Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo fornisce informazioni approfondite su come identificare e risolvere i problemi relativi alla contesa di spinlock nelle applicazioni DI SQL Server nei sistemi a concorrenza elevata.
Annotazioni
Le raccomandazioni e le procedure consigliate descritte qui si basano sull'esperienza reale durante lo sviluppo e la distribuzione di sistemi OLTP reali. È stato originariamente pubblicato dal team di Consulenza clienti di Microsoft SQL Server (SQLCAT).
Sfondo
In passato, i computer Windows Server di base hanno utilizzato solo uno o due chip microprocessori/CPU e LE CPU sono state progettate con un solo processore o "core". L'aumento della capacità di elaborazione dei computer è stato ottenuto usando CPU più veloci, reso possibile in gran parte attraverso progressi nella densità dei transistor. In seguito alla "Legge di Moore", densità di transistor o il numero di transistor che possono essere posizionati su un circuito integrato hanno costantemente raddoppiato ogni due anni dallo sviluppo della prima CPU a chip singolo per utilizzo generico nel 1971. Negli ultimi anni, l'approccio tradizionale di aumentare la capacità di elaborazione dei computer con CPU più veloci è stato incrementato creando computer con più CPU. A partire da questo articolo, l'architettura della CPU Intel Nehalem supporta fino a otto core per CPU, che quando usata in un sistema socket di otto può quindi essere raddoppiata a 128 processori logici usando la tecnologia SMT (Simultane Multithreading). Nelle CPU Intel, SMT è denominato Hyper-Threading. Man mano che aumenta il numero di processori logici in computer compatibili con x86, i problemi relativi alla concorrenza aumentano man mano che i processori logici competono per le risorse. Questa guida descrive come identificare e risolvere particolari problemi di contesa delle risorse osservati durante l'esecuzione di applicazioni SQL Server in sistemi a concorrenza elevata con alcuni carichi di lavoro.
In questa sezione vengono analizzate le lezioni apprese dal team SQLCAT per diagnosticare e risolvere i problemi di contesa di spinlock. La contesa di spinlock è un tipo di problema di concorrenza osservato nei carichi di lavoro reali dei clienti su sistemi ad alta scala.
Sintomi e cause di contesa di spinlock
Questa sezione descrive come diagnosticare i problemi relativi alla contesa di spinlock, che influisce negativamente sulle prestazioni delle applicazioni OLTP in SQL Server. La diagnosi e la risoluzione dei problemi di spinlock devono essere considerate un argomento avanzato, che richiede una conoscenza degli strumenti di debug e degli elementi interni di Windows.
Gli spinlock sono primitive di sincronizzazione leggere usate per proteggere l'accesso alle strutture di dati. Gli spinlock non sono univoci per SQL Server. Il sistema operativo li usa quando l'accesso a una determinata struttura di dati è necessario solo per un breve periodo di tempo. Quando un thread che tenta di acquisire uno spinlock non è in grado di ottenere l'accesso, esegue un ciclo controllando periodicamente se la risorsa è disponibile anziché cedere immediatamente. Dopo un certo periodo di tempo, un thread in attesa su uno spinlock cederà il controllo prima di poter acquisire la risorsa. La resa consente l'esecuzione di altri thread nella stessa CPU. Questo comportamento è noto come "backoff" (ritirata) e viene illustrato in modo più approfondito più avanti in questo articolo.
SQL Server usa spinlock per proteggere l'accesso ad alcune delle relative strutture di dati interne. Gli spinlock vengono usati all'interno del motore per serializzare l'accesso a determinate strutture di dati in modo simile ai latch. La differenza principale tra un latch e uno spinlock è il fatto che gli spinlock eseguono un ciclo per un periodo di tempo controllando la disponibilità di una struttura di dati, mentre un thread che tenta di acquisire l'accesso a una struttura protetta da un latch cede immediatamente se la risorsa non è disponibile. La resa richiede il cambio di contesto di un thread dalla CPU per permettere l'esecuzione di un altro thread. Si tratta di un'operazione relativamente costosa e, per le risorse che vengono mantenute per un breve periodo di tempo, è più efficiente consentire a un thread di eseguire in un ciclo che verifichi periodicamente la disponibilità della risorsa.
Le modifiche interne apportate al motore di database introdotte in SQL Server 2022 (16.x) rendono gli spinlock più efficienti.
Sintomi
In qualsiasi sistema trafficato ad alta concorrenza, è normale vedere contese attive su strutture a cui si accede frequentemente e che sono protette da spinlock. Questo utilizzo è considerato problematico solo quando la contesa comporta un sovraccarico significativo della CPU. Le statistiche di spinlock vengono esposte dalla sys.dm_os_spinlock_stats DMV (Dynamic Management View) all'interno di SQL Server. Ad esempio, questa query restituisce l'output seguente:
Annotazioni
Altre informazioni sull'interpretazione delle informazioni restituite da questa DMV sono descritte più avanti in questo articolo.
SELECT *
FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;
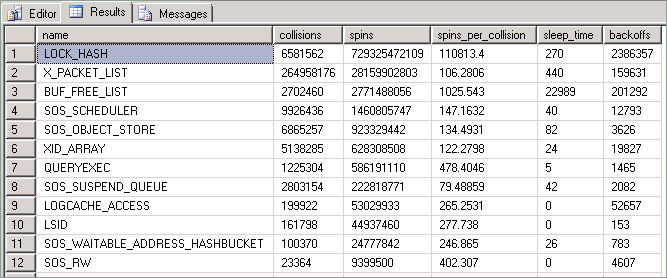
Le statistiche esposte da questa query sono descritte di seguito:
| colonna | Descrizione |
|---|---|
| Collisioni | Questo valore viene incrementato ogni volta che un thread viene bloccato dall'accesso a una risorsa protetta da uno spinlock. |
| Gira | Questo valore viene incrementato per ogni volta che un thread esegue un ciclo durante l'attesa della disponibilità di uno spinlock. Si tratta di una misura della quantità di lavoro eseguita da un thread durante il tentativo di acquisire una risorsa. |
| Spins_per_collision | Rapporto di rotazioni per collisione. |
| Tempo di sospensione | Relativi a eventi di back-off; non pertinente alle tecniche descritte in questo articolo. |
| Backoff | Si verifica quando un thread "rotante" che tenta di accedere a una risorsa mantenuta ha determinato che deve consentire l'esecuzione di altri thread nella stessa CPU. |
Ai fini di questa discussione, le statistiche di particolare interesse sono il numero di collisioni, spin e eventi di backoff che si verificano entro un periodo specifico in cui il sistema è sotto carico elevato. Quando un thread tenta di accedere a una risorsa protetta da uno spinlock, si verifica un conflitto. Quando si verifica un conflitto, il conteggio delle collisioni viene incrementato e il thread inizierà a ruotare in un ciclo e verificherà periodicamente se la risorsa è disponibile. Ogni volta che il thread ruota (cicli) il conteggio delle rotazioni viene incrementato.
Gli spin per collisione sono una misura della quantità di rotazioni che si verificano mentre uno spinlock viene mantenuto da un thread e indica quante rotazioni si verificano mentre i thread mantengono lo spinlock. Ad esempio, un ridotto numero di rotazioni per collisione e un numero elevato di collisioni indica che si verifica un ridotto numero di rotazioni sotto lo spinlock e ci sono molti thread che si contendono. Una grande quantità di rotazioni indica che il tempo impiegato per ruotare nel codice di spinlock è relativamente più duraturo (ovvero, il codice sta attraversando un numero elevato di voci in un bucket hash). Con l'aumentare della contenzione (aumentando così il numero di collisioni), aumenta anche il numero di cicli.
I backoff possono essere considerati in modo simile agli spin. Per evitare un eccessivo spreco di CPU, i spinlock non continuano a girare a tempo indefinito fino a quando non possono accedere a una risorsa mantenuta. Per evitare che uno spinlock utilizzi eccessivamente le risorse della CPU, gli spinlock si disattivano o smettono di girare passando in uno stato di attesa. Gli spinlock si ritirano indipendentemente dal fatto che ottengano la proprietà della risorsa di destinazione. Questa operazione viene eseguita per consentire la pianificazione di altri thread sulla CPU nella speranza che ciò consenta di eseguire un lavoro più produttivo. Il comportamento predefinito per il motore consiste nel ruotare per un intervallo di tempo costante prima di eseguire un calo di intensità. Il tentativo di ottenere uno spinlock richiede che venga mantenuto uno stato di concorrenza della cache, ovvero un'operazione che richiede un utilizzo intensivo della CPU rispetto al costo della rotazione della CPU. Pertanto, i tentativi di ottenere uno spinlock vengono eseguiti con moderazione e non vengono eseguiti ogni volta che un thread ruota. In SQL Server alcuni tipi di spinlock (ad esempio, LOCK_HASH) sono stati migliorati usando un intervallo in aumento esponenziale tra i tentativi di acquisire lo spinlock (fino a un determinato limite), che spesso riduce l'effetto sulle prestazioni della CPU.
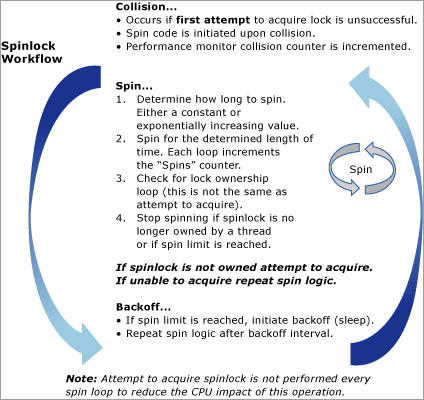
Il diagramma seguente fornisce una visualizzazione concettuale dell'algoritmo spinlock:
Scenari tipici
La contesa di spinlock può verificarsi per un numero qualsiasi di motivi che potrebbero non essere correlati alle decisioni di progettazione del database. Poiché gli spinlock regolano l'accesso alle strutture di dati interne, la contesa degli spinlock non si manifesta allo stesso modo della contesa dei latch dei buffer, che è direttamente influenzata dalle scelte progettuali dello schema e dai modelli di accesso ai dati.
Il sintomo associato principalmente alla contesa di spinlock è un utilizzo elevato della CPU a causa del numero elevato di spin e di molti thread che tentano di acquisire lo stesso spinlock. In generale, questo è stato osservato nei sistemi con 24 e più core CPU, e più comunemente nei sistemi con più di 32 core CPU. Come indicato in precedenza, un certo livello di contesa sui spinlock è normale per i sistemi OLTP a concorrenza elevata con carico significativo e spesso è presente un numero elevato di spin (miliardi/trilioni) segnalati dalla sys.dm_os_spinlock_stats DMV nei sistemi in esecuzione da molto tempo. Anche in questo caso, l'osservazione di un numero elevato di spinlock per qualsiasi tipo di spinlock specificato non è sufficiente per determinare che vi è un impatto negativo sulle prestazioni del carico di lavoro.
Una combinazione di diversi dei sintomi seguenti potrebbe indicare una contesa di spinlock. Se tutte queste condizioni sono vere, eseguire ulteriori indagini sui possibili problemi di contesa di spinlock.
Un numero elevato di spin e backoff viene osservato per un particolare tipo di spinlock.
Il sistema riscontra un utilizzo elevato della CPU o picchi di utilizzo della CPU. Negli scenari di elevato utilizzo della CPU, si registrano alte attese di segnale su
SOS_SCHEDULER_YIELD(segnalate dalla DMVsys.dm_os_wait_stats).Il sistema sta riscontrando una concorrenza elevata.
L'utilizzo e le rotazioni della CPU sono aumentati in modo sproporzionato rispetto alla velocità effettiva.
Un fenomeno comune facilmente diagnosticato è una divergenza significativa nella velocità effettiva e nell'utilizzo della CPU. Molti carichi di lavoro OLTP hanno una relazione tra (velocità effettiva/numero di utenti nel sistema) e utilizzo della CPU. Gli spin elevati osservati in combinazione con una divergenza significativa dell'utilizzo della CPU e della velocità effettiva possono essere un'indicazione della contesa di spinlock che introduce un sovraccarico della CPU. Un aspetto importante da notare è che è anche comune vedere questo tipo di divergenza nei sistemi quando determinate query diventano più costose nel tempo. Ad esempio, le query eseguite su set di dati che eseguono letture logiche più logiche nel tempo possono causare sintomi simili.
Importante
È fondamentale escludere altre cause più comuni della CPU elevata durante la risoluzione di questi tipi di problemi.
Anche se ognuna delle condizioni precedenti è vera, è comunque possibile che la causa radice del consumo elevato della CPU si trovi altrove. Infatti, nella stragrande maggioranza dei casi l'aumento della CPU è dovuto a motivi diversi dalla contesa di spinlock.
Alcune delle cause più comuni per un maggiore consumo di CPU includono:
- Le query che diventano più costose nel tempo a causa della crescita dei dati sottostanti, con conseguente necessità di eseguire letture logiche aggiuntive dei dati residenti in memoria.
- Modifiche nei piani di query che comportano un'esecuzione non ottimale.
Esempi
Nell'esempio seguente è presente una relazione quasi lineare tra il consumo della CPU e la velocità effettiva misurata dalle transazioni al secondo. È normale vedere alcune differenze in questo caso perché il sovraccarico viene incorreto in caso di aumento di qualsiasi carico di lavoro. Come illustrato qui, questa divergenza diventa significativa. Si verifica anche un calo precipitoso della velocità effettiva quando il consumo della CPU raggiunge 100%.

Quando si misura il numero di rotazioni a intervalli di 3 minuti, è possibile osservare un aumento più esponenziale rispetto a quello lineare nelle rotazioni, che indica che la contesa di spinlock potrebbe essere problematica.
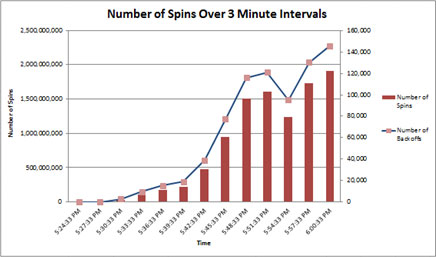
Come indicato in precedenza, il spinlock è più comune nei sistemi caratterizzati da elevata concorrenza quando sono sottoposti a carichi elevati.
Alcuni degli scenari soggetti a questo problema includono:
Problemi di risoluzione dei nomi causati da un errore di qualifica completa dei nomi degli oggetti. Per altre informazioni, vedere Descrizione del blocco di SQL Server causato da blocchi di compilazione. Questo problema specifico è descritto in modo più dettagliato in questo articolo.
Contesa per i bucket hash di blocchi nel gestore dei blocchi per i carichi di lavoro che accedono frequentemente allo stesso blocco, ad esempio un blocco condiviso su una riga spesso letta. Questo tipo di contesa si presenta come un spinlock di tipo
LOCK_HASH. In un caso specifico, è stato rilevato che questo problema è stato riscontrato a causa di modelli di accesso modellati in modo non corretto in un ambiente di test. In questo ambiente, più del numero previsto di thread accedevano costantemente alla stessa riga a causa di parametri di test configurati in modo non corretto.Frequenza elevata delle transazioni DTC quando si verifica un elevato grado di latenza tra i coordinatori delle transazioni MSDTC. Questo problema specifico è documentato in dettaglio nel post di blog di SQLCAT Risoluzione delle attese correlate a DTC e Ottimizzazione della scalabilità di DTC.
Diagnosticare la contesa di spinlock
In questa sezione vengono fornite informazioni per la diagnosi della contesa di spinlock di SQL Server. Gli strumenti principali usati per diagnosticare la contesa di spinlock sono:
| Strumento | Utilizzo |
|---|---|
| Monitoraggio prestazioni | Cercare condizioni di CPU elevate o differenze tra velocità effettiva e utilizzo della CPU. |
| Statistiche di Spinlock | Eseguire una query sulla DMV sys.dm_os_spinlock_stats per cercare un numero elevato di rotazioni ed eventi di backoff in periodi di tempo. |
| Statistiche di attesa | A partire da SQL Server 2025 (17.x) Preview, eseguire una query sui sys.dm_os_wait_stats e sys.dm_exec_session_wait_stats DMV usando il SPINLOCK_EXT tipo di attesa. Richiede trace flag 8134. Per altre informazioni, vedere SPINLOCK_EXT. |
| Eventi estesi di SQL Server | Usato per tenere traccia degli stack di chiamate per i spinlock che riscontrano un numero elevato di rotazioni. |
| Dump della memoria | In alcuni casi, i dump di memoria del processo di SQL Server e gli strumenti di debug di Windows. In generale, questo livello di analisi viene eseguito quando i team di supporto Microsoft sono impegnati. |
Il processo tecnico generale per la diagnosi della contesa di Spinlock di SQL Server è:
Passaggio 1: Determinare la contesa che potrebbe essere correlata allo spinlock.
Passaggio 2: Acquisire le statistiche da
sys.dm_os_spinlock_statsper trovare il tipo di spinlock che riscontra la maggior parte dei conflitti.Passaggio 3: Ottenere i simboli di debug per sqlservr.exe (sqlservr.pdb) e posizionare i simboli nella stessa directory del file di .exe del servizio SQL Server (sqlservr.exe) per l'istanza di SQL Server.\ Per visualizzare gli stack di chiamate per gli eventi backoff, è necessario disporre di simboli per la versione specifica di SQL Server in esecuzione. I simboli per SQL Server sono disponibili in Microsoft Symbol Server. Per altre informazioni su come scaricare i simboli dal server dei simboli Microsoft, vedere Debug con simboli.
Passaggio 4: Usare gli eventi estesi di SQL Server per tracciare gli eventi di backoff per i tipi di spinlock di interesse. Gli eventi da acquisire sono
spinlock_backoffespinlock_backoff_warning.
Gli eventi estesi offrono la possibilità di tenere traccia degli eventi di backoff e rilevare lo stack delle chiamate per le operazioni che più frequentemente tentano di ottenere uno spinlock. Analizzando lo stack di chiamate, è possibile determinare il tipo di operazione che contribuisce alla contesa per qualsiasi particolare spinlock.
Procedura dettagliata per la diagnosi
La procedura dettagliata seguente illustra come usare gli strumenti e le tecniche per diagnosticare un problema di contesa di spinlock in un contesto reale. Questa procedura si basa su un'interazione con i clienti che esegue un test di benchmark per simulare circa 6.500 utenti simultanei su un server con 8 socket, 64 core fisici e 1 TB di memoria.
Sintomi
Sono stati osservati picchi periodici nella CPU, che hanno spinto l'utilizzo della CPU a quasi 100%. È stata osservata una divergenza tra la velocità effettiva e il consumo di CPU che ha portato al problema. Nel momento in cui si è verificato il picco elevato della CPU, è stato stabilito un modello di un numero elevato di rotazioni durante i periodi di utilizzo elevato della CPU a intervalli specifici.
Questo è stato un caso estremo in cui la contesa era così intensa da creare una condizione di convoglio di spinlock. Un convoglio si verifica quando i thread non possono più progredire nell'elaborazione del carico di lavoro, ma spendono invece tutte le risorse di elaborazione tentando di ottenere l'accesso al lucchetto. Il log di monitoraggio delle prestazioni illustra questa divergenza tra la velocità effettiva del log delle transazioni e il consumo della CPU e, in ultima analisi, il picco elevato nell'utilizzo della CPU.
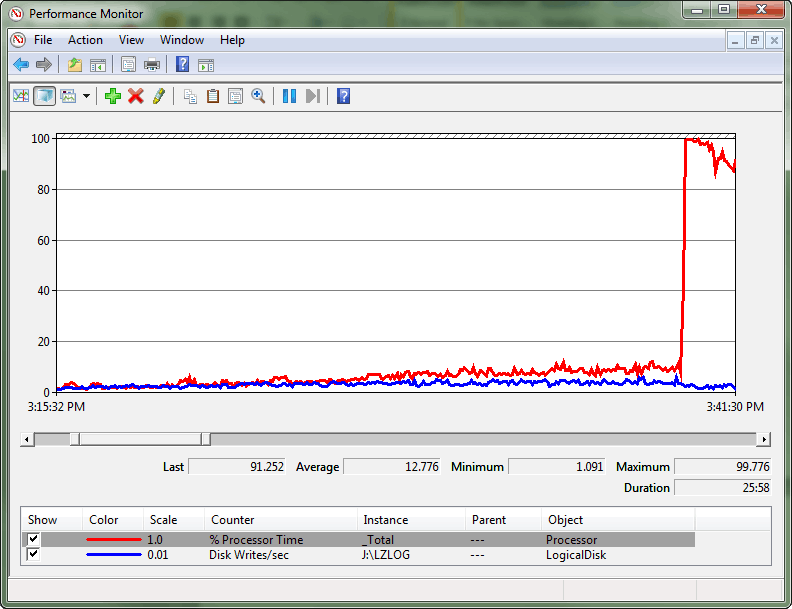
Dopo aver eseguito le query su sys.dm_os_spinlock_stats per determinare l'esistenza di contenzione significativa su SOS_CACHESTORE, è stato utilizzato uno script di eventi estesi per misurare il numero di eventi di backoff per i tipi di spinlock di interesse.
| Nome | Collisioni | Gira | Rotazioni per ogni collisione | Ritardi programmati |
|---|---|---|---|---|
SOS_CACHESTORE |
14,752,117 | 942,869,471,526 | 63,914 | 67,900,620 |
SOS_SUSPEND_QUEUE |
69,267,367 | 473,760,338,765 | 6.840 | 2,167,281 |
LOCK_HASH |
5,765,761 | 260,885,816,584 | 45,247 | 3,739,208 |
MUTEX |
2,802,773 | 9,767,503,682 | 3,485 | 350,997 |
SOS_SCHEDULER |
1,207,007 | 3,692,845,572 | 3,060 | 109,746 |
Il modo più semplice per quantificare l'impatto dei spins è esaminare il numero di eventi di backoff esposti da sys.dm_os_spinlock_stats nell'arco dello stesso intervallo di 1 minuto per il tipo di spinlock con il numero più alto di spins. Questo metodo è preferibile rilevare conflitti significativi perché indica quando i thread esauriscono il limite di rotazione durante l'attesa di acquisire lo spinlock. Lo script seguente illustra una tecnica avanzata che usa eventi estesi per misurare gli eventi di backoff correlati e identificare i percorsi di codice specifici in cui si trova la contesa.
Per altre informazioni sugli eventi estesi in SQL Server, vedere Panoramica degli eventi estesi.
Copione
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketizer target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
Analizzando l'output, è possibile visualizzare gli stack di chiamate per i percorsi di codice più comuni per le SOS_CACHESTORE iterazioni. Lo script è stato eseguito un paio di volte diverse durante il periodo in cui l'utilizzo della CPU era elevato per verificare la coerenza negli stack di chiamate restituiti. Gli stack di chiamate con il numero massimo di bucket di slot sono comuni tra i due output (35.668 e 8.506). Questi stack di chiamate hanno un numero di slot che è due ordini di grandezza maggiore rispetto alla voce immediatamente inferiore. Questa condizione indica un percorso di codice di interesse.
Annotazioni
Non è insolito vedere gli stack di chiamate restituiti dallo script precedente. Quando lo script è stato eseguito per 1 minuto, si è osservato che gli stack di chiamate con un numero di slot pari > a 1.000 erano problematici, ma il numero di slot di > 10.000 era più probabile che fosse problematico poiché si tratta di un numero di slot più elevato.
Annotazioni
La formattazione dell'output seguente è stata pulita per scopi di leggibilità.
Output 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
Output 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
Nell'esempio precedente, gli stack più interessanti hanno i conteggi più alti degli slot (35.668 e 8.506), che in realtà hanno un numero di slot maggiore di 1.000.
Ora la domanda potrebbe essere: "Cosa faccio con queste informazioni"? In generale, è necessaria una conoscenza approfondita del motore di SQL Server per usare le informazioni sullo stack di chiamate e quindi a questo punto il processo di risoluzione dei problemi si sposta in un'area grigia. In questo caso specifico, esaminando gli stack di chiamate, è possibile notare che il percorso del codice in cui si verifica il problema è correlato alle ricerche di sicurezza e metadati (come evidente dagli stack frame CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID)seguenti.
In isolamento, è difficile usare queste informazioni per risolvere il problema, ma ci fornisce alcune idee su dove concentrare la risoluzione dei problemi aggiuntivi per isolare ulteriormente il problema.
Poiché questo problema sembrava correlato ai percorsi di codice che eseguono controlli correlati alla sicurezza, è stato deciso di eseguire un test in cui all'utente dell'applicazione che si connette al database sono stati concessi sysadmin privilegi. Anche se questa tecnica non è mai consigliata in un ambiente di produzione, nell'ambiente di test si è dimostrato un passaggio utile per la risoluzione dei problemi. Quando le sessioni sono state eseguite usando privilegi elevati (sysadmin), i picchi della CPU correlati alla contesa sono scomparsi.
Opzioni e soluzioni alternative
Chiaramente, la risoluzione dei problemi di contesa di spinlock può essere un'attività non semplice. Non esiste un "approccio migliore comune". Il primo passaggio per la risoluzione dei problemi e la risoluzione di eventuali problemi di prestazioni consiste nell'identificare la causa radice. L'uso delle tecniche e degli strumenti descritti in questo articolo è il primo passaggio per eseguire l'analisi necessaria per comprendere i punti di contesa correlati allo spinlock.
Man mano che vengono sviluppate nuove versioni di SQL Server, il motore continua a migliorare la scalabilità implementando codice ottimizzato meglio per i sistemi a concorrenza elevata. SQL Server ha introdotto molte ottimizzazioni per i sistemi a concorrenza elevata, una delle quali è il backoff esponenziale per i più comuni punti di contesa. Sono stati apportati miglioramenti a partire da SQL Server 2012 che hanno migliorato in modo specifico questa particolare area sfruttando algoritmi di backoff esponenziali per tutti gli spinlock all'interno del motore.
Quando si progettano applicazioni di fascia alta che richiedono prestazioni e scalabilità estreme, considerare come mantenere il percorso del codice necessario all'interno di SQL Server il più breve possibile. Un percorso di codice più breve significa che un minor lavoro è eseguito dal motore di database, evitando naturalmente i punti di contesa. Molte procedure consigliate hanno un effetto collaterale sulla riduzione della quantità di lavoro necessaria per il motore e quindi sull'ottimizzazione delle prestazioni del carico di lavoro.
Prendendo come esempi un paio di migliori pratiche menzionate in precedenza in questo articolo:
Nomi completi: I nomi completi di tutti gli oggetti comportano la rimozione della necessità di SQL Server di eseguire percorsi di codice necessari per risolvere i nomi. Sono stati osservati punti di contesa anche sul
SOS_CACHESTOREtipo di spinlock rilevati quando non si utilizzano nomi completi nelle chiamate alle stored procedure. Se non si qualificano completamente questi nomi, è necessario che SQL Server cerchi lo schema predefinito per l'utente, con un percorso di codice più lungo necessario per eseguire SQL.Query con parametri: Un altro esempio consiste nell'usare query con parametri e chiamate di stored procedure per ridurre il lavoro necessario per generare piani di esecuzione. In questo modo viene restituito un percorso di codice più breve per l'esecuzione.
LOCK_HASHContenzione: La contenzione su determinate strutture di blocco o collisioni di bucket hash è inevitabile in alcuni casi. Anche se il motore di SQL Server partiziona la maggior parte delle strutture di blocco, ci sono ancora momenti in cui l'acquisizione di un blocco comporta l'accesso allo stesso bucket hash. Ad esempio, un'applicazione accede alla stessa riga da molti thread contemporaneamente, come dati di riferimento. Questi tipi di problemi possono essere affrontati con tecniche che scalano questi dati di riferimento all'interno dello schema del database o utilizzano il controllo concorrente ottimistico e il blocco ottimizzato, quando possibile.
La prima linea di difesa nell'ottimizzazione dei carichi di lavoro di SQL Server è sempre la procedura di ottimizzazione standard , ad esempio l'indicizzazione, l'ottimizzazione delle query, l'ottimizzazione di I/O e così via. Tuttavia, oltre all'ottimizzazione standard, adottare pratiche che riducono la quantità di codice necessaria per eseguire le operazioni è un approccio importante. Anche quando vengono seguite le procedure consigliate, è comunque possibile che si verifichi la contesa degli spinlock su sistemi occupati ad alta concorrenza. L'uso degli strumenti e delle tecniche in questo articolo può aiutare a isolare o escludere questi tipi di problemi e a determinare quando è necessario coinvolgere le risorse Microsoft appropriate per aiutare.
Appendice: Automatizzare l'acquisizione della memoria di dump
Il seguente script di eventi estesi ha dimostrato di essere utile per automatizzare la raccolta di dump di memoria quando la contesa di spinlock diventa significativa. In alcuni casi, i dump della memoria sono necessari per eseguire una diagnosi completa del problema o sono richiesti dai team Microsoft per eseguire analisi approfondite.
Lo script SQL seguente può essere usato per automatizzare il processo di acquisizione dei dump di memoria per analizzare la contesa di spinlock:
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs;
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
Appendice: Acquisire le statistiche di spinlock nel tempo
Lo script seguente può essere usato per esaminare le statistiche di spinlock in un periodo di tempo specifico. Ogni volta che viene eseguito, restituisce il delta tra i valori correnti e i valori precedenti raccolti.
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;