Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server
SQL Server![]() database SQL di Azure
database SQL di Azure![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure
Prima di SQL Server 2016 (13.x) le dimensioni dei dati all'interno delle righe di un tabella ottimizzata per la memoria non potevano essere superiori a 8.060 byte. A partire da SQL Server 2016 (13.x) e nel database SQL di Azure è possibile creare una tabella ottimizzata per la memoria con più colonne di grandi dimensioni (ad esempio più colonne varbinary(8000)) e colonne LOB (ad esempio colonne varbinary(max), varchar(max) e nvarchar(max)). È anche possibile eseguire operazioni sulle colonne usando moduli Transact-SQL compilati in modo nativo e tipi di tabella.
Le colonne che superano le dimensioni massime delle righe di 8.060 byte vengono inserite all'esterno delle righe, in una tabella interna separata. Ogni colonna all'esterno delle righe ha una corrispondente tabella interna, che a sua volta ha un indice non clusterizzato. Per informazioni dettagliate su queste tabelle interne usate per colonne all'esterno di righe, vedere sys.memory_optimized_tables_internal_attributes..
Esistono alcuni scenari in cui è utile calcolare le dimensioni della riga e della tabella:
Quanta memoria utilizza una tabella.
La quantità di memoria utilizzata dalla tabella non può essere calcolata esattamente. Molti fattori influiscono sulla quantità di memoria utilizzata. ad esempio l'allocazione della memoria basata sul paging, la località, la memorizzazione nella cache e il riempimento. Un altro fattore può essere la presenza di più versioni delle righe a cui sono associate transazioni attive o che sono in attesa di Garbage Collection.
Le dimensioni minime richieste per i dati e gli indici nella tabella si ottengono con il calcolo per
<table size>, descritto di seguito in questo articolo.Il calcolo dell'utilizzo della memoria è nella migliore delle ipotesi un'approssimazione ed è consigliabile includere la pianificazione della capacità nei piani di distribuzione.
Quali sono le dimensioni dei dati di una riga? Tali dimensioni rientrano nel limite di 8.060 byte? Per rispondere a queste domande, usare il calcolo per
<row body size>, descritto più avanti in questo articolo.
Una tabella ottimizzata per la memoria è costituita da una raccolta di righe e di indici contenenti i puntatori alle righe. Nella figura seguente viene illustrata una tabella con indici e righe, ciascuna delle quali contiene intestazioni e corpi di riga.

Calcolare le dimensioni di una tabella
Le dimensioni in memoria di una tabella, in byte, vengono calcolate come segue:
<table size> = <size of index 1> + ... + <size of index n> + (<row size> * <row count>)
Le dimensioni di un indice hash vengono fissate al momento della creazione della tabella e dipendono dal numero effettivo di bucket. Il valore di bucket_count indicato con la definizione dell'indice viene arrotondato per eccesso alla più vicina potenza di 2 per ottenere il numero effettivo di bucket. Ad esempio, se il valore di bucket_count specificato è 100000, il numero effettivo di bucket per l'indice è 131072.
<hash index size> = 8 * <actual bucket count>
Le dimensioni di un indice non cluster corrispondono a <row count> * <index key size>.
Le dimensioni delle righe vengono calcolate aggiungendo l'intestazione e il corpo:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indexes>
Calcolare le dimensioni del corpo di una riga
Le righe di una tabella ottimizzata per la memoria includono i componenti seguenti:
L'intestazione di riga contiene il timestamp necessario per implementare il versionamento delle righe. L'intestazione di riga contiene inoltre il puntatore all'indice per implementare il concatenamento di righe nei contenitori hash (descritti in precedenza).
Il corpo della riga contiene i dati effettivi della colonna, che includono le informazioni ausiliarie come la matrice Null per le colonne che ammettono i valori Null e la matrice di offset per i tipi di dati a lunghezza variabile.
Nella figura seguente viene illustrata la struttura di righe per una tabella con due indici:

I timestamp di inizio e fine indicano il periodo in cui è valida una versione di riga specifica. Le transazioni che iniziano in questo intervallo possono rilevare questa versione di riga. Per altri dettagli, vedere Transazioni con tabelle con ottimizzazione per la memoria.
I puntatori dell'indice puntano alla riga successiva della catena che appartiene al bucket di hash. Nella figura seguente viene illustrata la struttura di una tabella con due colonne (nome, città) e con due indici, uno per il nome della colonna e uno per la città.
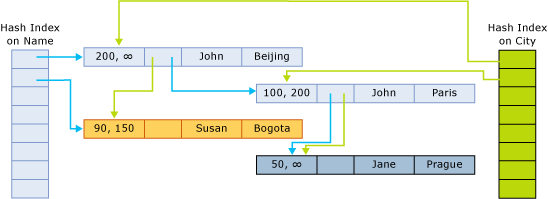
Nella figura, i nomi John e Jane sono sottoposti a hashing al primo bucket.
Susan viene hashato nel secondo bucket. Le città Beijing e Bogota sono sottoposte a hashing nel primo bucket.
Paris e Prague sono hashati nel secondo bucket.
Le catene per l'indice hash sul nome sono pertanto le seguenti:
- Primo contenitore:
(John, Beijing);(John, Paris);(Jane, Prague) - Secondo bucket:
(Susan, Bogota)
Le catene per l'indice sulla città sono le seguenti:
- Primo bucket:
(John, Beijing),(Susan, Bogota) - Secondo secchio:
(John, Paris),(Jane, Prague)
Un timestamp finale ∞ (infinito) indica che si tratta della versione attualmente valida della riga. La riga non è stata aggiornata o eliminata da quando è stata creata questa versione di riga.
Per un tempo superiore a 200, la tabella contiene le seguenti righe.
| Nome | Città |
|---|---|
| John | Pechino |
| Jane | Praga |
Tuttavia, le eventuali transazioni attive con un'ora di inizio 100 vedranno la seguente versione della tabella:
| Nome | Città |
|---|---|
| John | Parigi |
| Jane | Praga |
| Susan | Bogotá |
Il calcolo di <row body size> viene descritto nella tabella seguente.
Le dimensioni del corpo delle righe possono essere considerate da due punti di vista diversi, le dimensioni calcolate e le dimensioni effettive, come illustrato di seguito.
Le dimensioni calcolate, indicate con computed row body size, vengono usate per determinare se il limite di dimensione delle righe pari a 8.060 byte viene superato.
Le dimensioni effettive, indicate con actual row body size, rappresentano le dimensioni di archiviazione effettive del corpo delle righe in memoria e nei file del checkpoint.
Entrambi i valori di computed row body size e actual row body size vengono calcolati in modo analogo. L'unica differenza è il calcolo delle dimensioni delle colonne (n)varchar(i) e varbinary(i), come evidenziato nella parte inferiore della tabella seguente. Per le dimensioni calcolate del corpo delle righe viene usata la dimensione dichiarata i come dimensione della colonna, mentre per le dimensioni effettive del corpo delle righe viene usata la dimensione effettiva dei dati.
Nella tabella seguente viene descritto il calcolo delle dimensioni del corpo della riga, specificate come <actual row body size> = SUM(<size of shallow types>) + 2 + 2 * <number of deep type columns>.
| Sezione | Dimensione | Commenti |
|---|---|---|
| Colonne di tipo poco profondo |
SUM(<size of shallow types>). Le dimensioni in byte dei singoli tipi sono le seguenti:bit: 1tinyint: 1smallint: 2int: 4real: 4Smalldatetimetime: 4smallmoney: 4bigint: 8Ora: 8datatime2: 8float: 8denaro: 8numeric (precisione <= 18): 8ora: 8numeric(precision > 18): 16uniqueidentifier: 16 |
|
| Riempimento delle colonne superficiali | I valori possibili sono:1 se esistono colonne di tipo profondo e le dimensioni totali dei dati delle colonne superficiali sono un numero dispari.In caso contrario, 0 |
I tipi approfonditi sono i tipi (var)binary e (n)(var)char. |
| Array di offset per colonne di tipo profondo | I valori possibili sono:0 se non ci sono colonne di tipo profondoIn caso contrario, 2 + 2 * <number of deep type columns> |
I tipi approfonditi sono i tipi (var)binary e (n)(var)char. |
| Matrice NULL |
<number of nullable columns> / 8 viene arrotondato per eccesso ai byte completi. |
La matrice dispone di 1 bit per ogni colonna che ammette i valori Null. Il valore viene arrotondato per eccesso ai byte completi. |
| Riempimento della matrice NULL | I valori possibili sono:1 se esistono colonne di tipo complesso e la dimensione della matrice NULL è un numero dispari di byte.In caso contrario, 0 |
I tipi approfonditi sono i tipi (var)binary e (n)(var)char. |
| Imbottitura | Se non ci sono colonne di tipo profondo: 0Se sono disponibili colonne di tipo approfondito, vengono aggiunti 0-7 byte di riempimento, in base al maggiore allineamento richiesto da una colonna superficiale. Ogni colonna superficiale richiede un allineamento uguale alle sue dimensioni, come descritto in precedenza, ad eccezione delle colonne GUID che richiedono l'allineamento di 1 byte (non 16) e delle colonne numeriche che richiedono sempre l'allineamento di 8 byte (mai 16). Viene usato il requisito di allineamento più grande tra tutte le colonne superficiali. 0-7 byte di riempimento vengono aggiunti in modo tale che le dimensioni totali fino a questo punto (senza le colonne di tipo approfondito) siano un multiplo dell'allineamento richiesto. |
I tipi approfonditi sono i tipi (var)binary e (n)(var)char. |
| Colonne di tipo approfondito a lunghezza fissa | SUM(<size of fixed length deep type columns>)Le dimensioni di ogni colonna sono le seguenti: i per char(i) e binary(i).2 * i per nchar(i) |
Le colonne di tipo approfondito a lunghezza fissa sono le colonne di tipo char(i), nchar(i) o binary(i). |
| Colonne di tipo complesso a lunghezza variabile dimensione calcolata | SUM(<computed size of variable length deep type columns>)Le dimensioni calcolate di ogni colonna sono le seguenti: i per varchar(i) e varbinary(i)2 * i per nvarchar(i) |
Questa riga si riferiva solo a computed row body size. Le colonne di tipo approfondito a lunghezza variabile sono le colonne di tipo varchar(i), nvarchar(i) o varbinary(i). Le dimensioni calcolate sono determinate dalla lunghezza massima ( i) della colonna. |
| Colonne di tipo approfondito a lunghezza variabile dimensione effettiva | SUM(<actual size of variable length deep type columns>)Le dimensioni effettive di ogni colonna sono le seguenti: n, dove n è il numero di caratteri archiviato nella colonna, per varchar(i).2 * n, dove n è il numero di caratteri archiviato nella colonna, per nvarchar(i).n, dove n è il numero di byte archiviato nella colonna, per varbinary(i). |
Questa riga si riferiva solo a actual row body size. Le dimensioni effettive sono determinate dai dati archiviati nelle colonne della riga. |
Esempio: calcolo delle dimensioni della tabella e delle righe
Per gli indici hash il numero effettivo di bucket viene arrotondato alla più vicina potenza di 2. Ad esempio, se il valore di bucket_count specificato è 100000, il numero effettivo di bucket per l'indice è 131072.
Si consideri una tabella Orders con la definizione seguente:
CREATE TABLE dbo.Orders (
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
CustomerID INT NOT NULL INDEX IX_CustomerID HASH WITH (BUCKET_COUNT = 10000),
OrderDate DATETIME NOT NULL,
OrderDescription NVARCHAR(1000)
)
WITH (MEMORY_OPTIMIZED = ON);
GO
Questa tabella include un indice hash e un indice non cluster (chiave primaria). Ha anche tre colonne a lunghezza fissa e una colonna a lunghezza variabile, con una delle colonne che può essere nullable (OrderDescription). Si supponga che la tabella Orders contenga 8.379 righe e che la lunghezza media dei valori della colonna OrderDescription sia 78 caratteri.
Per determinare le dimensioni della tabella, è innanzitutto necessario determinare le dimensioni degli indici. Il valore di bucket_count per entrambi gli indici è specificato come 10.000. Questo valore viene arrotondato per eccesso alla più vicina potenza di 2: 16.384. Pertanto, le dimensioni totali degli indici della tabella Orders sono:
8 * 16384 = 131072 bytes
Il valore restante corrisponde alle dimensioni dei dati della tabella, ovvero:
<row size> * <row count> = <row size> * 8379
(La tabella di esempio contiene 8.379 righe). A questo punto:
<row size> = <row header size> + <actual row body size>
<row header size> = 24 + 8 * <number of indices> = 24 + 8 * 1 = 32 bytes
A questo punto, calcolare <actual row body size>:
Colonne di tipo poco profondo
SUM(<size of shallow types>) = 4 <int> + 4 <int> + 8 <datetime> = 16Il margine delle colonne superficiali è 0, in quanto le dimensioni totali delle colonne superficiali sono pari.
Matrice di offset per colonne a tipo profondo:
2 + 2 * <number of deep type columns> = 2 + 2 * 1 = 4NULLmatrice = 1Riempimento della matrice
NULL= 1, in quanto la dimensione della matriceNULLè dispari ed è presente una colonna di tipo deep.Riempimento
- 8 è il requisito di allineamento maggiore
- Fino a questo punto le dimensioni corrispondono a 16 + 0 + 4 + 1 + 1 = 22
- Il multiplo più vicino di 8 è 24
- Il riempimento totale è 24 - 22 = 2 byte
Non sono presenti colonne di tipo approfondito a lunghezza fissa (colonne di tipo approfondito a lunghezza fissa: 0).
Le dimensioni effettive della colonna di tipo approfondito sono 2 * 78 = 156. La colonna singola di tipo approfondito
OrderDescriptionha tiponvarchar.
<actual row body size> = 24 + 156 = 180 bytes
Per completare il calcolo:
<row size> = 32 + 180 = 212 bytes
<table size> = 8 * 16384 + 212 * 8379 = 131072 + 1776348 = 1907420
Le dimensioni totali in memoria della tabella sono quindi 2 MB circa. Questo calcolo non tiene conto del potenziale overhead sostenuto dall'allocazione di memoria nonché dell'eventuale controllo delle versioni delle righe richiesto per le transazioni che accedono a questa tabella.
L'effettiva memoria allocata e utilizzata dalla tabella e dai relativi indici può essere ottenuta tramite la query seguente:
SELECT * FROM sys.dm_db_xtp_table_memory_stats
WHERE object_id = object_id('dbo.Orders');
Limitazioni delle colonne fuori dalle righe
Di seguito sono elencate alcune limitazioni e avvertenze relative all'uso di colonne all'esterno di righe in una tabella ottimizzata per la memoria:
- Se una tabella ottimizzata per la memoria ha un indice columnstore, allora tutte le colonne devono rientrare tutte nella riga.
- Tutte le colonne chiave di indice devono essere archiviate all'interno della riga. Se una colonna chiave di indice non può essere contenuta all'interno delle righe, non è possibile aggiungere l'indice.
- Avvertenze relative alla modifica di una tabella ottimizzata per la memoria con colonne all'esterno di righe.
- Per le colonne LOB, la limitazione prevista per le dimensioni è la stessa valida per le tabelle basate su disco (limite di 2 GB per colonne LOB).
- Per prestazioni ottimali, è consigliabile che la maggior parte delle colonne rientri in 8.060 byte.
- I dati fuori riga possono causare un utilizzo eccessivo della memoria e/o del disco.