Diagnosticare e risolvere una contesa di latch in SQL Server
Questa guida illustra come identificare e risolvere i problemi relativi alla contesa di latch osservati durante l'esecuzione di applicazioni SQL Server in sistemi con concorrenza elevata con determinati carichi di lavoro.
Poiché il numero di core CPU nei server continua ad aumentare, il conseguente aumento della concorrenza può introdurre punti di contesa nelle strutture dei dati a cui è necessario accedere in modo seriale all'interno del motore di database. Questo vale in particolare per i carichi di lavoro di elaborazione delle transazioni (OLTP) a velocità effettiva elevata/concorrenza elevata. È possibile affrontare queste sfide con diversi strumenti, tecniche e modi, ma è anche possibile evitarle del tutto seguendo alcune procedure che possono aiutare la progettazione delle applicazioni. Questo articolo illustra un tipo specifico di contesa nelle strutture dei dati che usano gli spinlock per serializzare l'accesso a queste strutture dei dati.
Nota
Il contenuto di questo articolo è stato scritto dal Team di consulenza clienti di Microsoft SQL Server (SQLCAT) sulla base del processo di identificazione e risoluzione dei problemi relativi alla contesa di latch di pagina nelle applicazioni SQL Server in sistemi a concorrenza elevata. Le raccomandazioni e le procedure consigliate illustrate in questo articolo si basano sull'esperienza reale di sviluppo e distribuzione di sistemi OLTP reali.
Che cos'è la contesa di latch di SQL Server?
I latch sono primitive di sincronizzazione leggere usate dal motore di SQL Server per garantire la coerenza delle strutture in memoria, inclusi indici, pagine di dati e strutture interne, ad esempio pagine non foglia in un albero B. SQL Server usa i latch di buffer per proteggere le pagine nel pool di buffer e i latch di I/O per proteggere le pagine non ancora caricate nel pool di buffer. Ogni volta che i dati vengono scritti o letti in una pagina nel pool di buffer di SQL Server, un thread di lavoro deve prima acquisire un latch di buffer per la pagina. Sono disponibili vari tipi di latch di buffer per l'accesso alle pagine nel pool di buffer, inclusi il latch esclusivo (PAGELATCH_EX) e il latch condiviso (PAGELATCH_SH). Quando SQL Server prova ad accedere a una pagina che non è già presente nel pool di buffer, viene eseguita un'operazione di I/O asincrona per caricare la pagina nel pool di buffer. Se SQL Server deve attendere la risposta del sottosistema di I/O, resterà in attesa di un latch di I/O esclusivo (PAGEIOLATCH_EX) o condiviso (PAGEIOLATCH_SH), a seconda del tipo di richiesta. Lo scopo è impedire a un altro thread di lavoro di caricare la stessa pagina nel pool di buffer con un latch non compatibile. I latch vengono usati anche per proteggere l'accesso alle strutture di memoria interne diverse dalle pagine del pool di buffer. Tali latch sono noti come latch non di buffer.
L'argomento principale di questo articolo è la contesa per i latch di pagina, che è lo scenario più comune rilevato nei sistemi con più CPU.
La contesa di latch si verifica quando più thread provano ad acquisire simultaneamente latch non compatibili nella stessa struttura in memoria. Poiché il latch è un meccanismo di controllo interno, il motore di SQL determina automaticamente quando usarli. Poiché il comportamento dei latch è deterministico, le decisioni correlate alle applicazioni, ad esempio la progettazione dello schema, possono influire su questo funzionamento. Questo articolo contiene le informazioni seguenti:
- Informazioni generali su come i latch vengono usati da SQL Server.
- Strumenti usati per individuare la causa della contesa di latch.
- Come determinare se l'entità della contesa osservata è problematica.
Verranno illustrati alcuni scenari comuni e verrà spiegato come gestirli al meglio per attenuare la contesa.
In che modo SQL Server usa i latch?
Una pagina in SQL Server ha dimensioni pari a 8 KB e può archiviare più righe. Per aumentare la concorrenza e le prestazioni, i latch di buffer vengono mantenuti solo per la durata dell'operazione fisica sulla pagina, a differenza dei blocchi, che vengono mantenuti per la durata della transazione logica.
I latch sono interni al motore di SQL e vengono usati per garantire la coerenza della memoria, mentre i blocchi vengono usati da SQL Server per garantire la coerenza transazionale logica. Nella tabella seguente vengono messi a confronto latch e blocchi:
| Struttura | Scopo | Controllato da | Costo delle prestazioni | Esposto da |
|---|---|---|---|---|
| Latch | Garantire la coerenza delle strutture in memoria. | Solo motore di SQL Server. | Il costo delle prestazioni è basso. Per consentire la massima concorrenza e garantire prestazioni ottimali, i latch vengono mantenuti solo per la durata dell'operazione fisica sulla struttura in memoria, a differenza dei blocchi, che vengono mantenuti per la durata della transazione logica. | sys.dm_os_wait_stats (Transact-SQL) - Fornisce informazioni sui tipi di attesa PAGELATCH, PAGEIOLATCH e LATCH. LATCH_EX e LATCH_SH vengono usati per raggruppare tutte le attese latch non di buffer. sys.dm_os_latch_stats (Transact-SQL) - Fornisce informazioni dettagliate sulle attese latch non di buffer. sys.dm_db_index_operational_stats (Transact-SQL) - Questa DMV fornisce attese aggregate per ogni indice, facilitando la risoluzione dei problemi di prestazioni correlati ai latch. |
| Blocca | Garantire la coerenza delle transazioni. | Può essere controllato dall'utente. | Il costo delle prestazioni è elevato rispetto ai latch perché i blocchi devono essere mantenuti per la durata della transazione. | sys.dm_tran_locks (Transact-SQL). sys.dm_exec_sessions (Transact-SQL). |
Modalità e compatibilità dei latch di SQL Server
Si deve prevedere una contesa di latch come parte del normale funzionamento del motore di SQL Server. È inevitabile che in un sistema a concorrenza elevata vengano eseguite più richieste di latch simultanee per la compatibilità variabile. SQL Server applica la compatibilità con latch imponendo alle richieste di latch non compatibili di attendere in una coda fino al completamento delle richieste di latch in attesa.
I latch possono essere acquisiti in cinque diverse modalità, che si distinguono per il livello di accesso. Le modalità di latch di SQL Server possono essere riepilogate come segue:
KP (Keep) - Latch conservativo, assicura che la struttura di riferimento non possa essere eliminata definitivamente. Viene usato quando un thread vuole esaminare una struttura di buffer. Poiché il latch KP è compatibile con tutti i latch tranne che con il latch di eliminazione (DT), il latch KP viene considerato "leggero", perché l'effetto sulle prestazioni quando lo si usa è minimo. Il latch KP, non essendo compatibile con il latch DT, impedirà a qualsiasi altro thread di eliminare definitivamente la struttura di riferimento. Un latch KP, ad esempio, impedirà che la struttura a cui fa riferimento venga eliminata definitivamente dal processo lazywriter. Per altre informazioni su come il processo lazywriter viene usato con la gestione delle pagine di buffer di SQL Server, vedere Scrittura di pagine.
SH - Latch condiviso necessario per leggere la struttura a cui si fa riferimento (ad es., leggere una pagina di dati). Più thread possono accedere contemporaneamente a una risorsa per la lettura in un latch condiviso.
UP (Update) - Latch di aggiornamento. Poiché è compatibile con SH (latch condiviso) e KP, ma con nessun altro, non consentirà a un latch EX di scrivere nella struttura di riferimento.
EX (Exclusive) - Latch esclusivo. Impedisce agli altri thread di scrivere o di leggere nella struttura di riferimento. Può essere usato, ad esempio, per modificare il contenuto di una pagina per la protezione delle pagine incomplete.
DT (Destroy) - Latch di eliminazione. Deve essere acquisito prima di eliminare definitivamente il contenuto della struttura di riferimento. Un latch DT, ad esempio, deve essere acquisito dal processo lazywriter per liberare una pagina pulita prima di aggiungerla all'elenco di buffer liberi disponibili che possono essere usati da altri thread.
Le modalità dei latch hanno livelli di compatibilità diversi. Un latch condiviso (SH), ad esempio, è compatibile con un latch di aggiornamento (UP) o conservativo (KP), ma è incompatibile con un latch di eliminazione (DT). È possibile acquisire contemporaneamente più latch nella stessa struttura purché i latch siano compatibili. Quando un thread prova ad acquisire un latch mantenuto in una modalità non compatibile, viene inserito in una coda in attesa di un segnale indicante che la risorsa è disponibile. Uno spinlock di tipo SOS_Task viene usato per proteggere la coda di attesa applicando l'accesso serializzato alla coda. Questo spinlock deve essere acquisito per aggiungere elementi alla coda. Lo spinlock SOS_Task segnala anche ai thread della coda quando vengono rilasciati latch non compatibili, consentendo ai thread in attesa di acquisire un latch compatibile e di continuare a funzionare. La coda di attesa viene elaborata in base al criterio FIFO (First In, First Out) mentre vengono rilasciate le richieste di latch. I latch seguono questo sistema FIFO per garantire l'equità ed evitare la mancanza di thread.
La compatibilità delle modalità dei latch è illustrata nella tabella seguente. S indica compatibilità e N indica incompatibilità:
| Modalità latch | KP | SH | UP | EX | DT |
|---|---|---|---|---|---|
| KP | S | Y | Y | Y | N |
| SH | S | Y | Y | N | N |
| UP | S | Y | N | N | N |
| EX | Y | N | N | N | N |
| DT | N | N | N | N | N |
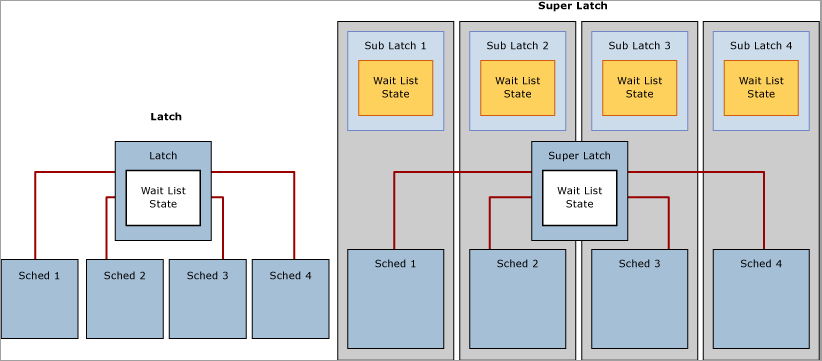
Superlatch e sublatch di SQL Server
Dato il numero sempre più elevato di sistemi con più socket/multicore basati su NUMA, in SQL Server 2005 sono stati introdotti i superlatch, noti anche come sublatch, che risultano efficaci solo nei sistemi con 32 o più processori logici. I superlatch migliorano l'efficienza del motore SQL per determinati modelli di utilizzo nei carichi di lavoro OLTP a concorrenza elevata, ad esempio quando determinate pagine hanno un modello di accesso condiviso (SH) con intensa attività di sola lettura, ma vi vengono eseguite raramente operazioni di scrittura. Un esempio di pagina con un modello di accesso di questo tipo è la pagina radice di un albero B (ad esempio, l'indice). Il motore di SQL richiede che venga mantenuto un latch condiviso sulla pagina radice quando si verifica una divisione di pagina a qualsiasi livello nell'albero B. In un carico di lavoro OLTP a concorrenza elevata e con un'attività di inserimento intensa, il numero di divisioni di pagina aumenterà considerevolmente in linea con la velocità effettiva, il che può compromettere le prestazioni. I superlatch consentono il miglioramento delle prestazioni per l'accesso a pagine condivise in cui più thread di lavoro in esecuzione simultaneamente richiedono latch SH. A questo scopo, il motore di SQL Server promuoverà dinamicamente un latch su tale pagina a superlatch. Un superlatch partiziona un singolo latch in una matrice di strutture di sublatch, con un sublatch per partizione per ogni core CPU, in cui il latch principale diventa un redirector del proxy e la sincronizzazione dello stato globale non è necessaria per i latch di sola lettura. In questo modo, il thread di lavoro, che viene sempre assegnato a una CPU specifica, deve solo acquisire il sublatch condiviso (SH) assegnato all'utilità di pianificazione locale.
Nota
Nella documentazione di SQL Server viene usato in modo generico il termine albero B in riferimento agli indici. Negli indici rowstore SQL Server implementa un albero B+. Questo non si applica agli indici columnstore o agli archivi dati in memoria. Per altre informazioni, vedere Architettura e guida per la progettazione degli indici di SQL Server e Azure SQL.
L'acquisizione di latch compatibili, ad esempio un superlatch condiviso, usa meno risorse e dimensiona l'accesso alle pagine a cui si accede di frequente in modo più efficiente rispetto a un latch condiviso non partizionato perché, grazie alla rimozione del requisito di sincronizzazione dello stato globale e all'accesso alla sola memoria NUMA locale, le prestazioni migliorano considerevolmente. Al contrario, l'acquisizione di un superlatch esclusivo (EX) è più costosa dell'acquisizione di un normale latch EX perché SQL deve inviare un segnale in tutti i sublatch. Quando un superlatch usa un modello di accesso EX intenso, il motore di SQL può abbassarlo di livello dopo che la pagina è stata rimossa dal pool di buffer. Il diagramma seguente illustra un latch normale e un superlatch partizionato:
Usare l'oggetto SQL Server:Latches e i contatori associati in Monitor prestazioni per raccogliere informazioni sui superlatch, inclusi il numero di superlatch, le promozioni a superlatch al secondo e gli abbassamenti di livello dei superlatch al secondo. Per altre informazioni sull'oggetto SQL Server:Latches e sui contatori associati, vedere Oggetto Latch di SQL Server.
Tipi di attesa latch
SQL Server tiene traccia delle informazioni cumulative sull'attesa, a cui è possibile accedere usando la DMW sys.dm_os_wait_stats. SQL Server usa tre tipi di attesa latch definiti dal corrispondente wait_type DMV sys.dm_os_wait_stats:
Latch di buffer (BUF): usato per garantire la coerenza delle pagine di indice e di dati per gli oggetti utente. Vengono usati anche per proteggere l'accesso alle pagine di dati usate da SQL Server per gli oggetti di sistema. Ad esempio, le pagine che gestiscono le allocazioni sono protette da latch di buffer, incluse le pagine PFS (Page Free Space), GAM (Global Allocation Map), SGAM (Shared Global Allocation Map) e IAM (Index Allocation Map). I latch di buffer vengono segnalati in
sys.dm_os_wait_statscon unwait_typedi PAGELATCH_*.Latch non di buffer (non-BUF): usato per garantire la coerenza di qualsiasi struttura in memoria diversa dalle pagine del pool di buffer. Le attese di latch non di buffer saranno indicate come
wait_typedi LATCH_*.Latch di I/O: un subset di latch di buffer che garantisce la coerenza delle stesse strutture protette dai latch di buffer quando queste strutture richiedono il caricamento nel pool di buffer con un'operazione di I/O. I latch di I/O impediscono a un altro thread di caricare la stessa pagina nel pool di buffer con un latch non compatibile. Associato a un
wait_typedi PAGEIOLATCH_*.Nota
Se si osserva un numero elevato di attese PAGEIOLATCH, significa che SQL Server è in attesa del sottosistema di I/O. Anche se una certa quantità di attese PAGEIOLATCH è un comportamento normale e previsto, se il tempo medio delle attese PAGEIOLATCH è costantemente superiore a 10 millisecondi (ms), è consigliabile determinare per quale motivo il sottosistema di I/O è sotto pressione.
Se quando si esamina la DMW sys.dm_os_wait_stats si rilevano latch non di buffer, è necessario esaminare sys.dm_os_latch_stats per ottenere il dettaglio delle informazioni cumulative sull'attesa per i latch non di buffer. Tutte le attese latch di buffer rientrano nella classe latch BUFFER, mentre le rimanenti vengono usate per classificare i latch non di buffer.
Sintomi e cause della contesa di latch di SQL Server
In un sistema a concorrenza elevata occupato, è normale osservare una contesa attiva per le strutture a cui si accede di frequente e che sono protette dai latch e da altri meccanismi di controllo in SQL Server. Il problema sorge quando la contesa e il tempo di attesa associati all'acquisizione del latch per una pagina sono sufficienti a ridurre l'utilizzo delle risorse (CPU), compromettendo la velocità effettiva.
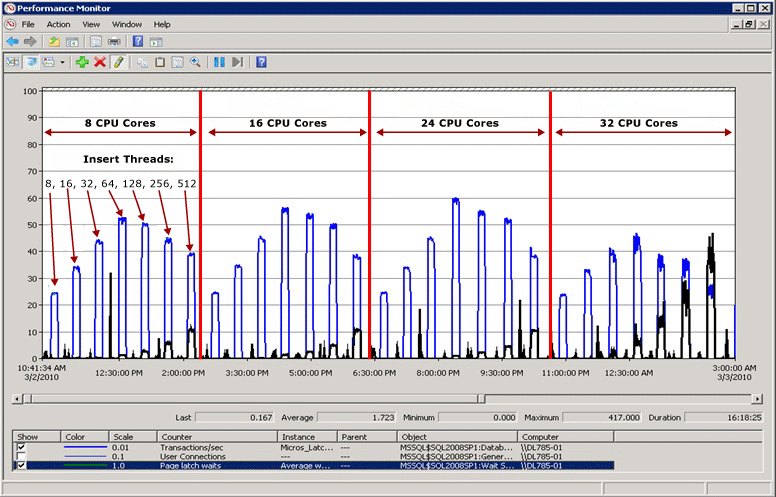
Esempio di contesa di latch
Nel diagramma seguente la linea blu rappresenta la velocità effettiva in SQL Server, misurata in base alle transazioni al secondo. La linea nera rappresenta il tempo medio di attesa latch della pagina. In questo caso, ogni transazione esegue un'operazione INSERT in un indice cluster con un valore iniziale che aumenta in modo sequenziale, ad esempio quando si popola una colonna IDENTITY del tipo di dati bigint. Poiché il numero di CPU aumenta fino a 32, è evidente che la velocità effettiva complessiva è diminuita e che il tempo di attesa latch della pagina è aumentato fino a circa 48 millisecondi, come dimostra la linea nera. Questa relazione inversa tra velocità effettiva e tempo di attesa latch della pagina è uno scenario comune facilmente diagnosticabile.
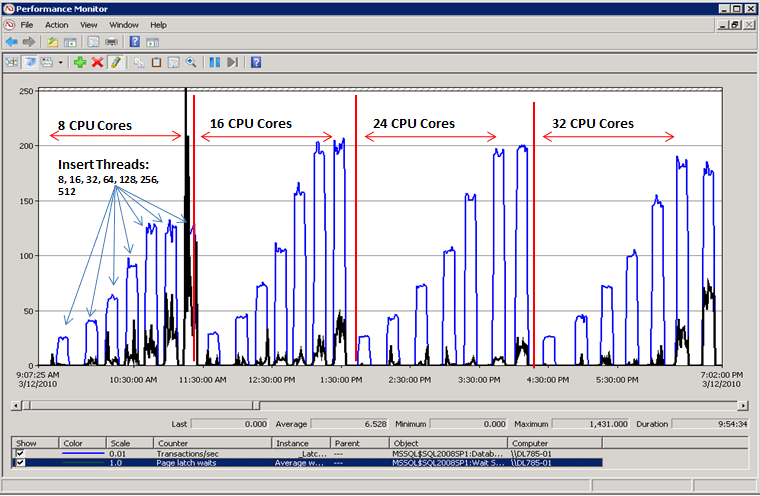
Prestazioni quando la contesa di latch viene risolta
Come illustra il diagramma seguente, in SQL Server non sono più presenti colli di bottiglia in corrispondenza delle attese latch della pagina e la velocità effettiva, misurata in transazioni al secondo, è aumentata del 300%. A questo scopo è stata usata la tecnica descritta più avanti in questo articolo in Usare il partizionamento hash con una colonna calcolata. Questo miglioramento delle prestazioni è diretto a sistemi con un numero elevato di core e un livello elevato di concorrenza.
Fattori che influiscono sulla contesa di latch
La contesa di latch che compromette le prestazioni negli ambienti OLTP è in genere causata da una concorrenza elevata correlata a uno o più dei fattori seguenti:
| Fattore | Dettagli |
|---|---|
| Numero elevato di CPU logiche usate da SQL Server | La contesa di latch può verificarsi in qualsiasi sistema multicore. Nell'esperienza con SQLCAT, una contesa di latch eccessiva, che influisce sulle prestazioni dell'applicazione oltre i livelli accettabili, è stata osservata soprattutto nei sistemi con più di 16 core CPU e potrebbe aumentare ulteriormente con un numero maggiore di core disponibili. |
| Progettazione di schemi e modelli di accesso | La profondità dell'albero B, la progettazione di indici cluster e non cluster, le dimensioni e la densità delle righe per pagina e i modelli di accesso (attività di lettura/scrittura/eliminazione) sono fattori che possono contribuire a una contesa di latch di pagina eccessiva. |
| Grado di concorrenza elevato a livello di applicazione | Una contesa di latch di pagina eccessiva si verifica in genere in concomitanza con un livello elevato di richieste simultanee dal livello applicazione. Esistono alcune procedure di programmazione che possono anche introdurre un numero elevato di richieste per una pagina specifica. |
| Layout di file logici usati dai database di SQL Server | Il layout dei file logici può influire sul livello di contesa di latch di pagina causato da strutture di allocazione come le pagine PFS (Page Free Space), GAM (Global Allocation Map), SGAM (Shared Global Allocation Map) e IAM (Index Allocation Map). Per altre informazioni, vedere Monitoraggio e risoluzione dei problemi di TempDB: collo di bottiglia di allocazione. |
| Prestazioni del sottosistema di I/O | Un numero elevato di attese PAGEIOLATCH indica che SQL Server è in attesa del sottosistema di I/O. |
Diagnosi della contesa di latch di SQL Server
Questa sezione contiene informazioni utili per la diagnosi della contesa di Latch di SQL Server per determinare se sia problematica per l'ambiente in uso.
Strumenti e metodi per la diagnosi della contesa di latch
I principali strumenti usati per diagnosticare la contesa di latch sono:
Monitor prestazioni per monitorare l'utilizzo della CPU e i tempi di attesa in SQL Server e stabilire se esiste una relazione tra l'utilizzo della CPU e i tempi di attesa latch.
Viste DMV di SQL Server, che possono essere usate per determinare il tipo specifico di latch che causa il problema e la risorsa interessata.
In alcuni casi, i dump della memoria del processo di SQL Server devono essere ottenuti e analizzati con gli strumenti di debug di Windows.
Nota
Questo livello di risoluzione dei problemi avanzata è in genere necessario solo per la risoluzione dei problemi relativi alla contesa di latch non di buffer. Per questo tipo di risoluzione dei problemi avanzata potrebbe essere necessario coinvolgere il Servizio Supporto Tecnico Clienti Microsoft.
I passaggi seguenti riepilogano il processo tecnico per la diagnosi della contesa di latch:
Determinare se è presente una contesa che può essere correlata ai latch.
Utilizzare le viste DMW fornite nell'Appendice: script per la contesa di latch di SQL Server per determinare il tipo di latch e le risorse interessate.
Ridurre la contesa usando una delle tecniche descritte in Gestione della contesa di latch per modelli di tabella diversi.
Indicatori di contesa di latch
Come indicato in precedenza, la contesa di latch costituisce un problema solo quando la contesa e il tempo di attesa associati all'acquisizione dei latch di pagina impediscono l'aumento della velocità effettiva quando sono disponibili risorse della CPU. Per stabilire un livello accettabile di contesa, è necessario un approccio olistico che consideri i requisiti di prestazioni e velocità effettiva, ma anche le risorse di I/O e CPU disponibili. Questa sezione illustra come determinare l'impatto della contesa di latch sul carico di lavoro, come indicato di seguito:
Misurare i tempi di attesa complessivi durante un test rappresentativo.
Classificarli in ordine di priorità.
Determinare la proporzione di quelli correlati ai latch.
Le informazioni cumulative sull'attesa sono disponibili nella DMV sys.dm_os_wait_stats. Il tipo più comune di contesa di latch è la contesa di latch di buffer, riconoscibile dall'aumento dei tempi di attesa dei latch con wait_type di PAGELATCH_*. I latch non di buffer sono raggruppati nel tipo di attesa LATCH*. Come illustra il diagramma seguente, è consigliabile innanzitutto esaminare le attese del sistema usando la DMW sys.dm_os_wait_stats per determinare la percentuale del tempo di attesa complessivo causato dai latch di buffer o non di buffer. Se si notano latch non di buffer, è necessario esaminare anche la DMV sys.dm_os_latch_stats.
Il diagramma seguente illustra la relazione tra le informazioni restituite dalle DMV sys.dm_os_wait_stats e sys.dm_os_latch_stats.

Per altre informazioni sulla DMV sys.dm_os_wait_stats, vedere sys.dm_os_wait_stats (Transact-SQL) nella guida di SQL Server.
Per altre informazioni sulla DMV sys.dm_os_latch_stats, vedere sys.dm_os_latch_stats (Transact-SQL) nella guida di SQL Server.
Le misure seguenti del tempo di attesa latch indicano che l'eccessiva contesa di latch sta compromettendo le prestazioni dell'applicazione:
I tempi medi di attesa latch di pagina aumentano costantemente con la produttività: se i tempi medi di attesa latch di pagina aumentano costantemente con la produttività e se i tempi medi di attesa latch di buffer superano i tempi di risposta del disco previsti, è consigliabile esaminare le attività in attesa correnti usando la DMV
sys.dm_os_waiting_tasks. Le medie possono essere fuorvianti se analizzate separatamente, quindi è importante esaminare il sistema in tempo reale quando possibile, per comprendere le caratteristiche del carico di lavoro. In particolare, controllare se sono presenti lunghe attese per richieste PAGELATCH_EX e/o PAGELATCH_SH in qualsiasi pagina. Seguire questa procedura per diagnosticare l'aumento dei tempi medi di attesa latch di pagina con la velocità effettiva:- Usare gli script di esempio di Eseguire una query di sys.dm_os_waiting_tasks con i risultati ordinati per ID sessione o di Calcolare le attese in un periodo di tempo per esaminare le attività in attesa correnti e misurare il tempo medio di attesa latch.
- Usare lo script di esempio di Eseguire una query dei descrittori di buffer per determinare quali oggetti causano la contesa di latch per determinare l'indice e la tabella sottostante in cui si verifica la contesa.
- Misurare il tempo medio di attesa latch di pagina con il contatore di Monitor prestazioni MSSQL%NomeIstanza%\Statistiche\Attese latch\Tempo di attesa medio oppure eseguendo la DMV
sys.dm_os_wait_stats.
Nota
Per calcolare il tempo di attesa medio per un particolare tempo di attesa (restituito da
sys.dm_os_wait_statscome wt_:type), dividere il tempo di attesa totale (restituito comewait_time_ms) per il numero di attività in attesa (restituito comewaiting_tasks_count).Percentuale del tempo di attesa totale impiegato per i tipi di attesa latch durante il picco di carico: se il tempo medio di attesa latch come percentuale del tempo di attesa complessivo aumenta in linea con il carico dell'applicazione, la contesa di latch potrebbe compromettere le prestazioni e deve essere analizzata.
Misurare le attese latch di pagina e le attese latch non di pagina con i contatori delle prestazioni di Oggetto Statistiche attesa di SQL Server, quindi confrontare i valori di questi contatori delle prestazioni con quelli dei contatori delle prestazioni associati a CPU, I/O, memoria e velocità effettiva della rete. Transazioni/sec e richieste batch/sec, ad esempio, sono due misure valide di utilizzo delle risorse.
Nota
Il tempo di attesa relativo per ogni tipo di attesa non è incluso nella DMV
sys.dm_os_wait_statsperché questa DMW misura i tempi di attesa dall'ultimo avvio dell'istanza di SQL Server o dall'ultima reimpostazione delle statistiche di attesa cumulative tramite DBCC SQLPERF. Per calcolare il tempo di attesa relativo per ogni tipo di attesa, creare uno snapshot disys.dm_os_wait_statsprima del picco di carico e dopo il picco di carico e quindi calcolare la differenza. A questo scopo, può essere usato lo script di esempio di Calcolare le attese in un periodo di tempo.Solo per un ambiente non di produzione, pulire la DMV
sys.dm_os_wait_statscon il seguente comando:dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')È possibile eseguire un comando simile per cancellare la DMV
sys.dm_os_latch_stats:dbcc SQLPERF ('sys.dm_os_latch_stats', 'CLEAR')La produttività non aumenta e, in alcuni casi, diminuisce, man mano che aumentano il carico dell'applicazione e il numero di CPU disponibili per SQL Server: questa situazione è stata illustrata in Esempio di contesa di latch.
L'utilizzo della CPU non aumenta man mano che aumenta il carico di lavoro dell'applicazione: se l'utilizzo della CPU nel sistema non aumenta man mano che aumenta la concorrenza causata dalla velocità effettiva dell'applicazione, significa che SQL Server è in attesa di un evento e deve essere considerato un sintomo della contesa di latch.
Analizzare la causa radice. Anche se ognuna delle condizioni precedenti è vera, è tuttavia possibile che la causa radice dei problemi di prestazioni sia un'altra. In realtà, nella maggior parte dei casi, l'utilizzo non ottimale della CPU è causato da altri tipi di attese, ad esempio il blocco sui blocchi, le attese correlate all'I/O o i problemi della rete. Come regola generale, è sempre preferibile risolvere l'attesa della risorsa che rappresenta la percentuale maggiore del tempo di attesa complessivo prima di procedere a un'analisi più approfondita.
Analisi dei latch di buffer di attesa correnti
La contesa di latch di buffer si manifesta come aumento dei tempi di attesa dei latch con wait_type diPAGELATCH_* o PAGEIOLATCH_*, come visualizzato nella DMW sys.dm_os_wait_stats. Per esaminare il sistema in tempo reale, eseguire la seguente query in un sistema per unire le DMV sys.dm_os_wait_stats, sys.dm_exec_sessions e sys.dm_exec_requests. I risultati possono essere usati per determinare il tipo di attesa corrente per le sessioni in esecuzione nel server.
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc
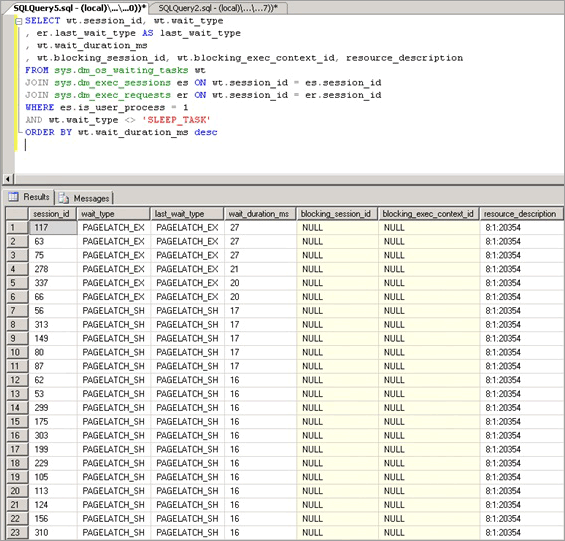
Le statistiche esposte da questa query sono descritte di seguito:
| Statistica | Descrizione |
|---|---|
| Session_id | ID della sessione associata all'attività. |
| Wait_type | Tipo di attesa registrato da SQL Server nel motore, che impedisce l'esecuzione di una richiesta corrente. |
| Last_wait_type | Se la richiesta è stata precedentemente bloccata, questa colonna restituisce il tipo dell'ultima attesa. Non ammette i valori Null. |
| Wait_duration_ms | Tempo di attesa totale, espresso in millisecondi, trascorso nell'attesa di questo tipo di attesa dall'avvio dell'istanza di SQL Server o dalla reimpostazione delle statistiche cumulative relative all'attesa. |
| Blocking_session_id | ID della sessione che sta bloccando la richiesta. |
| Blocking_exec_context_id | ID del contesto di esecuzione associato all'attività. |
| Resource_description | La colonna resource_description elenca la pagina esatta di cui si è in attesa nel formato <database_id>:<file_id>:<page_id> |
La query seguente restituirà informazioni per tutti i latch non di buffer:
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc;
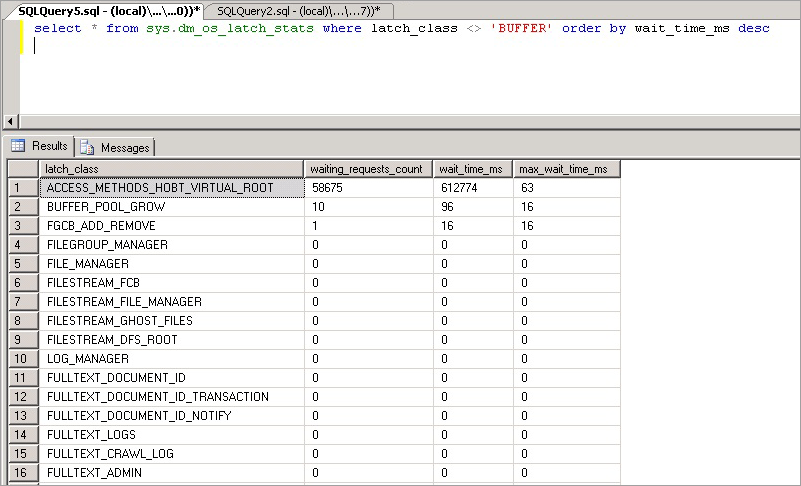
Le statistiche esposte da questa query sono descritte di seguito:
| Statistica | Descrizione |
|---|---|
| latch_class | Tipo di latch registrato da SQL Server nel motore, che impedisce l'esecuzione di una richiesta corrente. |
| waiting_requests_count | Numero di attese di latch in questa classe dal riavvio di SQL Server. Questo contatore viene incrementato all'inizio di un'attesa di latch. |
| wait_time_ms | Tempo di attesa totale, espresso in millisecondi, trascorso nell'attesa di questo tipo di latch. |
| max_wait_time_ms | Tempo massimo, espresso in millisecondi, trascorso da una richiesta nell'attesa di questo tipo di latch. |
Nota
I valori restituiti da questa DMV sono cumulativi a partire dall'ultimo riavvio del motore di database o dall'ultima reimpostazione della DMV. Usare la colonna sqlserver_start_time in sys.dm_os_sys_info per trovare l'ora di avvio dell'ultimo motore di database. Perciò, in un sistema in esecuzione da molto tempo alcune statistiche, ad es. max_wait_time_ms, saranno raramente utili. Il comando seguente può essere usato per reimpostare le statistiche relative all'attesa per questa DMV:
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
Scenari di contesa di latch di SQL Server
È stato osservato che gli scenari seguenti causano una contesa di latch eccessiva.
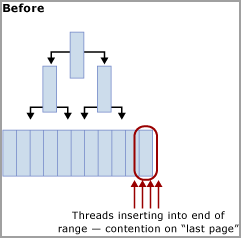
Contesa di inserimento dell'ultima pagina o della pagina finale
Una comune procedura OLTP consiste nel creare un indice cluster per una colonna Identity o Date. Ciò consente di mantenere una corretta organizzazione fisica dell'indice, che può migliorare considerevolmente le prestazioni delle operazioni sia di lettura che di scrittura nell'indice. Questa progettazione dello schema, tuttavia, può inavvertitamente causare una contesa di latch. Questo problema si verifica molto spesso nelle tabelle di grandi dimensioni con righe di piccole dimensioni e negli inserimenti in un indice contenente una colonna chiave iniziale con valori che aumentano in modo sequenziale, ad esempio numeri interi crescenti o chiavi datetime. In questo scenario, l'applicazione esegue raramente, o addirittura mai, aggiornamenti o eliminazioni, con l'eccezione delle operazioni di archiviazione.
Nell'esempio seguente, il thread 1 e il thread 2 vogliono entrambi eseguire un inserimento di un record che verrà archiviato a pagina 299. Dal punto di vista del blocco logico, non sussistono problemi perché verranno usati blocchi a livello di riga e possono essere mantenuti contemporaneamente blocchi esclusivi su entrambi i record nella stessa pagina. Tuttavia, per garantire l'integrità della memoria fisica un solo thread alla volta può acquisire un latch esclusivo, quindi l'accesso alla pagina viene serializzato per impedire la perdita di aggiornamenti in memoria. In questo caso, il thread 1 acquisisce il latch esclusivo e il thread 2 resta in attesa, facendo registrare un'attesa PAGELATCH_EX per questa risorsa nelle statistiche relative all'attesa. Viene visualizzato tramite il valore wait_type nella DMV sys.dm_os_waiting_tasks.
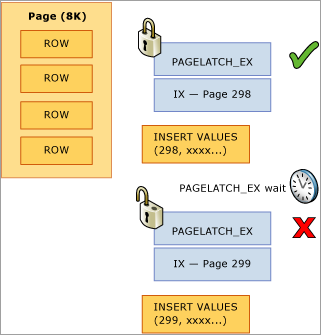
Questa contesa viene comunemente definita contesa di "inserimento dell'ultima pagina" perché si verifica all'estremità destra dell'albero B, come illustrato nel diagramma seguente:
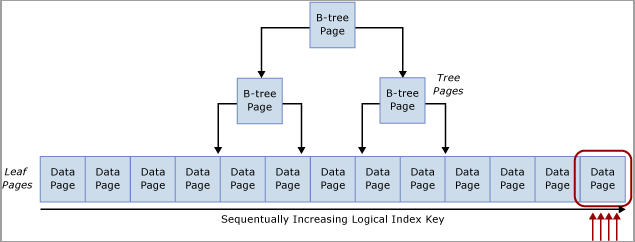
Questo tipo di contesa di latch può essere spiegato come segue. Quando una nuova riga viene inserita in un indice, SQL Server usa l'algoritmo seguente per eseguire la modifica:
Attraversamento dell'albero B per individuare la pagina corretta in cui conservare il nuovo record.
Latch della pagina con PAGELATCH_EX, che impedisce ad altri utenti di modificarla, e acquisizione dei latch condivisi (PAGELATCH_SH) in tutte le pagine non foglia.
Nota
In alcuni casi il motore di SQL richiede l'acquisizione dei latch EX anche nelle pagine non foglia dell'albero B. Quando ad esempio si verifica una divisione di pagina, sarà necessario impostare un latch esclusivo (PAGELATCH_EX) per le pagine direttamente interessate.
Registrazione di una voce di log indicante che la riga è stata modificata.
Aggiunta della riga alla pagina e impostazione della pagina come dirty.
Annullamento del latch per tutte le pagine.
Se l'indice della tabella si basa su una chiave che aumenta in modo sequenziale, ogni nuovo inserimento andrà nella stessa pagina alla fine dell'albero B, fino a riempire l'intera pagina. Di conseguenza negli scenari a concorrenza elevata può verificarsi una contesa all'estremità destra dell'albero B sia negli indici cluster che in quelli non cluster. Le tabelle interessate da questo tipo di contesa accettano principalmente operazioni INSERT e le pagine degli indici che presentano problemi sono in genere relativamente dense, ad esempio dimensioni di riga di ~165 byte (incluso l'overhead della riga) sono pari a ~49 righe per pagina. In questo esempio con un'attività di inserimento intensa, si prevede che si verifichino attese PAGELATCH_EX/PAGELATCH_SH, come di fatto avviene normalmente. Per esaminare attese latch di pagina e le attese latch di pagina ad albero, usare la DMV sys.dm_db_index_operational_stats.
La tabella seguente riepiloga i principali fattori osservati con questo tipo di contesa di latch:
| Fattore | Osservazioni tipiche |
|---|---|
| CPU logiche usate da SQL Server | Questo tipo di contesa di latch si verifica principalmente nei sistemi con più di 16 core CPU e ancora più comunemente nei sistemi con più di 32 core CPU. |
| Progettazione di schemi e modelli di accesso | Usa un valore di identità che aumenta in modo sequenziale come colonna iniziale di un indice in una tabella per dati transazionali. L'indice ha una chiave primaria crescente con una frequenza elevata di inserimenti. L'indice ha almeno un valore di colonna che aumenta in modo sequenziale. Le righe sono in genere di piccole dimensioni e sono presenti molte righe per pagina. |
| Tipo di attesa osservato | Più thread che contendono per la stessa risorsa con attese latch esclusivo (EX) o condiviso (SH) associate allo stesso elemento resource_description nella DMV sys.dm_os_waiting_tasks restituita dalla query su sys.dm_os_waiting_tasks con i risultati ordinati in base alla durata dell'attesa. |
| Fattori relativi alla progettazione da considerare | Valutare la possibilità di modificare l'ordine delle colonne dell'indice come previsto dalla strategia di mitigazione degli indici non sequenziali, se è possibile garantire che gli inserimenti verranno sempre distribuiti in modo uniforme nell'albero B. Se si adotta la strategia di mitigazione della partizione hash, non sarà più possibile usare il partizionamento per altri scopi, ad esempio per l'archiviazione di finestre temporali scorrevoli. L'uso della strategia di mitigazione della partizione hash può causare problemi di eliminazione della partizione per le query SELECT usate dall'applicazione. |
Contesa di latch in tabelle di piccole dimensioni con un indice non cluster e inserimenti casuali (tabella della coda)
Questo scenario si osserva in genere quando una tabella SQL viene usata come coda temporanea (ad esempio, in un sistema di messaggistica asincrono).
In questo scenario la contesa di latch esclusivo (EX) e condiviso (SH) può verificarsi nelle condizioni seguenti:
- Le operazioni di inserimento, selezione, aggiornamento o eliminazione si verificano in condizioni di concorrenza elevata.
- Le dimensioni delle righe sono relativamente piccole e comportano quindi pagine dense.
- Il numero di righe nella tabella è relativamente basso e comporta quindi un albero B superficiale, definito da un indice con una profondità di due o tre livelli.
Nota
Con questo tipo di modello di accesso anche per gli alberi B con una profondità maggiore di questa possono verificarsi contese, se la frequenza del linguaggio DML (Data Manipulation Language) e la concorrenza del sistema sono sufficientemente elevate. Il livello di contesa di latch può diventare considerevole quando la concorrenza aumenta se sono disponibili per il sistema almeno 16 core CPU.
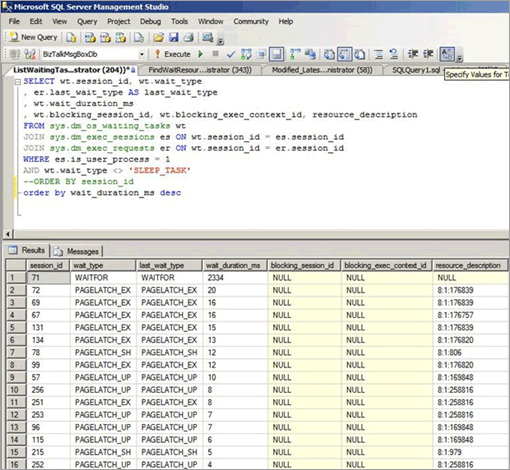
La contesa di latch può verificarsi anche se l'accesso è casuale nell'albero B, ad esempio quando una colonna non sequenziale è la chiave iniziale in un indice cluster. Lo screenshot seguente è relativo a un sistema in cui si verifica questo tipo di contesa di latch. In questo esempio, la contesa è dovuta alla densità delle pagine causata dalle piccole dimensioni delle righe e da un albero B relativamente superficiale. Con l'aumentare della concorrenza, la contesa di latch nelle pagine si verifica anche se gli inserimenti sono casuali nell'albero B, perché la colonna iniziale nell'indice era un GUID.
Nello screenshot seguente, le attese si verificano sia nelle pagine di dati del buffer che nelle pagine PFS (Page Free Space). Per altre informazioni sulla contesa di latch nelle pagine PFS, vedere il seguente post di blog di terze parti nel sito SQLSkills: Benchmarking: più file di dati nelle unità SSD. Anche quando è stato aumentato il numero di file di dati, la contesa di latch era prevalente per le pagine di dati del buffer.
La tabella seguente riepiloga i principali fattori osservati con questo tipo di contesa di latch:
| Fattore | Osservazioni tipiche |
|---|---|
| CPU logiche usate da SQL Server | La contesa di latch si verifica principalmente nei computer con più di 16 core CPU. |
| Progettazione di schemi e modelli di accesso | Frequenza elevata di modelli di accesso di inserimento/selezione/aggiornamento/eliminazione in tabelle di piccole dimensioni. Albero B superficiale (indice con una profondità di due o tre livelli). Righe di piccole dimensioni (molti record per pagina). |
| Livello di concorrenza | La contesa di latch si verificherà solo con livelli elevati di richieste simultanee dal livello applicazione. |
| Tipo di attesa osservato | Si osservano attese nel latch di buffer (PAGELATCH_EX e PAGELATCH_SH) e non di buffer ACCESS_METHODS_HOBT_VIRTUAL_ROOT a causa delle divisioni della radice. Si osservano anche attese PAGELATCH_UP nelle pagine PFS. Per altre informazioni sulle attesa latch non di buffer, vedere sys.dm_os_latch_stats (Transact-SQL) nella guida di SQL Server. |
La combinazione di un albero B superficiale e di inserimenti casuali nell'indice può causare divisioni di pagina nell'albero B. Per eseguire una divisione della pagina, SQL Server deve acquisire i latch condivisi (SH) a tutti i livelli e quindi acquisire i latch esclusivi (EX) nelle pagine dell'albero B interessate dalle divisioni di pagina. Anche quando la concorrenza è elevata e i dati vengono continuamente inseriti ed eliminati, possono verificarsi divisioni della radice dell'albero B. In questo caso, le altre operazioni di inserimento potrebbero dover attendere che i latch non di buffer vengano acquisiti nell'albero B. Questa condizione sarà riconoscibile dal numero elevato di attese nel tipo di latch ACCESS_METHODS_HOBT_VIRTUAL_ROOT osservato nella DMV sys.dm_os_latch_stats.
Lo script seguente può essere modificato per determinare la profondità dell'albero B per gli indici della tabella interessata.
select o.name as [table],
i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows],
i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name;
Contesa di latch nelle pagine PFS (Page Free Space)
PFS è l'acronimo di Page Free Space. SQL Server alloca una pagina PFS ogni 8088 pagine (a partire da PageID = 1) in ogni file di database. Ogni byte della pagina PFS registra informazioni che indicano quanto spazio è disponibile nella pagina, se tale spazio è allocato o meno e se la pagina archivia i record fantasma. La pagina PFS contiene informazioni sulle pagine disponibili per l'allocazione quando una nuova pagina viene richiesta da un'operazione di inserimento o di aggiornamento. La pagina PFS deve essere aggiornata in diversi scenari, ad esempio quando si verificano allocazioni o deallocazioni. Poiché è necessario usare un latch di aggiornamento (UP) per proteggere la pagina PFS, nelle pagine PFS può verificarsi una contesa di latch se sono presenti relativamente pochi file di dati in un filegroup e un numero elevato di core CPU. È possibile risolvere facilmente questo problema aumentando il numero di file per ogni filegroup.
Avviso
L'aumento del numero di file per ogni filegroup può tuttavia compromettere le prestazioni di determinati carichi, ad esempio quelli con molte operazioni di ordinamento di grandi dimensioni che causano lo spill della memoria su disco.
Se si osservano molte attese PAGELATCH_UP per le pagine PFS o SGAM in tempdb, completare questi passaggi per eliminare il collo di bottiglia:
Aggiungere file di dati a tempdb in modo che il numero di file di dati di tempdb corrisponda al numero di core del processore nel server.
Abilitare il flag di traccia di SQL Server 1118.
Per altre informazioni sui colli di bottiglia nell'allocazione causati dalla contesa nelle pagine di sistema, vedere il post di blog What is allocation bottleneck? (Che cos'è il collo di bottiglia nell'allocazione?).
Funzioni con valori di tabella e contesa di latch in tempdb
Oltre alla contesa di allocazione, esistono altri fattori che possono causare contese di latch in tempdb, ad esempio un uso intensivo delle funzioni con valori di tabella nelle query.
Gestione della contesa di latch per modelli di tabella diversi
Le sezioni seguenti descrivono le tecniche che possono essere usate per risolvere o ovviare ai problemi di prestazioni correlati a una contesa di latch eccessiva.
Usare una chiave di indice iniziale non sequenziale
Un metodo per gestire una contesa di latch consiste nel sostituire una chiave di indice sequenziale con una chiave non sequenziale per distribuire uniformemente inserimenti in un intervallo di indici.
Questa operazione viene eseguita in genere tramite una colonna iniziale dell'indice che distribuirà il carico di lavoro in modo proporzionale. In questo caso sono disponibili due opzioni:
Opzione: usare una colonna nella tabella per distribuire i valori nell'intervallo di chiavi dell'indice
Valutare il carico di lavoro per ottenere un valore naturale che possa essere usato per distribuire gli inserimenti nell'intervallo di chiavi. Si consideri ad esempio lo scenario relativo a uno sportello automatico, in cui ATM_ID può essere un candidato valido per distribuire gli inserimenti in una tabella delle transazioni relativa ai prelievi dal momento che un cliente può usare un solo sportello automatico alla volta. Analogamente, in un sistema di punti vendita, Checkout_ID o Store ID sarebbe probabilmente un valore naturale utilizzabile per distribuire gli inserimenti in un intervallo di chiavi. Questa tecnica richiede la creazione di una chiave di indice composto con la colonna chiave iniziale corrispondente al valore della colonna identificata o a un hash di tale valore combinato con una o più colonne aggiuntive per garantire l'univocità. Nella maggior parte dei casi, un hash del valore sarà l'ideale perché con troppi valori distinti l'organizzazione fisica sarà inadeguata. In un sistema di punti vendita, ad esempio, dal valore Store ID è possibile creare un hash, che è un modulo, che si allinea al numero di core CPU. Questa tecnica avrebbe come risultato un numero relativamente basso di intervalli all'interno della tabella. Tuttavia sarebbe sufficiente distribuire gli inserimenti in modo da evitare la contesa di latch. Questa tecnica è illustrata nell'immagine seguente.
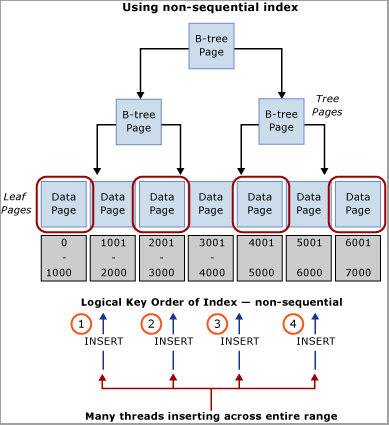
Importante
Questo modello è contrario alle tradizionali procedure consigliate di indicizzazione. Anche se questa tecnica consente di garantire una distribuzione uniforme degli inserimenti nell'albero B, può tuttavia richiedere una modifica dello schema a livello di applicazione. Questo modello può anche compromettere le prestazioni delle query che richiedono analisi dell'intervallo che utilizzano l'indice cluster. Sarà necessario analizzare i modelli di carico di lavoro per determinare se questo approccio di progettazione funzionerà correttamente. Questo modello deve essere implementato se è possibile ridurre le prestazioni di analisi sequenziale a favore di velocità effettiva e scalabilità degli inserimenti.
Questo modello è stato implementato durante un engagement di lab per la misurazione delle prestazioni e ha risolto una contesa di latch in un sistema con 32 core CPU fisici. La tabella è stata usata per archiviare il saldo finale al termine di una transazione. Ogni transazione commerciale ha eseguito un singolo inserimento nella tabella.
Definizione di una tabella originale
Durante l'uso della definizione di una tabella originale, si è osservata una contesa di latch eccessiva nell'indice cluster pk_table1:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID);
go
Nota
I nomi degli oggetti nella definizione della tabella sono stati modificati rispetto ai valori originali.
Definizione dell'indice riordinato
Il riordinamento dell'indice con UserID come colonna iniziale nella chiave primaria ha determinato una distribuzione pressoché casuale degli inserimenti nelle pagine. La distribuzione risultante non era casuale al 100% perché non tutti gli utenti sono online contemporaneamente, ma la distribuzione è stata sufficientemente casuale per ridurre una contesa di latch eccessiva. Si ricordi che, quando si riordina la definizione dell'indice, è necessario modificare qualsiasi query SELECT eseguita su questa tabella per usare sia UserID che TransactionID come predicati di uguaglianza.
Importante
Assicurarsi di testare accuratamente tutte le modifiche apportate in un ambiente di test prima dell'esecuzione in un ambiente di produzione.
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID);
go
Uso di un valore hash come colonna iniziale nella chiave primaria
La definizione di tabella seguente può essere usata per generare un modulo che si allinea al numero di CPU. HashValue viene generato usando il valore TransactionID, che aumenta in modo sequenziale, per garantire una distribuzione uniforme nell'albero B:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID);
go
Opzione: usare un GUID come colonna chiave iniziale dell'indice
Se non sono presenti separatori naturali, è possibile usare una colonna GUID come colonna chiave iniziale dell'indice per garantire una distribuzione uniforme degli inserimenti. Anche se l'uso del GUID come colonna iniziale nell'approccio basato sulla chiave di indice consente di usare il partizionamento per altre funzionalità, questa tecnica presenta anche alcuni svantaggi, tra cui un numero maggiore di divisioni di pagina, un'organizzazione fisica inadeguata e basse densità di pagina.
Nota
L'uso dei GUID come colonne chiave iniziali degli indici è un argomento molto dibattuto. Una discussione approfondita sui vantaggi e gli svantaggi di questo metodo esula dall'ambito di questo articolo.
Usare il partizionamento hash con una colonna calcolata
Il partizionamento delle tabelle in SQL Server può essere usato per attenuare una contesa di latch eccessiva. La creazione di uno schema di partizionamento hash con una colonna calcolata in una tabella partizionata è un approccio comune realizzabile con questi passaggi:
Creare un nuovo filegroup o usare un filegroup esistente in cui conservare le partizioni.
Se si usa un nuovo filegroup, bilanciare equamente i singoli file in base al numero di unità logica, facendo attenzione a usare un layout ottimale. Se il modello di accesso prevede una frequenza elevata di inserimenti, assicurarsi di creare un numero di file pari a quello dei core CPU fisici nel computer SQL Server.
Usare il comando CREATE PARTITION FUNCTION per partizionare le tabelle in X partizioni, dove X è il numero di core CPU fisici nel computer SQL Server (almeno 32 partizioni).
Nota
Non è sempre necessario un allineamento 1:1 tra il numero di partizioni e il numero di core CPU. In molti casi può trattarsi di un valore inferiore al numero di core CPU. Avere più partizioni può comportare un sovraccarico maggiore per le query che devono eseguire la ricerca in tutte le partizioni e in questi casi sarà preferibile un minor numero di partizioni. Nel test di SQLCAT sui sistemi con 64 e 128 CPU logiche con carichi di lavoro dei clienti reali, sono state sufficienti 32 partizioni per risolvere una contesa di latch eccessiva e raggiungere gli obiettivi di scalabilità. In ultima analisi, il numero ideale di partizioni deve essere determinato tramite test.
Usare il comando CREATE_PARTITION_SCHEME:
- Associare la funzione di partizione ai filegroup.
- Aggiungere alla tabella una colonna hash di tipo tinyint o smallint.
- Calcolare una distribuzione hash valida. Usare, ad esempio, hashbytes con modulo o binary_checksum.
Lo script di esempio seguente può essere personalizzato per le finalità dell'implementazione:
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Questo script può essere usato per il partizionamento hash di una tabella in cui si verificano problemi causati da una contesa di inserimento dell'ultima pagina o della pagina finale. Questa tecnica sposta la contesa dall'ultima pagina partizionando la tabella e distribuendo gli inserimenti tra le partizioni della tabella con un'operazione di modulo del valore hash.
Effetti del partizionamento hash con una colonna calcolata
Come illustra il diagramma seguente, questa tecnica sposta la contesa dall'ultima pagina ricompilando l'indice nella funzione hash e creando un numero di partizioni pari a quello dei core CPU fisici nel computer SQL Server. Gli inserimenti continuano a essere posizionati alla fine dell'intervallo logico (un valore che aumenta in modo sequenziale), ma l'operazione di modulo del valore hash garantisce che gli inserimenti vengano divisi tra i diversi alberi B, riducendo così il collo di bottiglia, come è illustrato nei diagrammi seguenti:
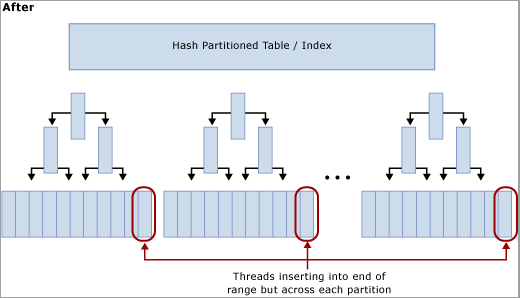
Compromessi per l'uso del partizionamento hash
Anche se il partizionamento hash può eliminare la contesa negli inserimenti, è necessario prendere in considerazione diversi compromessi quando si decide se usare o meno questa tecnica:
Nella maggior parte dei casi, le query SELECT devono essere modificate in modo da includere la partizione hash nel predicato e generano un piano di query che non causa alcuna eliminazione di partizioni quando queste query vengono eseguite. Lo screenshot seguente mostra un piano non valido senza eliminazioni di partizioni dopo l'implementazione del partizionamento hash.
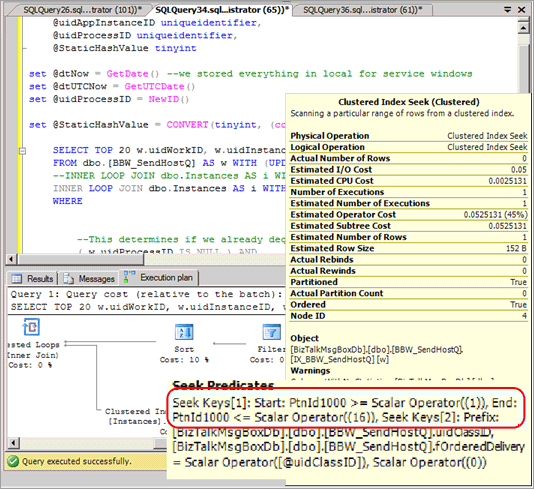
Esclude la possibilità di eliminazione di partizioni in alcune altre query, ad esempio i report basati su intervalli.
Quando si crea un join tra una tabella con partizionamento hash e un'altra tabella, per ottenere l'eliminazione della partizione, sarà necessario eseguire il partizionamento hash della seconda tabella nella stessa chiave e la chiave hash deve far parte dei criteri di join.
Il partizionamento hash impedisce di usare il partizionamento per altre funzionalità di gestione, ad esempio l'archiviazione di finestre temporali scorrevoli e le funzionalità di cambio di partizione.
Il partizionamento hash è una strategia efficace per ridurre una contesa di latch eccessiva perché aumenta la velocità effettiva complessiva del sistema attenuando la contesa negli inserimenti. Poiché sono previsti alcuni compromessi, potrebbe non essere la soluzione ideale per alcuni modelli di accesso.
Riepilogo delle tecniche usate per gestire la contesa di latch
Le due sezioni seguenti forniscono un riepilogo delle tecniche che possono essere usate per gestire una contesa di latch eccessiva:
Chiave/Indice non sequenziale
Vantaggi:
- Consente di usare altre funzionalità di partizionamento, ad esempio l'archiviazione di dati tramite uno schema di finestre temporali scorrevoli e le funzionalità di cambio di partizione.
Svantaggi:
- Possibili sfide nella scelta di una chiave o di un indice per garantire sempre una distribuzione "il più possibile" uniforme degli inserimenti.
- È possibile usare un GUID come colonna iniziale per garantire una distribuzione uniforme, tenendo tuttavia presente che ciò può comportare un numero eccessivo di operazioni di divisione di pagina.
- Gli inserimenti casuali nell'albero B possono comportare un numero eccessivo di operazioni di divisione di pagina e causare una contesa di latch nelle pagine non foglia.
Partizionamento hash con colonna calcolata
Vantaggi:
- È trasparente per gli inserimenti.
Svantaggi:
- Il partizionamento non può essere usato per le funzionalità di gestione previste, ad esempio l'archiviazione di dati tramite opzioni di cambio di partizione.
- Può causare problemi di eliminazione di partizioni per le query, tra cui selezioni/aggiornamenti singoli e basati su un intervallo e query che eseguono un join.
- L'aggiunta di una colonna calcolata persistente è un'operazione offline.
Suggerimento
Per altre tecniche, vedere il post di blog Attese PAGELATCH_EX e attività di inserimento intensa.
Procedura dettagliata: diagnosticare una contesa di latch
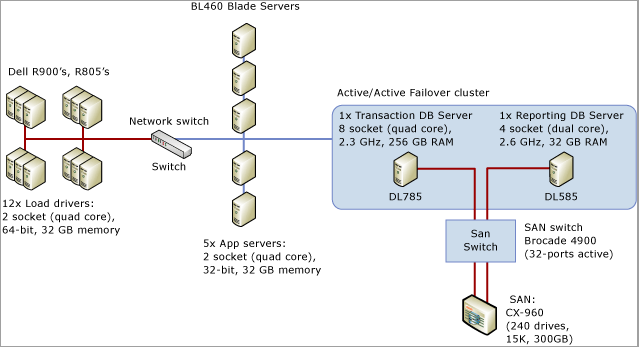
La procedura dettagliata seguente illustra gli strumenti e le tecniche descritti in Diagnosi della contesa di latch di SQL Server e Gestione della contesa di latch per modelli di tabella diversi per risolvere un problema in uno scenario reale. Questo scenario descrive un engagement dei clienti per eseguire il test di carico di un sistema di punti vendita che simula circa 8.000 negozi che eseguono transazioni in un'applicazione SQL Server in esecuzione in un sistema a 8 socket e 32 core fisici con 256 GB di memoria.
Il diagramma seguente illustra in dettaglio l'hardware usato per testare il sistema di punti vendita:
Sintomo: latch ad accesso frequente
In questo caso sono state osservate lunghe attese per PAGELATCH_EX, dove in genere si definisce lunga un'attesa con una durata media di più di 1 ms. In questo caso sono state costantemente osservate attese superiori ai 20 ms.
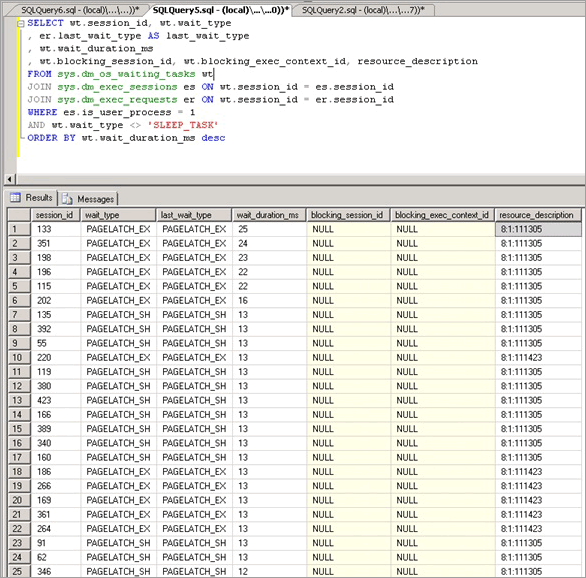
Dopo aver determinato che la contesa di latch costituiva un problema, si è passati a determinare la causa della contesa di latch.
Isolamento dell'oggetto che causa la contesa di latch
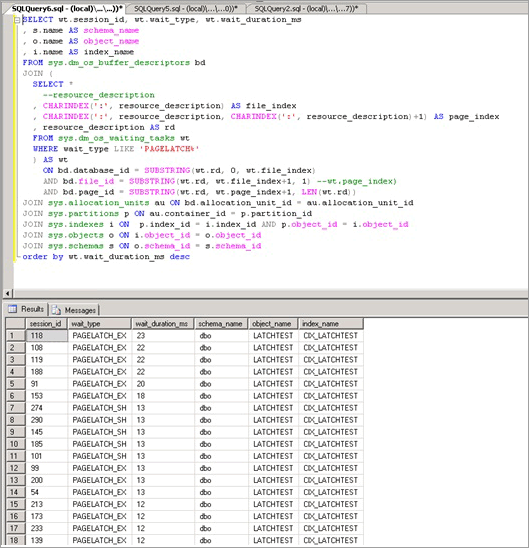
Lo script seguente usa la colonna resource_description per isolare l'indice che ha causato la contesa PAGELATCH_EX:
Nota
La colonna resource_description restituita da questo script fornisce la descrizione della risorsa nel formato <DatabaseID,FileID,PageID> dove il nome del database associato a DatabaseID può essere determinato passando il valore di DatabaseID alla funzione DB_NAME ().
SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
--resource_description
, CHARINDEX(':', resource_description) AS file_index
, CHARINDEX(':', resource_description, CHARINDEX(':', resource_description)+1) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE 'PAGELATCH%'
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index+1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index+1, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
order by wt.wait_duration_ms desc;
Come illustrato di seguito, la contesa si verifica nella tabella LATCHTEST e nel nome dell'indice CIX_LATCHTEST. Tenere presente che i nomi sono stati modificati per rendere anonimo il carico di lavoro.
Per uno script più avanzato che esegue ripetutamente il polling e usa una tabella temporanea per determinare il tempo di attesa totale in un periodo configurabile, vedere Eseguire una query dei descrittori di buffer per determinare quali oggetti causano la contesa di latch nell'appendice.
Tecnica alternativa per isolare l'oggetto che causa la contesa di latch
A volte può essere poco pratico eseguire query sys.dm_os_buffer_descriptors. Poiché la memoria nel sistema e quella disponibile per il pool di buffer aumentano, aumenta anche il tempo necessario per eseguire questa vista DMV. In un sistema da 256 GB l'esecuzione di questa DMV può richiedere fino a 10 o più minuti. È disponibile una tecnica alternativa, che viene descritta in dettaglio di seguito, con un carico di lavoro diverso eseguito nel lab:
Eseguire query sulle attività in attesa correnti, usando lo script della sezione Eseguire una query su sys.dm_os_waiting_tasks con i risultati ordinati in base alla durata dell'attesa nell'appendice.
Identificare la pagina chiave in cui si osserva una serie di istruzioni, come si verifica quando più thread si contendono la stessa pagina. In questo esempio, i thread che eseguono l'inserimento si contendono la pagina finale nell'albero B e rimarranno in attesa finché non potranno acquisire un latch EX. Questo è indicato dall'elemento resource_description nella prima query, in questo caso 8:1:111305.
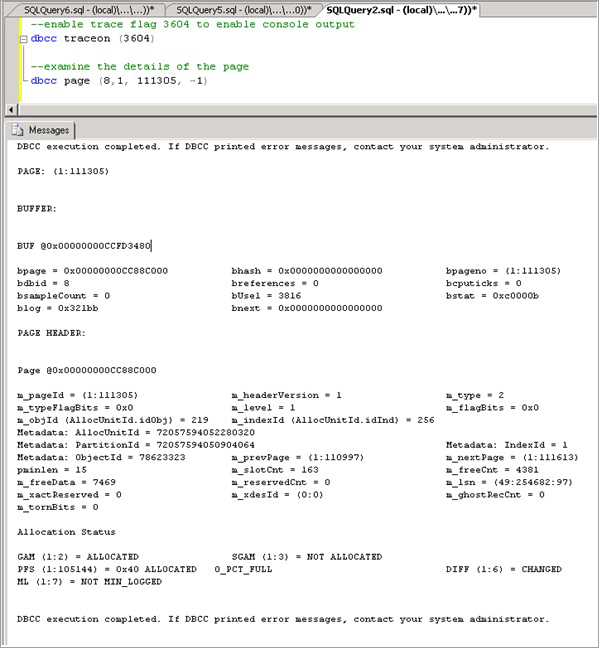
Abilitare il flag di traccia 3604, che espone altre informazioni sulla pagina tramite DBCC PAGE con la sintassi seguente, e sostituire il valore tra parentesi con il valore ottenuto tramite resource_description:
--enable trace flag 3604 to enable console output dbcc traceon (3604); --examine the details of the page dbcc page (8,1, 111305, -1);Esaminare l'output di DBCC. Dovrebbero essere presenti i metadati associati ObjectID, in questo caso "78623323".
È ora possibile eseguire il comando seguente per determinare il nome dell'oggetto che causa la contesa, che, come previsto, è LATCHTEST.
Nota
Assicurarsi di essere nel contesto di database corretto. In caso contrario, la query restituirà NULL.
--get object name select OBJECT_NAME (78623323);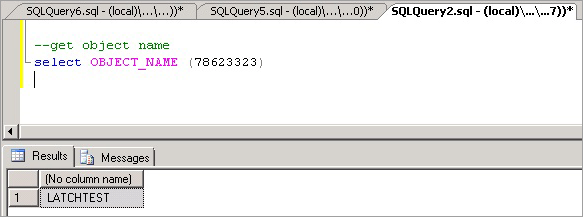
Riepilogo e risultati
Usando la tecnica precedente è stato possibile verificare che la contesa si è verificata in un indice cluster con un valore chiave che aumenta in modo sequenziale nella tabella che ha di gran lunga ricevuto il maggior numero di inserimenti. Questo tipo di contesa non è insolito per gli indici con un valore chiave che aumenta in modo sequenziale, ad esempio datetime, identity o transactionID generato dall'applicazione.
Per risolvere questo problema, è stato usato il partizionamento hash con una colonna calcolata ed è stato osservato un miglioramento delle prestazioni del 690%. La tabella seguente riepiloga le prestazioni dell'applicazione prima e dopo l'implementazione del partizionamento hash con una colonna calcolata. L'utilizzo della CPU aumenta considerevolmente e parallelamente alla velocità effettiva, come previsto dopo la rimozione del collo di bottiglia dovuto alla contesa di latch:
| Misura | Prima del partizionamento hash | Dopo il partizionamento hash |
|---|---|---|
| Transazioni commerciali/sec | 36 | 249 |
| Tempo medio di attesa latch di pagina | 36 millisecondi | 0,6 millisecondi |
| Attese latch/sec | 9.562 | 2.873 |
| Tempo processore SQL | 24% | 78% |
| Richieste batch SQL/sec | 12.368 | 47.045 |
Come si può notare dalla tabella precedente, identificare correttamente e risolvere i problemi di prestazioni causati da una contesa di latch di pagina eccessiva può avere un impatto positivo sulle prestazioni complessive dell'applicazione.
Appendice: tecnica alternativa
Una possibile strategia per evitare una contesa di latch di pagina eccessiva consiste nel riempire le righe con una colonna CHAR per assicurarsi che ogni riga usi una pagina intera. Questa strategia può essere applicata quando le dimensioni complessive dei dati sono ridotte ed è necessario risolvere la contesa di latch di pagina EX causata dalla combinazione seguente di fattori:
- Righe di dimensioni ridotte
- Albero B superficiale
- Modello di accesso con una frequenza elevata di operazioni casuali di inserimento, selezione, aggiornamento ed eliminazione
- Tabelle di piccole dimensioni, ad esempio tabelle di coda temporanea
Se si riempiono le righe per occupare una pagina intera, è necessario SQL per allocare pagine aggiuntive, rendendo disponibili più pagine per gli inserimenti e riducendo la contesa di latch di pagina EX.
Riempimento delle righe per assicurarsi che ogni riga occupi una pagina intera
Per riempire le righe in modo che occupino un'intera pagina, è possibile usare uno script simile al seguente:
ALTER TABLE mytable ADD Padding CHAR(5000) NOT NULL DEFAULT ('X');
Nota
Usare il carattere più piccolo possibile che forza una riga per pagina per ridurre i requisiti aggiuntivi della CPU per il valore di riempimento e lo spazio aggiuntivo necessario per registrare la riga. In un sistema a prestazioni elevate viene conteggiato ogni byte.
Questa tecnica viene illustrata per completezza. Nella pratica, SQLCAT l'ha usata solo su una piccola tabella con 10.000 righe in un unico engagement relativo alle prestazioni. Questa tecnica ha un'applicazione limitata in quanto accresce il numero di richieste di memoria in SQL Server per le tabelle di grandi dimensioni e può comportare una contesa di latch non di buffer nelle pagine non foglia. Le richieste aggiuntive di memoria possono costituire una forte limitazione all'applicazione di questa tecnica. Con la quantità di memoria disponibile in un server moderno, gran parte del working set per i carichi di lavoro OLTP viene in genere conservata in memoria. Quando il set di dati aumenta fino a raggiungere dimensioni superiori a quelle della memoria, si verificherà un calo significativo delle prestazioni. Questa tecnica è quindi applicabile solo alle tabelle di piccole dimensioni. Questa tecnica non viene usata da SQLCAT per scenari quali la contesa di inserimento dell'ultima pagina o della pagina finale per le tabelle di grandi dimensioni.
Importante
L'impiego di questa strategia può generare un numero elevato di attese nel tipo di latch ACCESS_METHODS_HOBT_VIRTUAL_ROOT perché questa strategia può determinare un numero elevato di divisioni di pagina nei livelli non foglia dell'albero B. In tal caso, SQL Server deve acquisire latch condivisi (SH) a tutti i livelli seguiti dai latch esclusivi (EX) nelle pagine dell'albero B in cui è possibile una divisione di pagina. Controllare la DMV sys.dm_os_latch_stats per verificare la presenza di un numero elevato di attese nel tipo di latch ACCESS_METHODS_HOBT_VIRTUAL_ROOT dopo il riempimento delle righe.
Appendice: script per la contesa di latch di SQL Server
Questa sezione contiene script che possono essere usati per diagnosticare e risolvere i problemi relativi alla contesa di latch.
Eseguire una query sys.dm_os_waiting_tasks con i risultati ordinati per ID sessione
Lo script di esempio seguente eseguirà una query sys.dm_os_waiting_tasks e restituirà le attese latch ordinate per ID sessione:
-- WAITING TASKS ordered by session_id
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
Eseguire una query sys.dm_os_waiting_tasks con i risultati ordinati in base alla durata dell'attesa
Lo script di esempio seguente eseguirà una query sys.dm_os_waiting_tasks e restituirà le attese latch ordinate in base alla durata dell'attesa:
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc;
Calcolare le attese in un periodo di tempo
Lo script seguente calcola e restituisce le attese latch in un periodo di tempo.
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
use tempdb
go
declare @current_snap_time datetime;
declare @previous_snap_time datetime;
set @current_snap_time = GETDATE();
if not exists(select name from tempdb.sys.sysobjects where name like '#_wait_stats%')
create table #_wait_stats
(
wait_type varchar(128)
,waiting_tasks_count bigint
,wait_time_ms bigint
,avg_wait_time_ms int
,max_wait_time_ms bigint
,signal_wait_time_ms bigint
,avg_signal_wait_time int
,snap_time datetime
);
insert into #_wait_stats (
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,snap_time
)
select
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,getdate()
from sys.dm_os_wait_stats;
--get the previous collection point
select top 1 @previous_snap_time = snap_time from #_wait_stats
where snap_time < (select max(snap_time) from #_wait_stats)
order by snap_time desc;
--get delta in the wait stats
select top 10
s.wait_type
, (e.waiting_tasks_count - s.waiting_tasks_count) as [waiting_tasks_count]
, (e.wait_time_ms - s.wait_time_ms) as [wait_time_ms]
, (e.wait_time_ms - s.wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_wait_time_ms]
, (e.max_wait_time_ms) as [max_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms) as [signal_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_signal_time_ms]
, s.snap_time as [start_time]
, e.snap_time as [end_time]
, DATEDIFF(ss, s.snap_time, e.snap_time) as [seconds_in_sample]
from #_wait_stats e
inner join (
select * from #_wait_stats
where snap_time = @previous_snap_time
) s on (s.wait_type = e.wait_type)
where
e.snap_time = @current_snap_time
and s.snap_time = @previous_snap_time
and e.wait_time_ms > 0
and (e.waiting_tasks_count - s.waiting_tasks_count) > 0
and e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH'
, 'SOS_SCHEDULER_YIELD','DBMIRRORING_CMD', 'BROKER_TASK_STOP'
, 'CLR_AUTO_EVENT', 'BROKER_RECEIVE_WAITFOR', 'WAITFOR'
, 'SLEEP_TASK', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT'
, 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH', 'XE_DISPATCHER_WAIT'
, 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
order by (e.wait_time_ms - s.wait_time_ms) desc ;
--clean up table
delete from #_wait_stats
where snap_time = @previous_snap_time;
Eseguire una query dei descrittori di buffer per determinare quali oggetti causano la contesa di latch
Lo script seguente esegue una query dei descrittori di buffer per determinare quali oggetti sono associati ai tempi di attesa latch più lunghi.
IF EXISTS (SELECT * FROM tempdb.sys.objects WHERE [name] like '#WaitResources%') DROP TABLE #WaitResources;
CREATE TABLE #WaitResources (session_id INT, wait_type NVARCHAR(1000), wait_duration_ms INT,
resource_description sysname NULL, db_name NVARCHAR(1000), schema_name NVARCHAR(1000),
object_name NVARCHAR(1000), index_name NVARCHAR(1000));
GO
declare @WaitDelay varchar(16), @Counter INT, @MaxCount INT, @Counter2 INT
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'-- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources(session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks wt
WHERE wt.wait_type LIKE 'PAGELATCH%' AND wt.session_id <> @@SPID
--select * from sys.dm_os_buffer_descriptors
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END;
--select * from #WaitResources;
update #WaitResources
set db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources wt
JOIN sys.dm_os_buffer_descriptors bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) + 1, LEN(wt.resource_description) + 1)
--AND wt.file_index > 0 AND wt.page_index > 0
JOIN sys.allocation_units au ON bd.allocation_unit_id = AU.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id;
select * from #WaitResources order by wait_duration_ms desc;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
Script di partizionamento hash
L'uso di questo script è descritto in Usare il partizionamento hash con una colonna calcolata e deve essere personalizzato in base alla propria implementazione.
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Passaggi successivi
Per altre informazioni sugli strumenti di monitoraggio delle prestazioni, vedere Strumenti per il monitoraggio e l'ottimizzazione delle prestazioni.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per