Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server
SQL Server
Uno snapshot del database è una visualizzazione statica di sola lettura di un database di SQL Server (database di origine). È coerente in modo transazionale con il database di origine a partire dalla creazione dello snapshot e risiede sempre nella stessa istanza del server del database di origine. Sebbene gli snapshot del database offrano una visualizzazione di sola lettura dei dati nello stesso stato in cui è stato creato lo snapshot, le dimensioni del file di snapshot aumentano man mano che vengono apportate modifiche al database di origine.
Anche se gli snapshot del database possono essere utili durante gli aggiornamenti principali dello schema e consentire il ripristino di uno stato precedente, è fondamentale comprendere che gli snapshot non sostituiscono la necessità di backup regolari. Non è possibile eseguire il backup o il ripristino degli snapshot del database, il che significa che devono essere usati con una strategia di backup affidabile per garantire la protezione e il ripristino dei dati in caso di perdita o danneggiamento dei dati.
Gli snapshot del database vengono creati con la sintassi T-SQLCREATE DATABASE usando la sintassi AS SNAPSHOT OF.
È possibile generare più snapshot di uno stesso database di origine. Ogni snapshot del database persiste fino a quando il proprietario del database non lo elimina in modo esplicito.
Nota
Gli snapshot del database non sono correlati a backup di snapshot, backup di snapshot di Transact-SQL, transazioni o isolamento dello snapshot o replica snapshot.
Panoramica delle funzionalità
Gli snapshot del database operano a livello delle pagine di dati. Prima che una pagina del database di origine venga modificata per la prima volta, la pagina originale viene copiata dal database di origine allo snapshot. Nello snapshot viene archiviata la pagina originale, mantenendo i record di dati nello stato corrispondente al momento in cui è stato creato lo snapshot. Lo stesso processo viene ripetuto per ogni pagina da modificare per la prima volta. All'utente, uno snapshot del database appare immutabile perché le operazioni di lettura accedono sempre alle pagine di dati originali, indipendentemente dalla loro posizione.
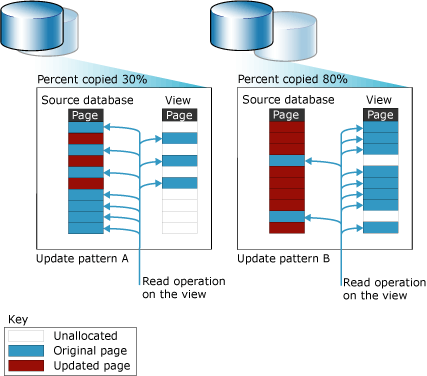
Lo snapshot archivia le pagine originali copiate usando uno o più file sparsi . Inizialmente, un file sparse è un file vuoto che non contiene dati utente e non è ancora stato allocato spazio su disco per i dati utente. Le dimensioni del file aumentano man mano che vengono aggiornate più pagine nel database di origine. Nella figura seguente vengono illustrati gli effetti di due modelli di aggiornamento diversi sulle dimensioni di uno snapshot. Il modello di aggiornamento A rappresenta un ambiente in cui solo il 30% delle pagine originali è stato aggiornato durante la vita dello snapshot. Il modello di aggiornamento B rappresenta un ambiente in cui durante la vita dello snapshot è stato aggiornato l'80% delle pagine originali.
Benefici
È possibile utilizzare gli snapshot per la generazione di report.
- I client possono eseguire query su uno snapshot del database, che consente di scrivere report in base ai dati quando viene creato lo snapshot.
Mantenimento dei dati cronologici per la generazione di report.
- Uno snapshot consente di estendere l'accesso utente ai dati relativi a un momento determinato. Ad esempio, è possibile creare uno snapshot del database per la creazione di report successivi alla fine di un determinato periodo, ad esempio un trimestre finanziario. ed eseguire report di fine periodo sullo snapshot. Se lo spazio su disco lo consente, è anche possibile gestire snapshot di fine periodo a tempo indeterminato, consentendo di effettuare query sui risultati di questi periodi, ad esempio, per analizzare le prestazioni dell'organizzazione.
Utilizzare un database mirror che mantieni per scopi di disponibilità per scaricare i report.
- L'utilizzo degli snapshot del database con il mirroring del database consente di rendere disponibili per la creazione di report i dati archiviati nel server mirror. Inoltre, l'esecuzione di query sul database mirror può liberare risorse per il principale. Per altre informazioni , vedere Mirroring e snapshot del database (SQL Server).
Salvaguardia dei dati da errori amministrativi.
Se si verifica un errore utente in un database di origine, è possibile ripristinarne lo stato quando viene creato uno snapshot del database. La perdita di dati è limitata agli aggiornamenti del database eseguiti dopo la creazione dello snapshot.
Ad esempio, prima di eseguire aggiornamenti principali, ad esempio un aggiornamento in blocco o una modifica dello schema, creare uno snapshot del database nel database per proteggere i dati. In caso di errore è possibile utilizzare lo snapshot per il recupero, riportando il database allo stato memorizzato nello snapshot. Tornare a uno stato precedente è più veloce rispetto al ripristino da un backup; tuttavia, non è possibile avanzare successivamente.
Importante
Non è possibile eseguire il ripristino di un database offline o danneggiato. Pertanto, sono necessari backup regolari e test del piano di ripristino per proteggere un database.
Nota
Gli snapshot del database dipendono dal database di origine. Pertanto, l'uso di snapshot per ripristinare un database non sostituisce la strategia di backup e ripristino. L'esecuzione di tutti i backup pianificati rimane comunque essenziale. Se è necessario ripristinare il database di origine fino al punto in cui è stato creato uno snapshot del database, implementare un criterio di backup che consenta di eseguire questa operazione.
Salvaguardia dei dati da errori degli utenti.
Creando regolarmente snapshot del database, è possibile ridurre l'impatto di un errore utente principale, ad esempio una tabella eliminata. Per assicurare un livello elevato di protezione, è possibile creare una serie di snapshot del database, relativi a un intervallo di tempo sufficiente per riconoscere e rispondere alla maggior parte degli errori da parte degli utenti. Ad esempio, a seconda delle risorse del disco, è possibile mantenere da 6 a 12 snapshot in sequenza che si estendono su un intervallo di 24 ore. Ogni volta che viene creato un nuovo snapshot è possibile eliminare lo snapshot meno recente.
Per il recupero dopo un errore da parte degli utenti, è possibile riportare il database allo stato registrato nello snapshot immediatamente precedente l'errore. Il ripristino è potenzialmente molto più veloce rispetto al ripristino da un backup; Tuttavia, non è possibile eseguire il rollforward in un secondo momento.
In alternativa, è possibile ricostruire manualmente una tabella eliminata o altri dati persi dalla snapshot. Ad esempio, è possibile copiare in blocco i dati dallo snapshot nel database e reintegrare manualmente i dati nel database.
Nota
Il numero di snapshot simultanei necessari in un database, la frequenza per la creazione di un nuovo snapshot e il tempo di memorizzazione degli snapshot dipendono dalle ragioni per cui si decide di utilizzare gli snapshot del database.
Gestione di un database di prova.
- In un ambiente di test può essere utile per il database contenere dati identici all'inizio di ogni round di test quando si esegue ripetutamente un protocollo di test. Prima di eseguire il primo round, uno sviluppatore di applicazioni o un tester può creare uno snapshot del database di test. Dopo ogni test, sarà possibile ripristinare rapidamente lo stato precedente del database ripristinando il relativo snapshot.
Termini e definizioni
Gli snapshot del database in SQL Server prevedono diversi termini chiave e definizioni. Un'istantanea del database è una visione statica di sola lettura di un database (indicata come database di origine ) in un momento specifico. Il database di origine è il database originale su cui si basa lo snapshot e deve rimanere online e accessibile affinché lo snapshot sia utilizzabile. I file Sparse archiviano le pagine originali del database di origine che sono state modificate dopo la creazione dello snapshot. Questi file sono inizialmente vuoti e aumentano man mano che si verificano modifiche nel database di origine. Comprendere questi termini è essenziale per gestire e usare in modo efficace gli snapshot del database in SQL Server.
Snapshot del database
Vista statica, di sola lettura e consistente dal punto di vista transazionale di un database (di origine).
Database di origine
Per uno snapshot del database, il database del quale è stato creato lo snapshot. Gli snapshot del database dipendono dal database di origine. Gli snapshot di un database devono essere inclusi nella stessa istanza del server del database. Inoltre, se il database non è più disponibile per qualsiasi motivo, gli snapshot diventano non disponibili.
File sparse
Il file system NTFS fornisce un file che richiede molto meno spazio su disco rispetto a quanto altrimenti necessario. Un file di tipo sparse viene utilizzato per archiviare pagine copiate in uno snapshot del database. Un file di tipo sparse appena creato richiede poco spazio su disco. Man mano che i dati vengono scritti in uno snapshot del database, lo spazio su disco viene allocato gradualmente dal file system NTFS nel file di tipo sparse corrispondente.
Prerequisiti
Il database di origine, in cui può essere utilizzato qualsiasi modello di recupero, deve soddisfare i prerequisiti seguenti:
L'istanza del server deve essere eseguita in un'edizione di SQL Server che supporta gli snapshot del database.
- Per altre informazioni, vedere Funzionalità supportate dalle edizioni di SQL Server 2016.
Il database di origine deve essere online, a meno che non si tratti di un database mirror all'interno di una sessione di mirroring del database.
È possibile creare uno snapshot del database in un gruppo di disponibilità in qualsiasi database primario o secondario. Il ruolo di replica deve essere PRIMARY o SECONDARY, non nello stato di RESOLVING.
È consigliabile uno stato di sincronizzazione del database corrispondente a SYNCHRONIZING o SYNCHRONIZED quando si crea uno snapshot del database. Tuttavia, gli snapshot del database possono essere creati quando lo stato non è SYNCHRONIZING.
- Per altre informazioni, vedere Snapshot del database con gruppi di disponibilità Always On (SQL Server).
Per creare uno snapshot del database in un database mirror, è necessario che il database si trovi nello stato di mirroring SYNCHRONIZED.
Il database di origine non può essere configurato come database condiviso scalabile.
Prima di SQL Server 2019, il database di origine non poteva contenere un filegroup MEMORY_OPTIMIZED_DATA. Il supporto per gli snapshot del database in memoria è stato aggiunto a SQL Server 2019.
Tutti i modelli di recupero supportano gli snapshot del database.
Limitazioni del database di origine
In presenza di snapshot del database, al database di origine dello snapshot si applicano le limitazioni seguenti:
Non è possibile eliminare, scollegare o ripristinare il database.
Il backup del database di origine funziona in genere, ma non è interessato dagli snapshot del database.
Le prestazioni sono ridotte a causa di un aumento delle operazioni di I/O nel database di origine risultante da un'operazione di copia su scrittura allo snapshot ogni volta che viene aggiornata una pagina.
Non è possibile eliminare i file dal database di origine o dagli snapshot.
Limitazioni per gli snapshot del database
Gli snapshot del database dipendono dal database di origine e non proteggono da errori o danneggiamenti del disco. Pertanto, anche se possono essere utili per la creazione di report o durante le modifiche dello schema, devono integrare, non sostituire, procedure di backup regolari. Se è necessario ripristinare il database di origine fino al punto in cui è stato creato uno snapshot del database, implementare un criterio di backup che consenta di eseguire questa operazione.
Agli snapshot del database si applicano le limitazioni seguenti:
È necessario creare e mantenere uno snapshot del database sulla stessa istanza del server in cui si trova il database di origine.
Gli snapshot del database includono sempre un intero database.
Gli snapshot del database dipendono dal database di origine e non sono risorse di archiviazione ridondanti. Non proteggono da errori del disco o da altri tipi di danneggiamento. Pertanto, l'uso degli snapshot per ripristinare un database non è un sostituto della strategia di backup e ripristino. L'esecuzione di tutti i backup pianificati rimane comunque essenziale. Se è necessario ripristinare il database di origine fino al punto in cui è stato creato uno snapshot del database, implementare un criterio di backup che consenta di eseguire questa operazione.
Quando una pagina che viene aggiornata nel database di origine viene trasferita a uno snapshot, se lo snapshot esaurisce lo spazio su disco o rileva un altro errore, diventa sospetto e deve essere eliminato.
Gli snapshot sono di sola lettura. Poiché sono di sola lettura, non possono essere aggiornati. Gli snapshot del database non devono pertanto essere validi dopo un aggiornamento.
Gli snapshot dei database
model,masteretempdbnon sono consentiti.Non è possibile modificare alcuna specifica dei file di snapshot del database.
Non è possibile eliminare i file da uno snapshot del database.
Non è possibile eseguire il backup o il ripristino degli snapshot del database.
Non è possibile collegare o scollegare gli snapshot del database.
Non è possibile creare snapshot di database nel file system FAT32 o nelle partizioni RAW. Il file system NTFS fornisce i file sparsi usati dagli snapshot del database.
L'indicizzazione full-text non è supportata per gli snapshot del database. I cataloghi full-text non vengono propagati dal database di origine.
Uno snapshot del database eredita i vincoli di sicurezza del proprio database di origine esistenti al momento della creazione dello snapshot. Poiché gli snapshot sono di sola lettura, le autorizzazioni ereditate non possono essere modificate e le modifiche alle autorizzazioni apportate all'origine non verranno riflesse negli snapshot esistenti.
Uno snapshot riflette sempre lo stato dei filegroup al momento della sua creazione. I filegroup online e quelli offline non modificano il proprio stato. Per ulteriori informazioni, vedere più avanti in questo articolo "Screenshot del database con filegroup offline".
Se un database di origine diventa RECOVERY_PENDING, gli snapshot potrebbero diventare inaccessibili. Tuttavia, dopo la risoluzione del problema nel database di origine, gli snapshot devono diventare nuovamente disponibili.
Il ripristino non è supportato per qualsiasi file NTFS di sola lettura o compresso nel database. I tentativi di ripristinare un database contenente uno di questi tipi di filegroup hanno esito negativo.
In una configurazione per il log shipping, gli snapshot del database possono essere creati solo nel database primario, non in quello secondario. Si supponga di cambiare i ruoli tra le istanze del server primario e secondario. In tal caso, è necessario eliminare tutti gli snapshot del database prima di configurare il database primario come secondario.
Un'istantanea del database non può essere configurata come database condiviso scalabile.
Gli snapshot del database non supportano i filegroup FILESTREAM. Se i filegroup FILESTREAM sono presenti in un database di origine, vengono contrassegnati come offline negli snapshot del database e gli snapshot non possono essere usati per ripristinare il database.
Nota
Un'istruzione SELECT eseguita in uno snapshot del database non deve specificare una colonna FILESTREAM. In caso contrario, verrà restituito il seguente messaggio di errore: Could not continue scan with NOLOCK due to data movement.
- Se le statistiche relative a uno snapshot di sola lettura mancano o non sono aggiornate, il motore di database crea e gestisce statistiche temporanee in
tempdb. Per altre informazioni, vedere Statistiche.
Spazio su disco
Gli snapshot del database richiedono spazio su disco. Se uno snapshot del database esaurisce lo spazio su disco, viene contrassegnato come sospetto e deve essere eliminato. Il database di origine, tuttavia, non è interessato; le azioni su di essa continuano normalmente.
Tuttavia, gli snapshot sono altamente efficienti in termini di spazio rispetto a una copia completa di un database. Uno snapshot richiede esclusivamente lo spazio necessario per le pagine che vengono modificate durante la sua durata. In genere, gli snapshot vengono mantenuti per un periodo di tempo limitato, quindi le dimensioni non rappresentano un problema significativo.
Tuttavia, più a lungo si mantiene uno snapshot, più è probabile che si consumi spazio disponibile. La dimensione massima in base alla quale un file sparse può aumentare è la dimensione corrispondente del file di database di origine al momento della creazione dello snapshot. Se si esaurisce lo spazio su disco, è necessario eliminare uno snapshot del database.
Nota
Tranne che per lo spazio del file, uno snapshot del database utilizza approssimativamente le stesse risorse di un database.
Gruppi di file offline
I filegroup offline nel database di origine influenzano gli snapshot del database quando si tenta di eseguire una delle operazioni seguenti:
Creare uno snapshot.
- Quando nel database di origine sono presenti uno o più filegroup offline, la creazione degli snapshot ha esito positivo con i filegroup offline. I file sparse non vengono creati per i filegroup offline.
Portare un filegroup offline
- È possibile portare un file offline nel database di origine. Tuttavia, il filegroup rimane online negli snapshot del database se era tale alla creazione dello snapshot. Se i dati sottoposti a query sono stati modificati dopo la creazione dello snapshot, la pagina dei dati originale è accessibile nello snapshot. Tuttavia, è possibile che, per le query che utilizzano lo snapshot per l'accesso ai dati non modificati nel filegroup, si verifichino errori di input/output (I/O).
Portare un filegroup online
- Non è possibile portare online un filegroup in un database che abbia qualsiasi istantanea del database. Se un filegroup è offline al momento della creazione di snapshot o viene portato offline mentre esiste uno snapshot del database, rimane offline. Ciò è dovuto al fatto che riportare un file online comporta un ripristino, il che non è possibile se esiste uno snapshot nel database.
Ripristinare lo snapshot come database di origine
- Il ripristino di un database di origine a uno snapshot del database richiede che tutti i filegroup siano online, ad eccezione di quelli offline al momento della creazione dello snapshot.
Contenuto correlato
- Mirroring e snapshot del database (SQL Server)
- CREATE DATABASE - Snapshot del database
- Creare uno snapshot del database (Transact-SQL)
- Visualizzare uno snapshot del database (SQL Server)
- Visualizzare le dimensioni del file sparse di uno snapshot del database (Transact-SQL)
- Ripristinare un database a uno snapshot del database
- Eliminare uno snapshot del database (Transact-SQL)