Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
si applica a:![]() SQL Server - Solo Windows
SQL Server - Solo Windows
SQL Server offre supporto per il Servizio Copia Shadow del volume fornendo un writer (il writer SQL) che consente a un'applicazione di backup di terze parti di usare il framework Servizio Copia Shadow del volume per eseguire il backup dei file di database. Questo documento descrive il componente SQL writer e il ruolo che svolge nel processo di creazione e ripristino degli snapshot VSS per i database di SQL Server. Acquisisce anche informazioni dettagliate su come configurare e utilizzare il writer SQL per lavorare con le applicazioni di backup nel Volume Shadow Copy Service.
Infrastruttura del Servizio Copia Shadow del volume
Il VSS fornisce l'infrastruttura di sistema per l'esecuzione di applicazioni VSS nei sistemi Windows. Nonostante sia per lo più trasparente sia per l'utente che per lo sviluppatore, il Servizio Copia Shadow del Volume (VSS):
- Coordina le attività di fornitori, scrittori e richiedenti durante la creazione e l'uso di copie ombra.
- Fornisce il provider di sistema predefinito.
- Implementa le funzionalità dei driver di base necessarie per il funzionamento di qualsiasi provider.
Il servizio VSS viene avviato su richiesta, pertanto questo servizio deve essere abilitato per il corretto funzionamento delle operazioni vss.
Componenti VSS
Il Servizio Copia Shadow del volume coordina le attività dei componenti interoperativi seguenti:
I provider possiedono i dati delle copie istantanee e creano le istanze di queste copie.
I writer sono applicazioni che modificano i dati e partecipano al processo di sincronizzazione delle copie shadow.
I richiedenti avviano la creazione e la cancellazione delle copie shadow. La progettazione è incentrata sullo scenario in cui il richiedente è un'applicazione di backup.
VSS fornisce il coordinamento tra le seguenti parti:
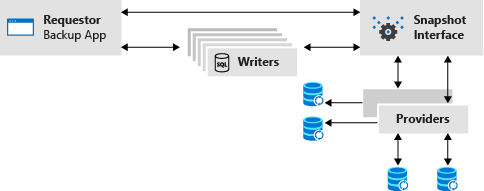
Questo diagramma mostra tutti i componenti che partecipano a una tipica attività di snapshot del VSS. In uno scenario di questo tipo SQL Server (incluso il writer SQL) funge da writer in una delle caselle Writer. Altri writer di questo tipo potrebbero essere Exchange Server e così via.
Interfaccia dispositivo virtuale: SQL Server fornisce un'interfaccia di programmazione delle applicazioni denominata VDI (Virtual Device Interface), che consente ai fornitori di software indipendenti di integrare SQL Server nei propri prodotti fornendo supporto per le operazioni di backup e ripristino. Queste API sono state progettate per offrire affidabilità e prestazioni ottimali e per supportare la gamma completa di funzionalità di backup e di ripristino di SQL Server, incluse tutte le capacità di backup a caldo e di snapshot. Per altre informazioni, vedere Specifica di SQL Server 2005 Virtual Backup Device Interface.
Richiedente: un processo (automatizzato o GUI) che richiede che uno o più set di snapshot vengano acquisiti da uno o più volumi originali. In questo articolo, il termine "richiedente" si riferisce anche a un'applicazione di backup che crea uno snapshot dei database di SQL Server.
Per ulteriori informazioni, vedere Servizio Copia Shadow del Volume.
Scrittore SQL
Il writer SQL è un writer VSS fornito dall'istanza di SQL Server. Gestisce l'interazione dei Servizi Copia Shadow del Volume (VSS) con SQL Server. Il writer SQL viene fornito con SQL Server come servizio autonomo e viene installato durante l'installazione di SQL Server.
Il ruolo del writer SQL in un'operazione di backup di snapshot del Volume Shadow Copy Service.
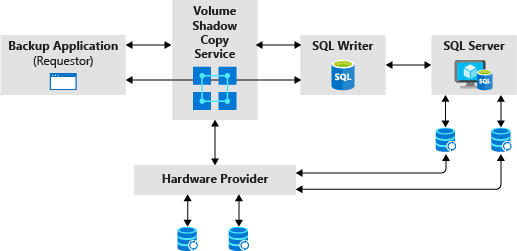
Configurare il writer SQL
Il servizio writer SQL viene installato nel sistema durante l'installazione di SQL Server ed è configurato per l'avvio automatico all'avvio di Windows.
Account del servizio di scrittore SQL
Durante l'installazione, l'account writer SQL è configurato per usare l'account di sistema locale. Poiché è necessario che il writer SQL comunichi con SQL Server usando API VDI esclusive, l'account del writer SQL deve avere diritti di accesso sufficienti sia per SQL Server che per VSS. La configurazione del servizio come account di sistema locale fornisce diritti sufficienti per la corretta esecuzione del servizio.
Importante
Assicurarsi che il servizio SQL Writer venga eseguito sotto l'account Local System e che l'account di SQL Server NT SERVICE\SQLWriter sia membro del ruolo sysadmin.
Riabilitare e avviare il writer SQL
Per impostazione predefinita, il servizio writer SQL è abilitato e viene avviato automaticamente. Se questa configurazione è stata modificata, è necessario eseguire i passaggi seguenti per ripristinare le impostazioni predefinite:
Il servizio writer SQL può essere abilitato contrassegnando questo servizio come Automatico. Per aprire i servizi tramite il pannello di controllo, selezionare Start, selezionare Pannello di controllo, fare doppio clic su Strumenti di amministrazione e quindi fare doppio clic su Servizi. Nel riquadro Servizi fare doppio clic sul servizio writer SQL e modificare la proprietà Tipo di avvio in Automatico.
Il servizio deve quindi essere avviato selezionando il pulsante Start nella proprietà Stato servizio nella schermata della proprietà del servizio indicata in precedenza.
Nota
In alcuni casi in cui è installata un'istanza di SQL Server Express e un'applicazione usa la funzionalità Istanze utente, il writer SQL potrebbe essere avviato automaticamente da SQL Server. Ciò viene effettuato per facilitare l'enumerazione di queste istanze utente durante un'operazione di backup tramite VSS.
Funzionalità supportate dal writer SQL
Full-text: Il writer SQL riporta contenitori di cataloghi full-text con specifiche di file ricorsive all'interno dei componenti del database nel documento di metadati del writer. Vengono inclusi automaticamente nel backup quando viene selezionato il componente del database.
Backup e ripristino differenziali: il writer SQL supporta il backup differenziale e il ripristino attraverso due meccanismi differenziali VSS.
File parziale: Il writer SQL utilizza il meccanismo VSS per file parziali per segnalare gli intervalli di byte modificati all'interno dei file di database.
Differenza del file in base all'ora dell'ultima modifica: Il meccanismo VSS Differenced File by Last Modify Time è utilizzato dal writer SQL per segnalare i file modificati nei cataloghi full-text.
Eseguire il ripristino con lo spostamento: il writer SQL supporta la specifica New Target di VSS durante il ripristino. La specifica Nuova destinazione consente di rilocare un file di database/log o un contenitore di catalogo full-text come parte dell'operazione di ripristino.
Ridenominazione del database: un richiedente potrebbe dover ripristinare un database di SQL Server con un nuovo nome, soprattutto se il database deve essere ripristinato side-by-side con il database originale. Il writer SQL supporta la ridenominazione di un database durante l'operazione di ripristino, purché il database rimanga all'interno dell'istanza di SQL originale.
Backup di sola copia: a volte è necessario eseguire un backup destinato a uno scopo speciale, ad esempio quando è necessario creare una copia di un database a scopo di test. Questo backup non deve influire sulle procedure generali di backup e ripristino per il database. L'uso dell'opzione
COPY_ONLYspecifica che il backup viene eseguito fuori banda e non deve influire sulla normale sequenza di backup. Il writer SQL supporta il tipo di backup di sola copia con le istanze di SQL Server.Salvataggio automatico dello snapshot del database: in genere uno snapshot di un database di SQL Server ottenuto tramite il framework VSS è in uno stato non ripristinato. I dati nello snapshot non possono essere acceduti in modo sicuro prima di attraversare la fase di ripristino per eseguire il rollback delle transazioni in corso e posizionare il database in uno stato coerente. È possibile che un'applicazione di backup VSS richieda il ripristino automatico degli snapshot, come parte del processo di creazione dello snapshot.
Queste nuove funzionalità e il relativo utilizzo sono descritte in modo più dettagliato in Dettagli opzione di backup e ripristino in questo articolo.
Cosa non è supportato
- Il backup del log non è supportato dal writer di SQL.
- Il backup di file e filegroup non è supportato.
- Il ripristino delle pagine non è supportato.
- Gli snapshot del database non sono supportati e vengono ignorati durante la creazione di snapshot VSS componenti e non componenti.
- Database con chiusura automatica o database con arresto abilitato.
- Linux non fornisce un framework VSS e pertanto il writer SQL non è disponibile in Linux.
Nella tabella seguente sono elencati i tipi di backup di snapshot supportati dal writer SQL/SQL Server che utilizzano il framework VSS per tutte le edizioni di SQL Server in Windows.
| Operazione di backup e ripristino | Basate su componenti | Non basato su componenti |
|---|---|---|
| Backup completo dei dati (Incluso il catalogo full-text) |
Sì | Sì |
| Ripristino completo | Sì | Sì |
| Ripristino completo (senza recupero) | Sì | No |
| Backup differenziale | Sì | No |
| Ripristino differenziale | Sì | No |
| Ripristino con spostamento | Sì | No |
| Ridenominazione del database | Sì | No |
| Copia soltanto le copie di backup | Sì | No |
| Snapshot recuperati automaticamente | Sì | No |
| Backup dei log | No | No |
| Snapshot del database | No | No |
| Database con chiusura automatica Database con spegnimento |
Sì | No |
| Database di gruppi di disponibilità | Sì | Non su componenti secondari |
Operazioni di backup
SQL Server (usando il writer SQL) supporta le modalità seguenti delle operazioni di backup basate su VSS:
- Non basato su componenti
- Basate su componenti
Supporto delle versioni
Il writer SQL viene fornito con SQL Server e supporta solo istanze di SQL Server. Il writer SQL enumera anche le istanze di SQL Server Express, incluse le istanze utente avviate da SQL Server Express Edition.
Operazioni di backup non basate su componenti
I backup non basati su componenti selezionano in modo implicito i database usando l'elenco dei volumi nel set di snapshot. Il writer SQL controlla la presenza di database danneggiati e, se ne trova, solleva un errore. Un database corrotto è uno in cui un sottoinsieme di file viene selezionato dall'elenco di volumi.
Nel modello non basato su componenti sono supportati solo i database con il modello di recupero semplice. Il roll-forward dopo il ripristino non è supportato.
Operazioni di backup basate su componenti
I backup basati su componenti sono preferiti e consigliati con il writer SQL, poiché l'applicazione (applicazione di backup VSS) seleziona in modo esplicito i database dai metadati restituiti dal writer SQL. Il set di snapshot deve includere tutti i volumi necessari per eseguire il backup di tali database. L'infrastruttura VSS non aggiunge automaticamente i volumi necessari per il set selezionato di database. Tutti i volumi di backup devono essere inclusi nel set di snapshot dei volumi. È responsabilità dell'applicazione di backup assicurarsi che tutti i volumi di backup siano inclusi nel set di snapshot. Il writer SQL rileva i database danneggiati (con volumi di backup esterni al set di snapshot) e fa fallire il backup.
Nella parte restante di questa sezione, si presume che i backup basati su componenti vengano utilizzati come parte del processo di creazione di snapshot VSS per SQL Server.
Processo di creazione "snapshot"
Il framework VSS coordina le attività di un richiedente (un'applicazione di backup) e del writer SQL durante la creazione di snapshot di SQL Server. Per abilitare questo coordinamento, il framework VSS definisce le interfacce del richiedente e dello scrittore. Queste interfacce devono essere implementate dalle applicazioni richiedenti e dai writer partecipanti. Il writer SQL implementa le interfacce necessarie dello scrittore. Durante il processo di creazione degli snapshot, le interfacce dello SQL Writer vengono chiamate dal framework VSS. Il writer SQL interagisce con le istanze di SQL Server nel sistema per facilitare la creazione degli snapshot.
Il framework VSS definisce un insieme di API da utilizzare da un'applicazione richiedente o di backup. È necessario che lo sviluppatore di un'applicazione di backup segua questi modelli di chiamata API per interagire con il processo di creazione degli snapshot del framework VSS (Servizio Copia Shadow del volume). Le sezioni successive descrivono il processo di creazione degli snapshot dal punto di vista del writer SQL illustrano anche in dettaglio alcune delle interazioni interne tra il richiedente, il VSS framework, lo SQL writer e le istanze di SQL Server.
Per altre informazioni su questi passaggi e per informazioni dettagliate sulle interfacce del framework VSS, vedere Volume Shadow Copy Service (VSS).
Nota
Si presuppone che si abbia familiarità con il framework VSS e il processo di creazione del backup in generale. Queste sezioni forniscono informazioni supplementari su come il writer SQL partecipa al processo di creazione del backup del servizio VSS.
Flusso di lavoro di creazione di snapshot
L'immagine seguente mostra il diagramma del flusso di dati durante un'operazione di creazione/backup di snapshot basata su componenti.
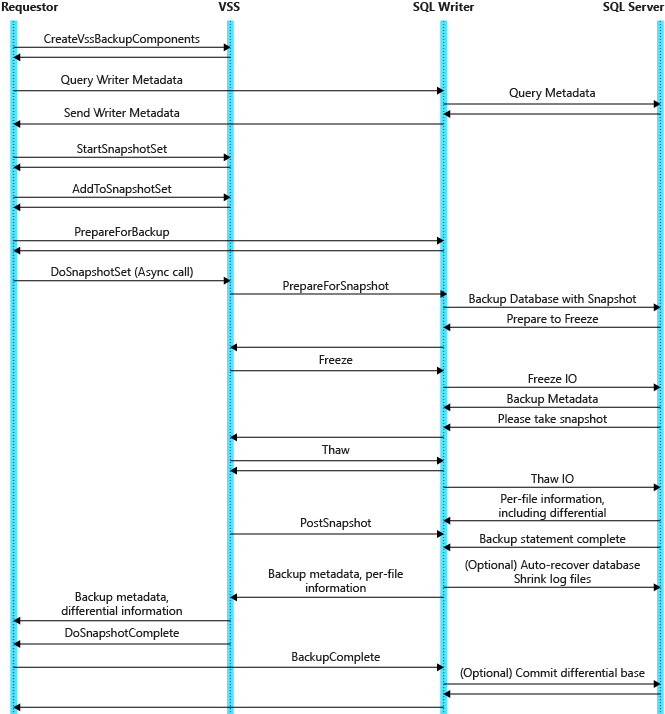
Per comprendere in modo più completo le attività di base necessarie per eseguire un backup, è utile suddividere questa panoramica nelle fasi seguenti:
- Inizializzazione del backup
- Fase di individuazione dei backup
- Attività di pre-backup
- Backup reale dei file
- Terminazione del backup
Inizializzazione del backup
Durante questa fase del backup, il richiedente (applicazione di backup) si collega all'interfaccia IvssBackupComponentssnapshot e la configura in preparazione al backup. Chiama anche l'API del Servizio Copia Shadow del volume IVssGatherWriterMetadata per indicare al framework Servizio Copia Shadow del volume di raccogliere i metadati da tutti i writer.
Il framework VSS chiama ciascuno degli autori registrati, incluso l'autore SQL, per ottenere i metadati dell'autore utilizzando l'evento OnIdentify. Il writer SQL esegue una query sulle istanze di SQL Server per ottenere le informazioni sui metadati di backup per ogni database e creare il documento dei metadati del writer. Questa fase viene definita anche enumerazione dei metadati.
Il documento di metadati del writer è un documento che contiene informazioni passate dal writer al richiedente (applicazione di backup). Il documento dei metadati del writer contiene le informazioni seguenti:
- ID dell'applicazione e nome amichevole
- Posizione in cui esistono file e componenti
- Quali file devono essere inclusi ed esclusi in un backup
- Quali opzioni devono essere usate in fase di ripristino
Queste informazioni vengono passate al richiedente tramite il framework VSS.
Individuazione dei backup
In questa fase, un richiedente esamina il documento di metadati del writer e crea e riempie un documento componente di backup con ogni componente di cui è necessario eseguire il backup. Specifica anche le opzioni e i parametri di backup necessari come parte di questo documento. Per il writer SQL, ogni istanza di database di cui è necessario eseguire il backup è un componente separato.
Documento dei componenti di backup
Si tratta di un documento XML creato da un richiedente (tramite l'interfaccia IVssBackupComponents) durante la configurazione di un'operazione di ripristino o di backup. Il documento dei componenti di backup contiene un elenco dei componenti inclusi esplicitamente, provenienti da uno o più scrittori, coinvolti in un'operazione di backup o ripristino. Non contiene informazioni sui componenti incluse in modo implicito. Al contrario, un documento di metadati writer contiene solo componenti writer che potrebbero partecipare a un backup. I dettagli strutturali di un documento di un componente di backup sono descritti nella documentazione dell'API VSS.
Attività di pre-backup
Le attività di pre-backup nel Servizio Copia Shadow del volume sono relative alla creazione di una copia shadow dei volumi contenenti i dati per il backup. L'applicazione di backup salva i dati dalla copia shadow, non dal volume effettivo.
I richiedenti in genere attendono i writer durante la preparazione del backup e durante la creazione della copia shadow. Se il writer SQL partecipa all'operazione di backup, deve configurare i propri file e anche se stesso per prepararsi al backup e alla copia ombra.
Preparare il backup
Il richiedente deve impostare il tipo di operazione di backup che deve essere eseguita (IVssBackupComponents::SetBackupState) e quindi notifica ai writer tramite VSS, per preparare un'operazione di backup usando IVssBackupComponents::PrepareForBackup.
Al writer SQL viene concesso l'accesso al documento del componente di backup, che illustra in dettaglio quali database devono essere sottoposti a backup. Tutti i volumi di backup devono essere inclusi nel set di snapshot dei volumi. Il writer SQL rileva i database danneggiati (con volumi di backup al di fuori del set di snapshot) e il backup non riesce durante l'evento PostSnapshot.
Backup effettivo dei file
In questa fase, il richiedente può spostare i dati in un supporto di backup, se necessario. Le interazioni in questa fase avvengono tra il richiedente e il framework VSS. Il modulo di scrittura SQL non è coinvolto.
- Ottenere lo status di scrittore. Restituisce lo stato degli scrittori. Il richiedente potrebbe dover gestire eventuali errori qui.
- Eseguire il backup.
In questa fase, il richiedente può spostare i dati in un supporto di backup, se necessario.
Backup completato
Questo evento indica che il backup è stato completato correttamente.
È anche il momento a partire dal quale il writer SQL può convalidare il backup come base differenziale, se il backup corrente è un backup dell'intero database (e non un backup solo di copia).
Nota
Il richiedente deve inviare in modo esplicito questo evento (evento Backup completo) per consentire al writer SQL di eseguire il commit dei backup di base differenziale. Se questo evento non viene ricevuto, il backup creato non è un backup differenziale idoneo.
Salvare i metadati di Writer
Il richiedente deve salvare il documento del componente di backup e i metadati di backup di ogni componente insieme ai dati supportati dallo snapshot. Questi metadati del writer sono necessari al writer SQL o a SQL Server per le operazioni di ripristino.
Terminazione del backup
Il richiedente termina la copia shadow rilasciando l'interfaccia IVssBackupComponents o chiamando IVssBackupComponents::DeleteSnapshots.
Documento dei metadati del writer SQL
Si tratta di un documento XML creato da un writer (in questo caso, il writer SQL) usando l'interfaccia IVssCreateWriterMetadata e contenente informazioni sullo stato e sui componenti del writer. I dettagli strutturali di un documento di metadati writer sono descritti nella documentazione dell'API VSS. Ecco alcuni dettagli del documento di metadati del writer SQL.
Informazioni di identificazione dello scrittore
- Nome del writer: L"SqlServerWriter"
- ID classe del writer: 0xa65faa63, 0x5ea8, 0x4ebc, 0x9d, 0xbd, 0xa0, 0xc4, 0xdb, 0x26, 0x91, 0x2a
- ID istanza del writer: L"SQL Server:SQLWriter"
- VSSUsageType: VSS_UT_USERDATA
- VSSSourceType: VSS_ST_TRANSACTEDDB
Informazioni a livello di writer: VSS_APP_BACK_END
Specifica del metodo di ripristino: VSS_RME_RESTORE_IF_CAN_REPLACE.
Schema di backup supportato (IVssCreateWriterMetadata::SetBackupSchema API)
- VSS_BS_DIFFERENTIAL: backup differenziale
- VSS_BS_TIMESTAMPED: Basato su timestamp, per file di catalogo a testo completo.
- VSS_BS_LAST_MODIFY: backup differenziale basato sull'ora dell'ultima modifica.
- VSS_BS_WRITER_SUPPORTS_NEW_TARGET: supporta l'opzione della nuova posizione di destinazione.
- VSS_BS_WRITER_SUPPORTS_RESTORE_WITH_MOVE: supporta il ripristino "con spostamento"
- VSS_BS_COPY: supporta l'opzione di backup "solo copia".
Informazioni sul livello di componente (contiene informazioni specifiche a livello di componente fornite dal writer SQL)
- Tipo: VSS_CT_FILEGROUP
- Nome: nome del componente (nome del database)
- Percorso logico : dell'istanza del server (sotto forma di "server\nome-istanza" per le istanze denominate e "server" per l'istanza predefinita).
- Flag dei componenti
- VSS_CF_APP_ROLLBACK_RECOVERY: indica che gli snapshot di SQL Server richiedono sempre una fase di "ripristino" per rendere i file coerenti e utilizzabili per gli scenari non di backup (ovvero per il rollback delle app).
- Selezionabile - Vero
- Selezionabile per il ripristino - Vero
- Metodi di ripristino supportati: VSS_RME_RESTORE_IF_CAN_REPLACE
L'unica estensione della struttura del set di componenti in SQL Server è l'introduzione di cataloghi full-text. I cataloghi full-text sono directory contenitore, che non possono essere espressi come il database o i file di log VSS, dato che il database VSS e i file di log non hanno specifiche ricorsive. Pertanto, il writer SQL utilizza un componente filegroup VSS (VSS_CT_FILEGROUP) per rappresentare il componente a livello di database e utilizza i file di filegroup per rappresentare i file di database, di log e di catalogo full-text.
Alla fine di questo documento è fornito un esempio di documento di metadati dell'autore.
Avvia lo snapshot
Il richiedente avvia il processo di snapshot chiamando l'interfaccia DoSnapshotSetdel framework VSS .
Crea istantanea
Questa fase prevede una serie di interazioni tra il framework VSS e il writer SQL.
Preparare lo snapshot. Il writer SQL chiama SQL Server per preparare la creazione di snapshot.
Congelare. Il writer SQL chiama SQL Server per bloccare tutte le operazioni di I/O del database per ogni database sottoposto a backup nello snapshot. Quando l'evento di blocco torna al framework VSS, VSS crea lo snapshot.
Scongelare. In questo evento, il writer SQL chiama le istanze di SQL Server per scongelare o riprendere le normali operazioni di I/O.
La fase di creazione dello snapshot richiede meno di 60 secondi per impedire il blocco di tutte le scritture nel database.
Post-snapshot
Se è necessaria la funzionalità di salvataggio automatico per lo snapshot, il writer SQL esegue il salvataggio automatico per ogni database selezionato per lo snapshot. Per una spiegazione dettagliata, vedere Snapshot recuperati automaticamente.
Processo di ripristino
Questa sezione descrive il flusso di lavoro dell'operazione di ripristino e i passaggi necessari.
Flusso di lavoro dell'operazione di ripristino
La figura seguente mostra il diagramma del flusso dei dati durante un'operazione di ripristino VSS.
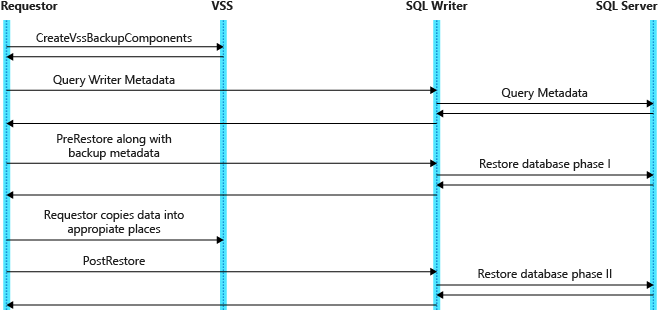
Per comprendere in modo più completo le attività di base coinvolte nell'esecuzione di un ripristino, è utile suddividere questa panoramica nelle sezioni seguenti:
- Ripristino dell'inizializzazione
- Preparazione per il ripristino
- Ripristino effettivo dei file
- Ripristinare la pulizia e la terminazione
In tutti gli scenari di ripristino basati su componenti del Servizio Copia Shadow del volume, il ripristino del database viene gestito dal writer SQL in due fasi distinte.
- Pre-ripristino: Il writer SQL si occupa della convalida, della chiusura dei handle di file, eccetera.
- Post-ripristino: il writer di SQL collega il database ed esegue il ripristino dopo un arresto anomalo, se necessario.
Tra queste due fasi, l'applicazione di backup è responsabile dello spostamento dei dati pertinenti all'interno dell'ambiente SQL sottostante.
Ripristina l'inizializzazione
Durante la fase di inizializzazione di un ripristino, il richiedente deve avere accesso ai documenti dei componenti di backup archiviati.
Il documento del componente di backup generato durante l'operazione di backup viene archiviato come parte dei dati di backup. L'applicazione di backup deve passare questi dati al framework VSS (Servizio Copia Shadow del Volume). Il writer SQL ottiene l'accesso a questi dati all'inizio del processo di ripristino.
Preparare il ripristino
Quando il richiedente si prepara per un ripristino, usa il documento dei componenti di backup archiviati per determinare cosa deve essere ripristinato e come. Il richiedente seleziona i componenti da ripristinare e imposta le opzioni di ripristino appropriate in base alle esigenze.
Se un'applicazione di backup intende applicare backup differenziali o di log oltre l'operazione di ripristino corrente (ovvero, è necessario eseguire il ripristino con opzione norecovery), l'opzione seguente deve essere impostata come parte della creazione del componente per ogni database in fase di ripristino.
IVssBackupComponents::SetAdditionalRestores(true)
Dopo aver impostato tutti i dettagli necessari nel documento del componente di backup, il richiedente effettua la IVssBackupComponents::PreRestore chiamata per generare un evento di pre-ripristino tramite VSS gestito dai writer.
Il writer SQL esamina il documento del componente di backup fornito per identificare i database appropriati, eliminando eventuali file aggiuntivi creati dopo l'ora di backup. Controlla anche gli spazi su disco e chiude eventuali handle di file di database aperti, in modo che il richiedente possa copiare i dati necessari durante la fase di ripristino. Questa fase consente di rilevare eventuali condizioni di errore iniziali prima che il richiedente esegua la copia del file effettivo. SQL Server inserisce anche il database in stato di ripristino. Da questo punto in poi, il database non può essere avviato fino a quando non viene eseguito correttamente il ripristino.
Ripristinare i file
Si tratta di un'azione specifica del richiedente. È responsabilità del richiedente (applicazione di backup) copiare i file di database necessari (o copiare gli intervalli di dati pertinenti per i ripristini differenziali) nelle posizioni appropriate. Il writer SQL non è coinvolto in questa operazione.
Pulizia e terminazione
Una volta ripristinati tutti i dati nelle posizioni corrette, una chiamata da un richiedente che informa che l'operazione di ripristino è stata completata IvssBackupComponents::PostRestore, consente al writer SQL di sapere che è possibile avviare azioni di post-ripristino. Il writer SQL a questo punto esegue la fase di redo del ripristino dall'arresto anomalo. Se il ripristino non viene richiesto (ovvero SetAdditionalRestores(true) non viene specificato dal richiedente), durante questa fase viene eseguita anche la fase di annullamento del passaggio di ripristino.
Dettagli delle opzioni di backup e ripristino
Questa sezione descrive in dettaglio tutte le opzioni di backup e ripristino supportate dal writer SQL.
Il richiedente crea una copia istantanea del volume
Il writer SQL potrebbe essere coinvolto nel processo di creazione della copia shadow del volume (al di fuori del contesto di backup e ripristino), perché i volumi di backup per i file di database sono stati aggiunti al set di snapshot del volume. In questo caso, il writer SQL partecipa solo all'enumerazione dei metadati, Freeze, Thaw, PrepareForSnapshote PostSnapshot al coordinamento (vedere il diagramma del flusso di dati per informazioni dettagliate).
Backup completo e ripristino
Il writer SQL supporta operazioni di backup e ripristino complete sia in modalità non basata su componenti che in modalità basata su componenti.
Backup e ripristino non basati su componenti
In un backup e ripristino non basato su componenti, il richiedente specifica un volume o un albero di cartelle di cui eseguire il backup e il ripristino. Viene eseguito il backup e il ripristino di tutti i dati nel volume e nella cartella specificata.
copia di sicurezza
In un backup non basato su componenti, il writer SQL seleziona in modo implicito i database usando l'elenco di volumi nel set di snapshot. Il writer controlla la presenza di database danneggiati e, se ne trova, genera un errore. Un database strappato è uno in cui un sottoinsieme di file è selezionato dall'elenco dei volumi. Roll-forward (ripristini differenziali o di log) dopo un ripristino non è supportato tramite lo SQL writer.
Recupera
Il richiedente ripristina i database di cui è stato eseguito il backup in modalità non basata su componenti. Tali ripristini non possono essere seguiti da un ripristino in avanti, come il ripristino del log o il ripristino differenziale.
Per le operazioni di ripristino non basate su componenti, il ripristino deve essere eseguito con l'istanza di SQL Server offline oppure i database di destinazione vengono eliminati o scollegati per garantire che i file siano offline. I file vengono copiati sul posto e quindi i database vengono allegati. Tutte queste operazioni vengono eseguite al di fuori dell'ambito del writer SQL.
Backup e ripristino basati su componenti
In un backup basato su componenti, il richiedente seleziona in modo esplicito i componenti del database (dai metadati che il writer SQL restituisce al client) per eseguire il backup/ripristino.
Copia di sicurezza
In un backup basato su componenti, tutti i volumi di backup per i database selezionati devono essere inclusi nel set di snapshot dei volumi. In caso contrario, il writer SQL rileva i database parzialmente danneggiati (con volumi di supporto esterni al set di snapshot) e il backup fallisce. Un backup completo esegue il backup dei dati del database e di tutti i file di log necessari perché lo stato del database al momento del ripristino sia coerente a livello di transazione.
Ripristino completo senza avanzamento
A volte viene eseguito un ripristino completo del backup del database senza eseguire alcun rollforward aggiuntivo. Questo potrebbe essere dovuto al fatto che non sono presenti metadati per facilitare il rollforward o, in alcuni casi, il rollforward non è necessario. Questa sezione descrive brevemente le due situazioni.
Nessun metadato/nessun avanzamento di stato
Se non vengono salvati metadati del writer (metadati di backup basati su componenti) durante l'operazione di backup, il ripristino deve essere eseguito con l'istanza di SQL Server offline, altrimenti i database di destinazione vengono eliminati/scollegati per garantire che i file siano offline. I file vengono copiati nella posizione e quindi i database vengono collegati. Tutte queste operazioni vengono eseguite al di fuori dell'ambito del writer SQL.
I metadati esistono ma non sono necessari rollforward aggiuntivi
Il richiedente ripristina i database di cui è stato eseguito il backup in modalità basata su componenti, ma non viene richiesto alcun roll forward. In questo caso SQL Server esegue il ripristino dopo un arresto anomalo del database durante il ripristino.
Ripristino completo con rollforward aggiuntivo
Il richiedente può eseguire un ripristino specificando l'opzione SetAdditionalRestores(true) . Questa opzione indica che il richiedente intende eseguire ulteriori ripristini roll-forward, come ulteriori ripristino del log, ripristino differenziale e così via. e indica a SQL Server di non eseguire il passaggio di recupero al termine dell'operazione di ripristino.
Ciò è possibile solo se i metadati del writer sono stati salvati durante il backup e sono disponibili per il writer SQL al momento del ripristino. Il servizio SQL Server deve essere in esecuzione prima che il richiedente istruisca il VSS a eseguire l'attività di ripristino.
Il writer SQL prevede la sequenza seguente:
Preparazione del ripristino di ogni database. Questa attività comporta la chiusura di tutti gli handle di file in modo che i file di database possano essere copiati/montati dall'applicazione richiedente.
I file vengono copiati o montati dall'applicazione richiedente.
Finalizzare il ripristino (con
NORECOVERY). I database vengono portati online, ma in uno stato di ripristino .
I backup convenzionali di SQL Server, i backup differenziali o i log possono quindi essere usati per avanzare il database tramite VDI o Transact-SQL, oppure applicando il ripristino differenziale usando il framework VSS.
Supporto testo integrale
Il writer SQL segnala contenitori di cataloghi full-text con specifiche di file ricorsive nei componenti di database nel documento dei metadati del writer. Vengono inclusi automaticamente nel backup quando viene selezionato il componente del database.
Backup e ripristino differenziale
Un'operazione di backup differenziale esegue un backup solo dei dati che sono stati modificati dopo il backup completo di base più recente. Un backup differenziale contiene solo le parti dei file di database che sono state modificate. Per eseguire un backup di questo tipo, il richiedente (applicazione di backup) necessita di informazioni sul percorso delle modifiche nei file di database, in modo che sia possibile eseguire il backup delle sezioni appropriate dei file. Durante un'operazione di backup differenziale, il writer SQL fornisce queste informazioni nel formato specificato dalle informazioni sui file parziali di VsS. Queste informazioni possono essere usate per eseguire il backup solo della parte modificata dei file di database.
Copia di sicurezza
Il richiedente può eseguire un backup differenziale impostando l'opzione DIFFERENTIALVSS_BT_DIFFERENTIAL nel documento IVssBackupComponents::SetBackupStatedel componente di backup quando si avvia un'operazione di backup con VSS. Il writer SQL passa le informazioni sui file parziali (restituite da SQL Server) al Servizio Copia Shadow del Volume. Il richiedente può ottenere le informazioni su questo file chiamando le API di VSS IVssComponent::GetPartialFile. Queste informazioni sul file parziale consentono al richiedente di scegliere solo gli intervalli di byte modificati per eseguire il backup dei file di database.
Durante la fase di attività di pre-backup, il writer SQL assicura che esista una singola base differenziale per ogni database selezionato.
Durante l'evento PostSnapshot, il writer SQL ottiene le informazioni sui file parziali da SQL Server e le aggiunge al documento componente di backup usando la chiamata IVssComponent::AddPartialFile.
Nota
Il writer SQL supporta una sola baseline differenziale per i backup differenziali. Le baseline multiple non sono supportate.
Formato delle informazioni parziali sul file
Per ogni database sottoposto a backup durante un backup differenziale, il writer SQL archivia le informazioni sui file parziali per ogni file di database. Queste informazioni vengono usate dal richiedente o dall'applicazione di backup per copiare solo le parti pertinenti del file nel supporto di backup durante il backup effettivo dei file.
Per altre informazioni sul formato per queste informazioni di file parziali, vedere Servizio Copia Shadow del Volume (VSS).
Un richiedente può determinare questi file chiamando IVssComponent::GetPartialFileCount e IVssComponent::GetPartialFile.
IVssComponent::GetPartialFile restituisce un percorso e un nome file che punta al file e una stringa di intervalli che indica quali elementi devono essere sottoposti a backup nel file.
Per ulteriori informazioni sul recupero parziale delle informazioni sul file, consultare la documentazione del Servizio Copia Shadow del volume.
Eseguire un backup dei file
Durante questa fase, l'applicazione di backup deve esaminare i metadati del writer archiviati nel documento del componente di backup e eseguire il backup solo delle parti pertinenti dei file. Per i file di catalogo full-text, questo backup deve essere eseguito in base ai timestamp dei file. Questo articolo è descritto più avanti in questo articolo.
Un backup differenziale è sempre correlato al backup di base più recente esistente per il database. In fase di ripristino, SQL Server rileva backup di base e differenziali non corrispondenti. È quindi responsabilità dell'applicazione di backup o dell'amministratore di sistema assicurarsi che il differenziale sia relativo al backup completo previsto. Se alcune procedure fuori banda hanno eseguito un altro backup completo, l'applicazione di backup potrebbe non essere in grado di ripristinare il differenziale, perché non è proprietario del backup di base.
Attualmente se le informazioni sull'intervallo di byte (informazioni sui file parziali) sono troppo grandi (superiori a 64 KB nelle dimensioni del buffer), SQL Server genera un errore che indica all'utente di eseguire un backup completo.
Risoluzione dei problemi
L'aggiunta, eliminazione, riduzione, crescita, ridenominazione logica e ridenominazione fisica rendono particolari i casi nella risoluzione dei problemi di backup.
File appena aggiunti dopo l'uso della base
Questi file sono inclusi nella specifica parziale perché ogni intestazione del file di database deve trovarsi nella specifica parziale. È necessario includere nella specifica parziale, oltre alla pagina di intestazione, tutte le pagine allocate.
File rimossi dopo la presa della base
Una volta acquisita la base, è possibile eliminare i file di dati. Tali file non sono inclusi nel documento dei metadati del writer durante il backup differenziale. Inoltre, nessuna informazione parziale è associata al file eliminato.
I file si riducono dopo che la base è stata presa
Le informazioni parziali non vengono raccolte dai file fino a quando la compattazione del file non è stata disabilitata nel server. In questo modo, vss non include mai informazioni parziali che corrispondono all'area compatta di un file di dati.
I file cresciuti dopo la creazione della base
Se si verifica un aumento delle dimensioni prima della raccolta delle informazioni parziali, tali informazioni dovrebbero includere le pagine allocate nell'area con dimensioni aumentate. Se la crescita è avvenuta dopo la raccolta delle informazioni parziali, le informazioni parziali non includono modifiche nell'area cresciuta. Nelle sezioni seguenti si noterà che tali modifiche vengono ripristinate dal rollforward del log.
File rinominato logicamente dopo l'uso della base
Una ridenominazione logica del file non influisce sul backup o sul ripristino, perché il nome logico del file non viene fatto riferimento in nessun punto del documento di metadati del writer o nel documento del componente di backup.
Per altre informazioni, vedere Documento sui metadati del writer: un esempio più avanti in questo articolo.
File fisicamente rinominato dopo che la base è stata acquisita
La ridenominazione di un file di database fisico non ha effetto fino al riavvio del database. quindi le informazioni di configurazione del database o le informazioni sul percorso del file nel buffer delle informazioni parziali sono ancora basate sui percorsi fisici precedenti, che sono gli unici percorsi validi di tali file di database nello snapshot.
Recupera
Durante un ripristino differenziale, i metadati di backup restituiti dal richiedente al writer SQL contengono le informazioni sul tipo di backup. Non è quindi necessario alcun trattamento speciale da parte del writer SQL. SQL Server scopre che si tratta di un ripristino differenziale da solo. SQL Server gestisce un ripristino differenziale allo stesso modo di un ripristino differenziale nativo che non viene eseguito tramite VSS.
Fase di pre-ripristino
Durante questa fase, SQL Server ridimensiona tutti i file alla dimensione appropriata sulla base dei metadati del file del backup differenziale. Se il file viene aumentato, SQL Server azzera la porzione aumentata. Se è necessario creare un nuovo file (è stato creato dopo l'uso della base), SQL Server zerorà il nuovo file. Chiude anche tutti gli handle di file in modo che l'applicazione di backup possa sovrascrivere i file con i dati ripristinati dai supporti di backup.
Ripristinare i file
Il client deve ripristinare i file in base alla specifica parziale del file. I dati devono essere ripristinati alla stessa posizione/intervallo del file di database, come specificato nella descrizione parziale di file memorizzata nei metadati del writer.
Il processo di aggiunta/eliminazione/espansione/riduzione/rinominazione logica/rinominazione fisica del file di database pone nuovamente interessanti sfide di risoluzione dei problemi durante il ripristino.
Se è stato aggiunto un file di database dopo aver acquisito la base completa
Tali file devono essere stati precreati da SQL Server durante la fase di preparazione del ripristino. Devono essere stati estesi fino alle dimensioni corrette e azzerati. Il client deve solo inserire i dati in base alla specifica parziale, che include tutte le estensioni allocate.
Se un file di database è stato eliminato dopo aver acquisito la base completa
Le informazioni parziali fornite da SQL Server non includono informazioni di rilevamento per tali eliminazioni di file. SQL Server ha la responsabilità di rilevare i file da eliminare, confrontando i metadati dei file ripristinati con i contenitori esistenti, e di eliminarli effettivamente. Questa operazione viene eseguita prima del ripristino come passaggio di preparazione.
Se un file di database è cresciuto dopo l'uso della base completa
Tali file devono essere estesi alle dimensioni corrette di SQL Server durante la fase di preparazione del ripristino. Anche l'area estesa deve essere azzerata da SQL Server. Pertanto, il cliente può posizionare in modo sicuro i dati anche nell'area sviluppata secondo la specifica parziale. Se il file è stato ampliato dopo che erano state acquisite le informazioni parziali, le modifiche nella regione ampliata vengono ripristinate eseguendo il log che era stato salvato insieme al backup differenziale.
Se un file di database è stato ridotto dopo l'esecuzione della base completa
SQL Server è responsabile del troncamento del file fino alle dimensioni necessarie in base ai metadati. Questa operazione viene eseguita prima del ripristino come passaggio di preparazione.
Se un file di database è stato rinominato logicamente dopo l'uso della base completa
Ciò non influisce sul ripristino, perché il nome logico non viene visualizzato nel documento dei metadati del writer o nel documento del componente di backup. La modifica del nome logico viene ripristinata quando il client applica la modifica al file di database primario, che contiene le informazioni sul catalogo di sistema.
Se un file di database è stato rinominato fisicamente dopo l'uso della base completa
Se al momento del backup differenziale, la ridenominazione non è stata applicata, il client ripristina comunque i dati nella posizione precedente. Un riavvio del database dopo il ripristino causa l'applicazione della ridenominazione fisica. Se al momento del backup differenziale, la ridenominazione fisica del file era già stata applicata, i dati parziali, se presenti, vengono sottoposti a backup dal nuovo percorso fisico.
Postripristino
Durante gli eventi di post-ripristino, il writer SQL esegue la normale operazione di ripetizione e il ripristino (se SetAdditionalRestores() è impostato su False) del database.
Backup e ripristino differenziale dei cataloghi a testo completo
I cataloghi full-text di SQL Server fanno parte delle risorse del database di cui è necessario eseguire un backup o un ripristino con gli altri file di database. Un backup differenziale è basato su timestamp per il catalogo full-text. Il backup differenziale VSS di SQL Server e il ripristino hanno un unico backup di base. In altre parole, non esistono basi diverse per contenitori diversi. Nel caso del backup del catalogo full-text VSS, questo significa che per tutti i contenitori di catalogo full-text il backup differenziale è basato su un singolo timestamp, a differenza del caso del backup differenziale nativo di SQL Server, in cui è presente un timestamp di base per ogni contenitore di catalogo full-text.
In VSS, questo timestamp è espresso come proprietà a livello di componente impostata durante il backup completo e utilizzata durante un successivo backup differenziale.
OnIdentify
In OnIdentifyil writer SQL chiama IVssCreateWriterMetadata::SetBackupSchema() per impostare il valore VSS_BS_TIMESTAMPED. Questo indica all'applicazione di backup che il writer SQL è responsabile della gestione della base differenziale.
Impostare il timestamp di base
Il timestamp di base viene impostato durante un backup completo. In OnPostSnapshot(), lo scrittore richiama IVssComponent::SetBackupStamp() per archiviare il timestamp insieme al componente nel documento di backup.
Backup differenziale
L'applicazione di backup recupera questo timestamp dal backup completo di base e rende disponibile il timestamp per il writer chiamando IVssComponent::GetBackupStamp() per recuperare il timbro di base dal backup di base precedente. Lo rende quindi disponibile per lo scrittore chiamando IVssBackupComponent::SetPreviousBackupStamp(). Il writer recupera quindi lo stamp chiamando IVssComponent::GetPreviousBackupStamp() e lo converte in un timestamp usato per IVssComponent::AddDifferencedFilesByLastModifyTime().
Responsabilità dell'applicazione di backup durante il backup differenziale
Durante un backup differenziale, l'applicazione di backup è responsabile di:
Backup di qualsiasi file (l'intero file) il cui timestamp dell'ultima modifica è maggiore del timestamp specificato dall'ora dell'ultima modifica per il file impostato nel componente.
Verifica e rilevamento dei file eliminati.
Responsabilità dell'applicazione di backup durante un ripristino differenziale
Durante un ripristino differenziale, l'applicazione di backup è responsabile di:
Ripristino di tutti i file di cui è stato eseguito il backup, creando un nuovo file se non esiste già o sovrascrivendo un file esistente, se già esistente.
Espansione del file prima di riposizionare il contenuto se il file ripristinato è più grande del file esistente.
Troncamento del file alle stesse dimensioni del file ripristinato se il file ripristinato è più piccolo del file esistente.
Eliminazione di tutti i file da eliminare; ovvero i file che non devono esistere fino al momento del backup differenziale.
Backup di sola copia
A volte è necessario eseguire un backup destinato a uno scopo speciale. Ad esempio, potrebbe essere necessario creare una copia di un database a scopo di test. Questo backup non deve influire sulle procedure generali di backup e ripristino per il database. L'uso dell'opzione COPY_ONLY specifica che il backup viene eseguito fuori banda e non deve influire sulla normale sequenza di backup. Il writer SQL supporta il tipo di backup di sola copia con le istanze di SQL Server.
Durante la fase di individuazione del backup, il writer SQL indica la sua capacità di eseguire un backup di sola copia impostando l'opzione VSS_BS_COPY dello schema di backup supportato usando la chiamata IVssCreateWriterMetadata::SetBackupSchema. Il richiedente può impostare il tipo di backup come backup di sola copia impostando l'opzione VSS_BACKUP_TYPE come VSS_BT_COPY con la chiamata IVssBackupComponents::SetBackupState.
Quando si seleziona un backup di sola copia, si presuppone che i file su disco vengano copiati in un supporto di backup (dal richiedente) indipendentemente dallo stato della cronologia di backup di ogni file. SQL Server non aggiorna la cronologia dei backup. Questo tipo di backup non costituisce un backup di base per ulteriori operazioni di backup differenziale e non disturba anche la cronologia dei backup differenziali precedenti.
Ripristino con spostamento
Vss consente al richiedente (applicazione di backup) di specificare una nuova destinazione di ripristino usando la IVssComponent::SetNewTarget chiamata. In PreRestore() e PostRestore(), il writer SQL controlla se è presente almeno una nuova destinazione. È responsabilità dell'applicazione di backup copiare fisicamente i file nel nuovo percorso durante la fase effettiva di ripristino o copia dei file.
L'applicazione di backup può specificare solo nuove destinazioni per il percorso fisico, ma non la specifica del file. Ad esempio, per un file di database che si trova in c:\data\test.mdf, il nome test.mdf file effettivo non può essere modificato. È possibile modificare solo il percorso c:\data . Per un contenitore di catalogo full-text che si trova in c:\ftdata\foo, poiché la specifica del file in VSS è "*" e la specifica del percorso in VSS è c:\ftdata\foo, è possibile modificare l'intero percorso.
Ridenominazione del database
Un richiedente potrebbe dover ripristinare un database di SQL Server con un nuovo nome, soprattutto se il database deve essere ripristinato side-by-side con il database originale. Questa opzione può essere specificata dal richiedente durante l'operazione di ripristino impostando un'opzione di ripristino personalizzata come "Nuovo nome componente" = <"Nuovo nome"> usando la chiamata IVssBackupComponents::SetRestoreOptions() vss (nel wszRestoreOptions parametro).
Il writer SQL accetta l'intero contenuto del valore di New Component Name e lo usa come nuovo nome per il database ripristinato. Se non viene specificata alcuna opzione, SQL Server ripristina il database con il nome originale (nome del componente).
Nota
Il writer SQL attualmente non supporta Rinomina tra istanze per spostare un database in una nuova istanza.
Snapshot recuperati automaticamente
In genere uno snapshot del database di SQL Server ottenuto usando il framework del Servizio Copia Shadow del volume è in uno stato non recuperato. I dati nello snapshot non possono essere accessibili in sicurezza prima di passare attraverso la fase di recupero per eseguire il rollback delle transazioni in corso e portare il database in uno stato coerente. Poiché lo snapshot è in sola lettura, non può essere recuperato dal normale processo di collegamento del database.
È possibile ripristinare automaticamente gli snapshot come parte del processo di creazione dello snapshot. Come parte del documento dei metadati del writer, il writer SQL specifica il flag del componente VSS_CF_APP_ROLLBACK_RECOVERY per indicare che il ripristino deve essere eseguito per il database nello snapshot prima che sia possibile accedere al database. Quando si specifica il set di snapshot, il richiedente può indicare che lo snapshot deve essere uno snapshot di rollback dell'applicazione (ovvero, tutti i file di database in uno snapshot devono essere in uno stato coerente per l'utilizzo dell'applicazione) o uno snapshot di backup (un'istantanea usata per il backup dei dati da ripristinare in un secondo momento in caso di errore di sistema).
Il richiedente deve impostare VSS_VOLSNAP_ATTR_ROLLBACK_RECOVERY per indicare che viene eseguito il backup di questo componente per uno scopo non di backup. Il servizio Copia Shadow del database correla VSS_CF_APP_ROLLBACK_RECOVERY quindi che il writer SQL specificato nel componente selezionato con VSS_VOLSNAP_ATTR_ROLLBACK_RECOVERYe determina che si sta verificando il ripristino automatico. VSS rende lo snapshot scrivibile per un periodo di tempo limitato e aggiunge automaticamente il VSS_VOLSNAP_ATTR_AUTORECOVERY bit al contesto dello snapshot.
In SQL Server il salvataggio automatico deve essere applicato solo agli snapshot di rollback delle app, ma non agli snapshot di backup. Per gli snapshot di ripristino dello stato precedente dell'app, un processo di recupero automatico viene avviato dal writer SQL durante l'evento PostSnapShotevent. Questo processo esegue le operazioni seguenti per ogni database SQL Server selezionato in modo esplicito (dal richiedente) nel set di snapshot:
Collegare il database di snapshot all'istanza di SQL Server originale, ovvero l'istanza a cui è collegato il database originale.
Recuperare il database. Questa operazione viene eseguita durante l'operazione di "collegamento".
Ridurre la dimensione dei file di log.
In questo modo si riduce la quantità di operazioni non necessarie di copy-on-write che devono essere eseguite dal framework VSS, se il provider VSS è un provider software. La compattazione dei file di log è il comportamento predefinito, Questa opzione può essere disabilitata impostando il valore sulla chiave del Registro di sistema seguente su
1.HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\SQLWriter\Settings\DisableLogShrinkCiò può essere utile negli scenari in cui lo snapshot potrebbe essere usato per esportare i dati da una pagina specifica (in un momento specifico) dal log per risolvere un problema nel database online.
Scollegare il database.
È ora disponibile uno snapshot coerente e ripristinato che può essere collegato per l'esecuzione di query.
Transazioni tra più database
Nelle versioni precedenti di SQL Server, i database snapshot potrebbero talvolta contenere alcune transazioni multi-database in corso. Durante l'operazione di ripristino, il writer SQL collega il database agli snapshot con l'opzione Interruzione Presunta. In questo modo verrà eseguito il rollback di qualsiasi transazione multi-database non ancora sottoposta a commit ( incluse le transazioni in stato Preparato al commit). Ciò potrebbe causare alcune incoerenze tra i database nel set di snapshot.
Si considerino ad esempio due database, A e B. Esiste una transazione distribuita tra questi due database e questa transazione è in stato di commit nel database A e in stato di Pronto per il commit nel database B. Nell'ambito del processo di recupero automatico, viene eseguito il commit di questa transazione nel database A e viene eseguito il rollback nel database B. Ciò potrebbe causare alcune incoerenze nel set di snapshot.
Le versioni più recenti di Windows hanno un componente migliorato di Microsoft Distributed Transaction Coordinator (MS DTC) che risolve questo problema di incoerenza per le transazioni che si estendono su database tra istanze di SQL Server. Le versioni più recenti di SQL Server consentono di correggere queste incoerenze per le transazioni che si estendono su database all'interno di un'istanza di SQL Server.
Implicazioni per la sicurezza degli snapshot recuperati automaticamente
Per gli snapshot VSS, dopo il ripristino automatico, i file vengono protetti usando gli elenchi di controllo accessi (ACL) per consentire l'accesso solo al particolare gruppo predefinito di cui l'account di SQL Server fa parte. Ciò implica che i membri di un amministratore casella o di un gruppo speciale siano in grado di collegare il database. Il client che richiede di collegare i file del database a un'istantanea deve essere un membro di Builtin/Administrators o avere un account di SQL Server.
Database utente con modello di recupero semplice
Se il master database viene ripristinato insieme ai database utente che usano il modello di recupero con registrazione minima, i database utente possono essere ripristinati con la stessa tecnica del master database: con l'istanza arrestata, è sufficiente copiare o montare i volumi. Quando viene avviata l'istanza di SQL, viene eseguito il recupero di tutti gli elementi.
Avanzamento dei database degli utenti
Se i database utente devono essere recuperati e distribuiti insieme al master ripristino del database, l'istanza non deve avviare e ripristinare insieme i master database utente e .
Di seguito è riportata la procedura:
Verificare che l'istanza di SQL Server sia arrestata.
Eseguire il ripristino in due fasi.
Ripristinare i database di sistema e i database utente che devono essere ripristinati contemporaneamente (ovvero i database utente nel modello di recupero con registrazione minima) tramite copia file o montaggio del volume tramite VSS.
Se i database utente da avanzare non si trovano nello stesso volume dei database di sistema, quel volume non dovrebbe essere ripristinato in questo momento. Questo scenario richiede la pianificazione prima del backup.
Se i database utente si trovano nello stesso volume dei database di sistema, è necessario che i database utente siano nascosti a SQL Server.
Avviare l'istanza di SQL Server usando il
-fparametro . Quando si usa l'opzione-fdi avvio, è possibile ripristinare solo ilmasterdatabase.Emettere un
ALTER DATABASE <database> SET OFFLINE(o scollegare il database) per ogni database da avanzare.Arrestare l'istanza di SQL Server.
Avviare l'istanza di SQL Server (i file per i database utente da inoltrare non sono visibili a SQL Server).
Usare VSS per ripristinare i database utente WITH NORECOVERY, come descritto in Ripristino completo con roll-forward aggiuntivo.
Documento dei metadati di Writer: Un esempio
Un database denominato DB1, appartenente all'istanza Instance1 di SQL Server nel computer Server1, contiene i file di database/log seguenti:
- File di database denominato "primary" archiviato in
c:\db\DB1.mdf - File di database denominato "secondario" archiviato in
c:\db\DB1.ndf - File di log del database denominato "log" archiviato in
c:\db\DB1.ldf - Catalogo di testo completo denominato "foo" archiviato nella directory
c:\db\ftdata\foo - Catalogo full-text denominato "bar" archiviato nella directory
c:\db\ftdata\bar
I seguenti sono i metadati dello scrittore del database:
Componente filegroup a livello di database
File del database primario:
ComponentType: VSS_CT_FILEGROUP
LogicalPath: "Server1\Instance1"
ComponentName: "DB1"
Caption: NULL
pbIcon: NULL
cbIcon: 0
bRestoreMetadata: FALSE
NotifyOnBackupComplete: TRUE
Selectable: TRUE
SelectableForRestore: TRUE
ComponentFlags: VSS_CF_APP_ROLLBACK_RECOVERY
File del database secondario:
LogicalPath: "Server1\Instance1"
GroupName: "DB1"
Path: "c:\db"
FileSpec: "DB1.mdf"
Recursive: FALSE
AlternatePath: NULL
BackupTypeMask: VSS_FSBT_ALL_BACKUP_REQUIRED | VSS_FSBT_ALL_SNAPSHOT_REQUIRED
Filegroup file
LogicalPath: "Server1\Instance1"
GroupName: "DB1"
Path: "c:\db"
FileSpec: "DB1.ndf"
Recursive: FALSE
AlternatePath: NULL
BackupTypeMask: VSS_FSBT_ALL_BACKUP_REQUIRED | VSS_FSBT_ALL_SNAPSHOT_REQUIRED
Registro dei file testo completo:
LogicalPath: "Server1\Instance1"
GroupName: "DB1"
Path: "c:\db"
FileSpec: "DB1.ldf"
Recursive: FALSE
AlternatePath: NULL
BackupTypeMask: VSS_FSBT_ALL_BACKUP_REQUIRED | VSS_FSBT_ALL_SNAPSHOT_REQUIRED
File full-text: foo
LogicalPath: "Server1\Instance1"
GroupName: "DB1"
Path: "c:\db\ftdata\foo"
FileSpec: "*"
Recursive: TRUE
AlternatePath: NULL
BackupTypeMask: VSS_FSBT_ALL_BACKUP_REQUIRED | VSS_FSBT_ALL_SNAPSHOT_REQUIRED
Barra dei file full-text:
LogicalPath: "Server1\Instance1"
GroupName: "DB1"
Path: "c:\db\ftdata\bar"
FileSpec: "*"
Recursive: TRUE
AlternatePath: NULL
BackupTypeMask: VSS_FSBT_ALL_BACKUP_REQUIRED | VSS_FSBT_ALL_SNAPSHOT_REQUIRED
Se l'istanza del server è l'istanza predefinita nel computer, il percorso logico diventa una parte: Server1.
Casi speciali
Questa sezione descrive alcuni dei casi speciali rilevati durante le operazioni di backup e ripristino basate sul writer SQL.
Database con chiusura automatica
Per i backup non suddivisi in componenti, la chiusura automatica dei database viene eseguita durante il controllo delle condizioni di incoerenza, ma i database chiusi automaticamente non vengono congelati esplicitamente durante le operazioni di backup.
Lo scenario previsto è che potrebbero esistere molti database chiusi e si vuole ridurre al minimo il costo dello snapshot. I database chiusi automaticamente vengono in genere usati nelle configurazioni di base in cui le risorse sono limitate.
Elenco di file
L'elenco dei file per ogni database viene determinato durante un passaggio di enumerazione prima dell'evento Prepare for Backup. Se l'elenco dei file di database cambia tra l'enumerazione e il congelamento, il database potrebbe essere corrotto, a meno che l'applicazione non ricontrolli l'elenco dei file. Anche se questo scenario è improbabile, è qualcosa di cui i fornitori devono essere a conoscenza.
Istanze arrestate
Se un'istanza di SQL Server non è in esecuzione nel momento in cui si verifica il passaggio di enumerazione, non è possibile selezionare nessuno dei database per tali istanze.
Se un'istanza si arresta nell'intervallo tra l'enumerazione e l'evento di preparazione del backup, i database nell'istanza arrestata verranno ignorati.
Database di sistema e utente
I database di sistema in SQL Server includono i masterdatabase , modele msdb forniti e installati come parte di SQL Server. Questa sezione descrive come questi database vengono gestiti in un snapshot di backup VSS.
Il master database può essere ripristinato solo arrestando l'istanza, sostituendo i file di database (eseguiti dall'applicazione di backup), quindi riavviando l'istanza. Non è possibile alcun avanzamento.
Il writer SQL supporta il ripristino online di entrambi i database model e msdb, senza arrestare l'istanza.
Contenuto correlato
- Log di SQL Server VSS Writer
- BACKUP (Transact-SQL)
- Istruzioni RESTORE (Transact-SQL)
- Backup e ripristino di database SQL Server
- Backup di sola copia
- Backup del log delle transazioni (SQL Server)
- Applicare backup di log delle transazioni (SQL Server)
- Guida all’architettura e alla gestione del log delle transazioni di SQL Server