Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server 2016 (13.x) e versioni
SQL Server 2016 (13.x) e versioni ![]() successive di Istanza gestita di SQL di Azure
successive di Istanza gestita di SQL di Azure
Nella terza parte di questa serie di esercitazioni in quattro parti si eseguirà il training di un modello predittivo in R. Nella parte successiva di questa serie questo modello verrà distribuito in un database di SQL Server con Machine Learning Services oppure in cluster Big Data.
Nella terza parte di questa serie di esercitazioni in quattro parti si eseguirà il training di un modello predittivo in R. Nella parte successiva di questa serie questo modello verrà distribuito in un database di SQL Server con Machine Learning Services.
Nella terza parte di questa serie di esercitazioni in quattro parti si eseguirà il training di un modello predittivo in R. Nella parte successiva di questa serie questo modello verrà distribuito in un database con R Services per SQL Server.
Nella terza parte di questa serie di esercitazioni in quattro parti si eseguirà il training di un modello predittivo in R. Nella parte successiva di questa serie il modello verrà distribuito in un database di Istanza gestita di SQL di Azure con Machine Learning Services.
In questo articolo si apprenderà come:
- Eseguire il training di due modelli di Machine Learning
- Eseguire stime da entrambi i modelli
- Confrontare i risultati per scegliere il modello più accurato
Nella prima parte si è appreso come ripristinare il database di esempio.
Nella seconda parte si è appreso come caricare i dati da un database in un frame di dati Python e preparare i dati in R.
Nella quarta parte si apprenderà come archiviare il modello in un database e quindi creare stored procedure dagli script Python sviluppati nelle parti due e tre. Le stored procedure verranno quindi eseguite sul server per eseguire stime basate sui nuovi dati.
Prerequisites
La terza parte di questa serie di esercitazioni presuppone che siano stati soddisfatti i prerequisiti della prima parte e che siano stati completati i passaggi nella seconda parte.
Eseguire il training di due modelli
Per trovare il modello migliore per i dati di noleggio di sci, creare due modelli diversi (regressione lineare e albero delle decisioni) e vedere quale esegue le stime nel modo più accurato. Si userà il frame di dati rentaldata creato nella prima parte di questa serie.
#First, split the dataset into two different sets:
# one for training the model and the other for validating it
train_data = rentaldata[rentaldata$Year < 2015,];
test_data = rentaldata[rentaldata$Year == 2015,];
#Use the RentalCount column to check the quality of the prediction against actual values
actual_counts <- test_data$RentalCount;
#Model 1: Use lm to create a linear regression model, trained with the training data set
model_lm <- lm(RentalCount ~ Month + Day + WeekDay + Snow + Holiday, data = train_data);
#Model 2: Use rpart to create a decision tree model, trained with the training data set
library(rpart);
model_rpart <- rpart(RentalCount ~ Month + Day + WeekDay + Snow + Holiday, data = train_data);
Eseguire stime da entrambi i modelli
Usare una funzione di stima per stimare i conteggi dei noleggi con ogni modello con training.
#Use both models to make predictions using the test data set.
predict_lm <- predict(model_lm, test_data)
predict_lm <- data.frame(RentalCount_Pred = predict_lm, RentalCount = test_data$RentalCount,
Year = test_data$Year, Month = test_data$Month,
Day = test_data$Day, Weekday = test_data$WeekDay,
Snow = test_data$Snow, Holiday = test_data$Holiday)
predict_rpart <- predict(model_rpart, test_data)
predict_rpart <- data.frame(RentalCount_Pred = predict_rpart, RentalCount = test_data$RentalCount,
Year = test_data$Year, Month = test_data$Month,
Day = test_data$Day, Weekday = test_data$WeekDay,
Snow = test_data$Snow, Holiday = test_data$Holiday)
#To verify it worked, look at the top rows of the two prediction data sets.
head(predict_lm);
head(predict_rpart);
Il set di risultati è il seguente.
RentalCount_Pred RentalCount Month Day WeekDay Snow Holiday
1 27.45858 42 2 11 4 0 0
2 387.29344 360 3 29 1 0 0
3 16.37349 20 4 22 4 0 0
4 31.07058 42 3 6 6 0 0
5 463.97263 405 2 28 7 1 0
6 102.21695 38 1 12 2 1 0
RentalCount_Pred RentalCount Month Day WeekDay Snow Holiday
1 40.0000 42 2 11 4 0 0
2 332.5714 360 3 29 1 0 0
3 27.7500 20 4 22 4 0 0
4 34.2500 42 3 6 6 0 0
5 645.7059 405 2 28 7 1 0
6 40.0000 38 1 12 2 1 0
Confrontare i risultati
A questo punto si desidera vedere quale dei modelli offre le stime migliori. Un modo semplice e rapido per eseguire questa operazione è usare una funzione di tracciamento di base per visualizzare la differenza tra i valori effettivi nei dati di training e i valori stimati.
#Use the plotting functionality in R to visualize the results from the predictions
par(mfrow = c(1, 1));
plot(predict_lm$RentalCount_Pred - predict_lm$RentalCount, main = "Difference between actual and predicted. lm")
plot(predict_rpart$RentalCount_Pred - predict_rpart$RentalCount, main = "Difference between actual and predicted. rpart")
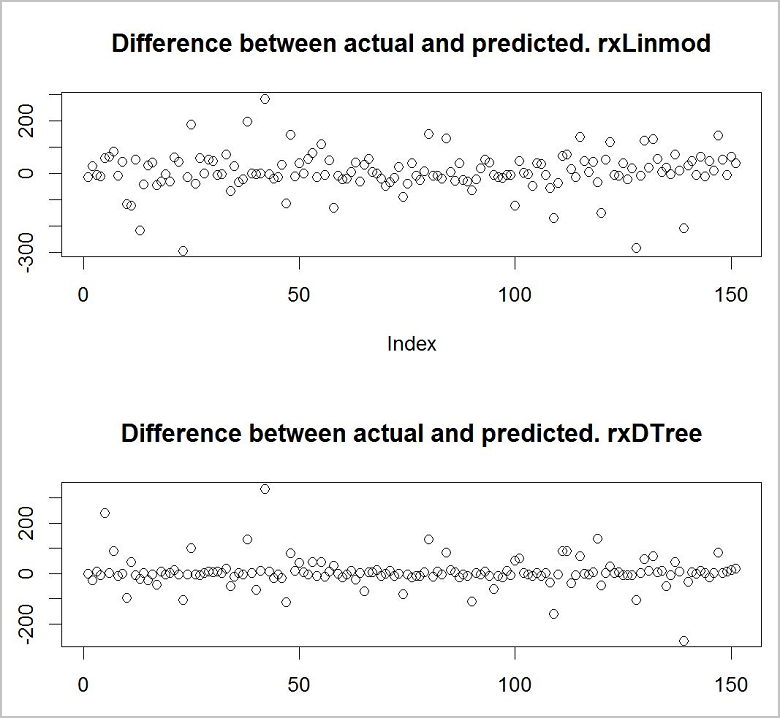
Sembra che il modello di albero delle decisioni sia il più accurato dei due modelli.
Pulire le risorse
Se non si intende continuare con questa esercitazione, eliminare il database TutorialDB.
Passaggi successivi
Nella terza parte di questa serie di esercitazioni si è appreso come:
- Eseguire il training di due modelli di Machine Learning
- Eseguire stime da entrambi i modelli
- Confrontare i risultati per scegliere il modello più accurato
Per distribuire il modello di Machine Learning creato, seguire la quarta parte di questa serie di esercitazioni: