di questa serie di esercitazioni si presuppone che siano stati soddisfatti i prerequisiti della prima parte e che siano stati completati i passaggi descritti nella seconda parte.
Definire il numero di cluster
Per raggruppare i dati dei clienti si userà l'algoritmo di clustering K-Means, una delle modalità di raggruppamento dei dati più semplici e note. Per altre informazioni su K-Means, vedere la guida completa all'algoritmo di clustering K-Means.
L’algoritmo accetta due input: i dati stessi e un numero predefinito "k" che rappresenta il numero di cluster da generare. L'output è k cluster con i dati di input partizionati tra i cluster.
Per determinare il numero di cluster che l'algoritmo deve usare, usare un tracciato della media della somma dei quadrati all'interno dei gruppi, per numero di cluster estratti. Il numero appropriato di cluster da usare è quello in corrispondenza della curva o del "gomito" del tracciato.
# Determine number of clusters by using a plot of the within groups sum of squares,
# by number of clusters extracted.
wss <- (nrow(customer_data) - 1) * sum(apply(customer_data, 2, var))
for (i in 2:20)
wss[i] <- sum(kmeans(customer_data, centers = i)$withinss)
plot(1:20, wss, type = "b", xlab = "Number of Clusters", ylab = "Within groups sum of squares")
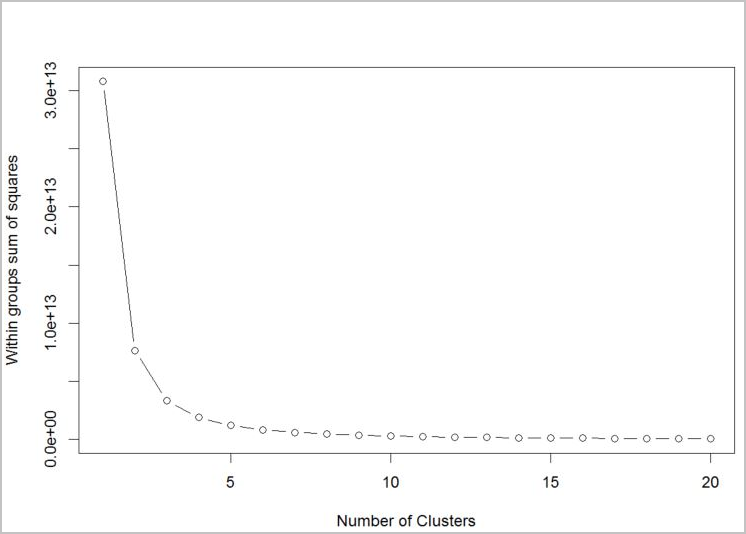
In base al grafico, k = 4 sembrerebbe un buon valore da provare. Questo valore di k raggruppa i clienti in quattro cluster.
Eseguire il clustering
Nello script R seguente si userà la funzione kmeans per eseguire il clustering.
# Output table to hold the customer group mappings.
# Generate clusters using Kmeans and output key / cluster to a table
# called return_cluster
## create clustering model
clust <- kmeans(customer_data[,2:5],4)
## create clustering ouput for table
customer_cluster <- data.frame(cluster=clust$cluster,customer=customer_data$customer,orderRatio=customer_data$orderRatio,
itemsRatio=customer_data$itemsRatio,monetaryRatio=customer_data$monetaryRatio,frequency=customer_data$frequency)
## write cluster output to DB table
sqlSave(ch, customer_cluster, tablename = "return_cluster")
# Read the customer returns cluster table from the database
customer_cluster_check <- sqlFetch(ch, "return_cluster")
head(customer_cluster_check)
Analizzare i risultati
A questo punto, dopo aver eseguito il clustering con K-means, il passaggio successivo consiste nell'analizzare il risultato e verificare se le informazioni sono utili dal punto di vista pratico.
#Look at the clustering details to analyze results
clust[-1]
$centers
orderRatio itemsRatio monetaryRatio frequency
1 0.621835791 0.1701519 0.35510836 1.009025
2 0.074074074 0.0000000 0.05886575 2.363248
3 0.004807692 0.0000000 0.04618708 5.050481
4 0.000000000 0.0000000 0.00000000 0.000000
$totss
[1] 40191.83
$withinss
[1] 19867.791 215.714 660.784 0.000
$tot.withinss
[1] 20744.29
$betweenss
[1] 19447.54
$size
[1] 4543 702 416 31675
$iter
[1] 3
$ifault
[1] 0
Le medie dei quattro cluster vengono ottenute usando le variabili definite nella seconda parte:
- orderRatio = rapporto ordini di reso (numero totale di ordini parzialmente o completamente resi rispetto al numero totale di ordini)
- itemsRatio = rapporto articoli resi (numero totale di articoli resi rispetto al numero di articoli acquistati)
- monetaryRatio = rapporto importi resi (importo monetario totale di articoli resi rispetto all'importo di articoli acquistati)
- frequency = frequenza dei resi
Il data mining con K-Means spesso richiede un'ulteriore analisi dei risultati e ulteriori passaggi per comprendere meglio ogni cluster, ma può fornire alcune indicazioni valide. Ecco alcuni modi in cui possono essere interpretati i risultati:
- Il cluster 1 (quello più grande) sembra corrispondere a un gruppo di clienti che non sono attivi (tutti i valori sono pari a zero).
- Il cluster 3 sembra essere un gruppo che si distingue per il comportamento relativo ai resi.
Pulire le risorse
Se non si intende continuare con questa esercitazione, eliminare il database tpcxbb_1gb.
Passaggi successivi
Nella terza parte di questa serie di esercitazioni si è appreso come:
- Definire il numero di cluster per un algoritmo K-Means
- Eseguire il clustering
- Analizzare i risultati
Per distribuire il modello di Machine Learning creato, seguire la quarta parte di questa serie di esercitazioni:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per