Heap (tabelle senza indici cluster)
Si applica a:![]() SQL Server
SQL Server![]() Database SQL di Azure
Database SQL di Azure![]() Istanza gestita di SQL di Azure
Istanza gestita di SQL di Azure
Un heap è una tabella per cui non è disponibile un indice cluster. Nelle tabelle archiviate come heap è possibile creare uno o più indici non cluster. I dati vengono archiviati nell'heap senza un ordine specificato. In genere i dati vengono inizialmente archiviati nell'ordine in cui vengono inserite le righe. Tuttavia, il motore di database può spostare i dati nell'heap per archiviare le righe in modo efficiente. Nei risultati della query non è possibile stimare l'ordine dei dati. Per garantire l'ordine delle righe restituite da un heap, usare la ORDER BY clausola . Per specificare un ordine logico permanente per l'archiviazione delle righe, creare un indice cluster nella tabella, in modo che non sia un heap.
Nota
Esistono talvolta motivi per i quali è preferibile lasciare una tabella come heap invece di creare un indice cluster, tuttavia l'utilizzo efficiente degli heap richiede competenze avanzate. Alla maggior parte delle tabelle deve essere associato un indice cluster selezionato con attenzione a meno che non sussista un motivo valido per cui la tabella debba rimanere un heap.
Quando usare un heap
Un heap è ideale per le tabelle che vengono spesso troncate e ricaricate. Il motore di database ottimizza lo spazio in un heap riempiendo lo spazio disponibile meno recente.
Considerare quanto segue:
- L'individuazione dello spazio disponibile in un heap può essere costosa, soprattutto se sono state apportate molte eliminazioni o aggiornamenti.
- Gli indici cluster offrono prestazioni costanti per le tabelle che non vengono spesso troncate.
Per le tabelle che vengono troncate o ricreate regolarmente, ad esempio tabelle temporanee o di staging, l'uso di un heap è spesso più efficiente.
La scelta tra l'uso di un heap e un indice cluster può influire significativamente sulle prestazioni e sull'efficienza del database.
Quando si archivia una tabella come heap, le singole righe vengono identificate tramite riferimento a un identificatore di riga (RID) di 8 byte costituito da numero del file, numero della pagina di dati e slot nella pagina (FileID:PageID:SlotID). L'ID di riga è una struttura piccola ed efficiente.
Gli heap possono essere usati come tabelle di staging per operazioni di inserimento di grandi dimensioni e non ordinate. Poiché i dati vengono inseriti senza applicare un ordine rigoroso, l'operazione di inserimento è in genere più veloce rispetto all'inserimento equivalente in un indice cluster. Se i dati dell'heap verranno letti ed elaborati in una destinazione finale, può essere utile creare un indice ristretto non cluster che copre il predicato di ricerca usato dalla query.
Nota
I dati vengono recuperati da un heap in ordine di pagine di dati, ma non necessariamente nell'ordine in cui sono stati inseriti i dati.
A volte i professionisti esperti di elaborazione dati usano gli heap anche quando l'accesso ai dati avviene sempre attraverso indici non cluster e il RID risulta più piccolo di una chiave di indice cluster.
Se una tabella è un heap e non ha indici non cluster, per individuare qualsiasi riga è necessario leggere l'intera tabella (scansione di tabella). SQL Server non consente di cercare un RID direttamente nell'heap. Questo comportamento può essere accettabile quando la tabella è piccola.
Quando non usare un heap
Non utilizzare un heap quando i dati vengono restituiti di frequente con un ordinamento. Un indice cluster nella colonna di ordinamento può evitare l'esecuzione dell'operazione di ordinamento.
Non utilizzare un heap quando i dati vengono spesso raggruppati insieme. I dati devono essere ordinati prima di essere raggruppati, pertanto un indice cluster nella colonna di ordinamento può evitare l'esecuzione dell'operazione di ordinamento.
Non utilizzare un heap quando si eseguono spesso query su intervalli di dati della tabella. Un indice cluster nella colonna dell'intervallo evita l'ordinamento dell'intero heap.
Non utilizzare un heap quando non sono presenti indici non cluster e la tabella è di grandi dimensioni. L'unica applicazione per questa progettazione consiste nel restituire l'intero contenuto della tabella senza alcun ordine specificato. In un heap motore di database legge tutte le righe per trovare qualsiasi riga.
Non usare un heap se i dati vengono aggiornati di frequente. Se si aggiorna un record e l'aggiornamento usa più spazio nelle pagine di dati rispetto a quello attualmente in uso, è necessario spostare il record in una pagina di dati con spazio libero sufficiente. In questo modo viene creato un record inoltrato che punta alla nuova posizione dei dati e il puntatore di inoltro deve essere scritto nella pagina che conteneva i dati in precedenza, per indicare la nuova posizione fisica. Questa operazione introduce frammentazione nell'heap. Quando motore di database analizza un heap, segue questi puntatori. Questa azione limita le prestazioni read-ahead e può comportare operazioni di I/O aggiuntive che riducono le prestazioni di analisi.
Gestire gli heap
Per creare un heap, creare una tabella senza un indice cluster. Se la tabella dispone già di un indice cluster, rimuoverlo per restituire la tabella a un heap.
Per rimuovere un heap, creare un indice cluster nell'heap.
Per ricompilare un heap per recuperare lo spazio sprecato:
- Creare un indice cluster nell'heap e quindi rimuovere tale indice cluster.
- Usare il comando
ALTER TABLE ... REBUILDper ricompilare l'heap.
Avviso
Per la creazione o la rimozione di indici cluster è richiesta la riscrittura dell'intera tabella. Se la tabella dispone di indici non cluster, è necessario ricrearli tutti ogni volta che l'indice cluster viene modificato. Pertanto, il passaggio da un heap a una struttura di indice cluster o viceversa può richiedere molto tempo e spazio su disco per riordinare i dati in tempdb.
Identificare gli heap
La query seguente restituisce un elenco di heap dal database corrente. L'elenco include:
- Nomi di tabella
- Nomi schema
- Numero di righe
- Dimensioni della tabella in KB
- Dimensioni dell'indice in KB
- Spazio inutilizzato
- Colonna per identificare un heap
SELECT t.name AS 'Your TableName',
s.name AS 'Your SchemaName',
p.rows AS 'Number of Rows in Your Table',
SUM(a.total_pages) * 8 AS 'Total Space of Your Table (KB)',
SUM(a.used_pages) * 8 AS 'Used Space of Your Table (KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS 'Unused Space of Your Table (KB)',
CASE
WHEN i.index_id = 0
THEN 'Yes'
ELSE 'No'
END AS 'Is Your Table a Heap?'
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE i.index_id <= 1 -- 0 for Heap, 1 for Clustered Index
GROUP BY t.name,
s.name,
i.index_id,
p.rows
ORDER BY 'Your TableName';
Strutture heap
Un heap è una tabella per cui non è disponibile un indice cluster. Agli heap corrisponde una riga in sys.partitionscon index_id = 0 per ogni partizione usata dall'heap. Per impostazione predefinita, a ogni heap è associata una singola partizione. Se a un heap sono associate più partizioni, ognuna di esse ha una struttura di heap contenente i dati per la partizione specifica. Ad esempio, se a un heap sono associate quattro partizioni, saranno presenti quattro strutture di heap, una per ogni partizione.
A seconda dei tipi di dati dell'heap, ogni struttura di heap conterrà una o più unità di allocazione per l'archiviazione e la gestione dei dati di una partizione specifica. Ogni heap conterrà almeno un'unità di allocazione IN_ROW_DATA per partizione e un'unità di allocazione LOB_DATA per partizione, se l'heap include colonne LOB (Large Object). Conterrà anche un'unità di allocazione ROW_OVERFLOW_DATA per partizione, se include colonne a lunghezza variabile che superano il limite della lunghezza di riga di 8.060.
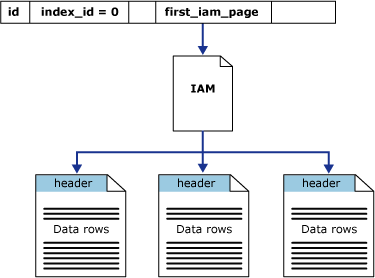
La colonna first_iam_page nella vista di sistema sys.system_internals_allocation_units punta alla prima pagina IAM nella catena di pagine IAM che gestiscono lo spazio allocato all'heap in una partizione specifica. SQL Server usa le pagine IAM per spostarsi all'interno dell'heap. Le pagine di dati e le righe in esse incluse non sono disposte in base a un ordine specifico e non sono collegate tra loro. L'unico collegamento logico tra le pagine di dati sono le informazioni registrate nelle pagine IAM.
Importante
La vista di sistema sys.system_internals_allocation_units è riservata per il solo uso interno a SQL Server. Non è garantita la compatibilità con le versioni future.
Le analisi di tabella o le letture seriali dell'heap possono essere eseguite mediante l'analisi delle pagine IAM allo scopo di individuare gli extent che includono le pagine dell'heap. Poiché le pagine IAM rappresentano gli extent nello stesso ordine in cui sono disposti nel file di dati, le analisi seriali dell'heap vengono eseguite progressivamente in ogni file. Inoltre, se si imposta la sequenza di analisi tramite le pagine IAM, le righe dell'heap non vengono in genere restituite in base all'ordine in cui sono state inserite.
La figura seguente illustra l'uso delle pagine IAM nel motore di database di SQL Server per recuperare le righe di dati di un heap relativo a una singola partizione.
Contenuto correlato
CREATE INDEX (Transact-SQL)
DROP INDEX (Transact-SQL)
Descrizione di indici cluster e non cluster.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per