Indici columnstore - Linee guida per il caricamento di dati
Si applica a: ![]() SQL Server
SQL Server ![]() database SQL di Azure
database SQL di Azure ![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Piattaforma di strumenti analitici (PDW)
Piattaforma di strumenti analitici (PDW)
Opzioni e suggerimenti per il caricamento di dati in un indice columnstore usando i metodi standard di caricamento bulk e con inserimento singolo di SQL. Il caricamento di dati in un indice columnstore è una parte essenziale di qualsiasi processo di data warehousing perché i dati vengono spostati nell'indice in preparazione per l'analisi.
Se non si ha esperienza con gli indici columnstore, Vedere Indici columnstore - Panoramica e Architettura degli indici columnstore.
Che cos'è il caricamento bulk?
Il termine caricamento bulk fa riferimento al modo in cui viene aggiunto un numero elevato di righe a un archivio dati. Questo è il modo che offre le prestazioni migliori per spostare i dati in un indice columnstore, perché si basa su batch di righe. Il caricamento bulk riempie i rowgroup fino alla capacità massima e li comprime direttamente nel columnstore. Solo le righe alla fine di un carico che non soddisfano il requisito minimo di 102.400 righe per ogni rowgroup passano all'archivio differenziale.
Per eseguire un caricamento bulk è possibile usare l'utilità bcp, Integration Services oppure selezionare righe da una tabella di staging.
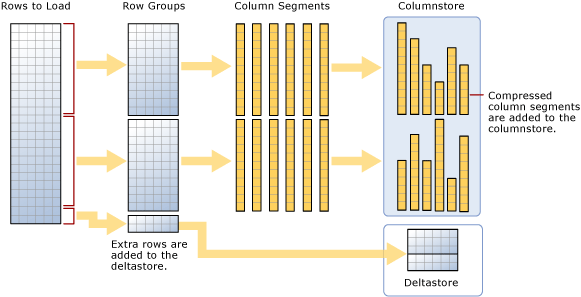
Come illustrato nel diagramma, un caricamento bulk:
- Non pre-ordina i dati. I dati vengono inseriti nei rowgroup secondo l'ordine di ricezione.
- Se le dimensioni del batch sono >= 102.400, le righe vengono caricate direttamente nei gruppi di dati compressi. Perché l'importazione in blocco sia efficiente, è consigliabile scegliere una dimensione di batch >= 102400 in modo da evitare lo spostamento di righe di dati in rowgroup delta prima che le righe siano spostate nei rowgroup compressi da un thread in background, il motore di tuple (TM).
- Se le dimensioni del batch sono < 102.400 o se le righe rimanenti sono < 102.400, le righe vengono caricate in rowgroup delta.
Nota
In una tabella rowstore con dati di un indice columnstore non cluster, SQL Server inserisce sempre i dati nella tabella di base. I dati non vengono mai inseriti direttamente nell'indice columnstore.
Il caricamento bulk include le ottimizzazioni seguenti per le prestazioni:
Caricamenti in parallelo: è possibile eseguire in simultanea più caricamenti bulk (bcp o bulk insert), ognuno dei quali carica un file di dati separato. Diversamente dai caricamenti bulk di rowstore in SQL Server, non è necessario specificare
TABLOCK, poiché ogni thread di importazione in blocco caricherà i dati esclusivamente in un rowgroup distinto (compresso o delta) con un blocco esclusivo.Registrazione ridotta: i dati caricati direttamente in gruppi di righe compressi portano a una riduzione significativa delle dimensioni del log. Se, ad esempio, i dati sono stati compressi 10 volte, il log delle transazioni corrispondente sarà di circa 10 volte più piccolo senza richiedere TABLOCK o il modello di recupero con registrazione minima delle operazioni bulk o con registrazione in blocco. Per tutti i dati destinati a un rowgroup differenziale viene usata la registrazione completa. Ciò include qualsiasi dimensione di batch minore di 102.400 righe. La procedura consigliata corrisponde all'uso di batchsize >= 102.400. Poiché non è necessario usare TABLOCK, è possibile caricare i dati in parallelo.
Registrazione minima: è possibile ottenere ulteriori riduzioni nella registrazione se si soddisfano i prerequisiti per la registrazione minima. Tuttavia, a differenza del caricamento dei dati in un rowstore, TABLOCK causa un blocco X (esclusivo) sulla tabella anziché un blocco BU (aggiornamento bulk) e pertanto non è possibile eseguire il caricamento parallelo dei dati. Per altre informazioni sul blocco, vedere Utilizzo di blocchi e controllo delle versioni delle righe.
Ottimizzazione dei blocchi: il blocco X su un gruppo di righe viene acquisito automaticamente durante il caricamento dei dati in un gruppo di righe compresso. Durante il caricamento bulk in un rowgroup delta, tuttavia, viene acquisito un blocco X in corrispondenza del rowgroup, ma SQL Server continua a bloccare la pagina o l'extent perché il blocco X del rowgroup non rientra nella gerarchia di blocco.
In presenza di un indice albero B non cluster su un indice columnstore non sono previsti il blocco o l'ottimizzazione della registrazione per l'indice, ma le ottimizzazioni sull'indice columnstore cluster descritte in precedenza sono ancora applicabili.
La modifica dei dati (inserimento, eliminazione, aggiornamento) non è un'operazione in modalità batch perché non è parallela.
Pianificare le dimensioni di caricamento bulk per ridurre al minimo i rowgroup differenziali
Gli indici columnstore offrono prestazioni ottimali quando la maggior parte delle righe viene compressa in columnstore e non inserita nei rowgroup differenziali. È consigliabile ridimensionare i carichi in modo che le righe vengano spostate direttamente nel columnstore ignorando il più possibile l'archivio differenziale.
Gli scenari seguenti indicano quando le righe caricate vengono direttamente indirizzate al columnstore o passano per il deltastore. Nell'esempio, ogni rowgroup può avere 102.400-1.048.576 righe per rowgroup. In pratica, la dimensione massima di un rowgroup può essere inferiore a 1.048.576 righe quando è presente un utilizzo elevato di memoria.
| Righe per il caricamento bulk | Righe aggiunte al rowgroup compresso | Righe aggiunte al rowgroup delta |
|---|---|---|
| 102.000 | 0 | 102.000 |
| 145.000 | 145.000 Dimensioni rowgroup: 145.000. |
0 |
| 1.048.577 | 1.048.576 Dimensioni rowgroup: 1.048.576. |
1 |
| 2.252.152 | 2.252.152 Dimensioni rowgroup: 1.048.576, 1.048.576, 155.000. |
0 |
Nell'esempio seguente vengono illustrati i risultati del caricamento di 1.048.577 righe in una tabella. I risultati mostrano che esiste un rowgroup COMPRESSED nel columnstore (come segmenti di colonna compressi) e 1 riga nel deltastore.
SELECT object_id, index_id, partition_number, row_group_id, delta_store_hobt_id,
state, state_desc, total_rows, deleted_rows, size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats;

Usare una tabella di staging per migliorare le prestazioni
Se si caricano i dati solo per inserirli temporaneamente prima di eseguire altre trasformazioni, il caricamento della tabella in una tabella heap è molto più rapido del caricamento dei dati in una tabella columnstore cluster. Inoltre, il caricamento dei dati in una [tabella temporanea][Temporanea] avverrà molto più velocemente del caricamento di una tabella in un archivio permanente.
Il criterio comune per il caricamento di dati consiste nel caricare i dati in una tabella di staging, eseguire alcune trasformazioni e quindi caricarli nella tabella di destinazione usando il comando seguente
INSERT INTO [<columnstore index>]
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Il comando carica i dati nell'indice columnstore in modo analogo ai comandi bcp o bulk insert, ma in un unico batch. Se il numero di righe nella tabella di staging è < 102.400, le righe vengono caricate in un rowgroup delta, altrimenti possono essere caricate direttamente in un rowgroup compresso. Uno dei limiti principali era il fatto che l'operazione INSERT è a thread singolo. Per caricare i dati in parallelo era possibile creare più tabelle di staging o eseguire i comandi INSERT/SELECT con intervalli non sovrapposti di righe dalla tabella di staging. Questa limitazione è stata risolta in SQL Server 2016 (13.x). Il comando seguente carica i dati dalla tabella di staging in parallelo, ma è necessario specificare TABLOCK. Questo comportamento può sembrare in contraddizione con quanto affermato in precedenza con bulkload, ma la differenza principale è che il caricamento parallelo dei dati dalla tabella di staging viene eseguito nella stessa transazione.
INSERT INTO [<columnstore index>] WITH (TABLOCK)
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Per il caricamento in indici columnstore cluster da una tabella di staging sono disponibili le ottimizzazioni seguenti:
- Ottimizzazione dei log: con registrazione minima quando i dati vengono caricati in un rowgroup compresso.
- Ottimizzazione del blocco: durante il caricamento dei dati in un rowgroup compresso, viene acquisito il blocco X sul rowgroup. Tuttavia, quando si opera con rowgroup delta viene acquisito il blocco X del rowgroup, ma SQL Server continua a bloccare i blocchi di pagina/extent perché il blocco X del rowgroup non rientra nella gerarchia di blocco.
In presenza di uno più indici non cluster, non si verifica il blocco o l'ottimizzazione della registrazione dell'indice, ma le ottimizzazioni sull'indice columnstore cluster descritte in precedenza sono ancora presenti.
Che cos'è il caricamento con inserimento singolo?
L'inserimento singolo indica il modo in cui le singole righe vengono spostate nell'indice columnstore. Per gli inserimenti singoli viene usata l'istruzione INSERT INTO e tutte le righe vengono spostate nell'archivio differenziale. Ciò è utile per un numero limitato di righe, ma non è pratico per caricamenti di grandi dimensioni.
INSERT INTO [<table-name>] VALUES ('some value' /*replace with actual set of values*/)
Nota
I thread simultanei che usano INSERT INTO per inserire valori in un indice columnstore cluster possono inserire righe nello stesso rowgroup deltastore.
Quando il rowgroup arriva a contenere 1.048.576 righe viene contrassegnato come chiuso, ma è ancora disponibile per query e operazioni di aggiornamento/eliminazione. Le righe appena inserite vengono indirizzate a un rowgroup deltastore nuovo o esistente. In background agisce il motore di tuple (TM), che comprime i rowgroup delta chiusi ogni 5 minuti circa. È possibile richiamare in modo esplicito il comando seguente per comprimere il rowgroup delta chiuso:
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE
Per forzare un rowgroup delta chiuso e compresso, eseguire il comando seguente. È consigliabile eseguire questo comando al termine del caricamento delle righe, quando non si prevede l'aggiunta di nuove righe. La chiusura e la compressione esplicita del rowgroup delta consente di risparmiare spazio di archiviazione e incrementare le prestazioni delle query di analisi. È consigliabile richiamare questo comando quando non si prevede l'inserimento di nuove righe.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE with (COMPRESS_ALL_ROW_GROUPS = ON)
Come funziona il caricamento in una tabella partizionata
Per i dati partizionati, SQL Server assegna prima ogni riga a una partizione, quindi esegue operazioni columnstore sui dati nella partizione. Ogni partizione ha i propri rowgroup e almeno un rowgroup differenziale.
Passaggi successivi
- Data Loading performance considerations with Clustered Columnstore indexes (Considerazioni sulle prestazioni di caricamento dei dati con indici columnstore cluster).
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per