Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Sistema di Piattaforma Analitica (PDW)
Sistema di Piattaforma Analitica (PDW)![]() Database SQL in Microsoft Fabric
Database SQL in Microsoft Fabric
SQL Server usa join per recuperare dati da più tabelle in base alle relazioni logiche tra di esse. I join sono fondamentali per le operazioni di database relazionali e consentono di combinare i dati di due o più tabelle in un singolo set di risultati.
SQL Server implementa sia operazioni di join logico (definite dalla sintassi di Transact-SQL) che operazioni di join fisico (gli algoritmi effettivi usati per eseguire i join). Comprendere entrambi gli aspetti consente di scrivere query efficienti e ottimizzare le prestazioni del database.
Le operazioni di join logico includono:
- Inner join
- Left, right e full outer join
- Cross join
Le operazioni di join fisico includono:
- Join a cicli annidati
- Merge join
- Hash join
- Join adattivi (si applica a: SQL Server 2017 (14.x) e versioni successive)
Questo articolo illustra come funzionano i join, quando usare tipi di join diversi e in che modo Query Optimizer seleziona l'algoritmo di join più efficiente in base a fattori quali le dimensioni della tabella, gli indici disponibili e la distribuzione dei dati.
Note
Per altre informazioni sulla sintassi di join, vedere Clausola FROM più JOIN, APPLY, PIVOT.
Nozioni fondamentali sul join
I join consentono di recuperare dati da due o più tabelle in base alle relazioni logiche esistenti tra le tabelle stesse. I join indicano la modalità con cui SQL Server usa i dati di una tabella per la selezione di righe in un'altra tabella.
Una condizione di join definisce il modo in cui due tabelle sono correlate in una query in base agli elementi seguenti:
- L'impostazione della colonna di ogni tabella da utilizzare per il join. In una condizione di join tipica viene specificata una chiave esterna di una tabella e la chiave associata nell'altra tabella.
- L'indicazione di un operatore logico, ad esempio = o <>, da usare per il confronto dei valori delle colonne.
I join vengono espressi logicamente usando la sintassi Transact-SQL seguente:
[ INNER ] JOINLEFT [ OUTER ] JOINRIGHT [ OUTER ] JOINFULL [ OUTER ] JOINCROSS JOIN
Gli inner join possono essere specificati nelle clausole FROM o WHERE. Gli outer join e i cross join possono essere specificati solo nella clausola FROM. Le condizioni di join vengono usate insieme alle condizioni di ricerca delle clausole WHERE e HAVING per definire le righe da selezionare nelle tabelle di base a cui viene fatto riferimento nella clausola FROM.
L'impostazione delle condizioni di join nella clausola FROM consente di separare queste condizioni da altre condizioni di ricerca specificate nella clausola WHERE. Corrisponde anche al metodo consigliato per l'impostazione dei join. La sintassi ISO semplificata per la definizione di un join nella clausola FROM è la seguente:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- join_type specifica il tipo di join da eseguire: inner, outer o cross join. Per spiegazioni dei diversi tipi di join, vedere clausola FROM.
- La join_condition definisce il predicato da valutare per ogni coppia di righe unite in join.
Il seguente codice è un esempio di specifica di join nella clausola FROM:
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
Il seguente codice è un'istruzione SELECT semplice che usa tale join:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
L'istruzione SELECT restituisce informazioni sul prodotto e sul fornitore per ogni combinazione di prodotti con prezzo maggiore di $ 10 fornito da una società il cui nome inizia con la lettera F.
Se in una singola query viene fatto riferimento a più tabelle, nessuno dei riferimenti alle colonne deve presentare ambiguità. Nell'esempio precedente entrambe le tabelle ProductVendor e Vendor includono una colonna denominata BusinessEntityID. I nomi di colonna duplicati in due o più tabelle a cui viene fatto riferimento nella query devono essere qualificati con il nome della tabella. Nell'esempio, tutti i riferimenti alle colonne Vendor sono qualificati.
Quando un nome di colonna non viene duplicato in due o più tabelle usate nella query, i riferimenti non devono essere qualificati con il nome della tabella. come illustrato nell'esempio precedente.
SELECT Una clausola di questo tipo è talvolta difficile da comprendere perché non c'è nulla da indicare la tabella che ha fornito ogni colonna. La query risulta più leggibile se tutte le colonne sono qualificate con i nomi delle rispettive tabelle. Il grado di leggibilità aumenta ulteriormente se si utilizzano gli alias di tabella, soprattutto quando è necessario qualificare anche i nomi delle tabelle con il nome del database e del proprietario. Il seguente codice equivale all'esempio precedente. Per rendere la query più leggibile, sono stati però assegnati alias alle tabelle e i nomi di colonna sono stati qualificati con gli alias di tabella:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
Negli esempi precedenti le condizioni di join sono specificate nella clausola FROM (metodo consigliato). La query seguente contiene la stessa condizione di join specificata nella clausola WHERE:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
L'elenco SELECT per un join può fare riferimento a tutte le colonne delle tabelle unite in join o a qualsiasi subset delle colonne. L'elenco SELECT non deve contenere colonne di ogni tabella nel join. Ad esempio, in un join tra tre tabelle è possibile utilizzare una sola tabella come collegamento tra le altre due e le colonne di tale tabella non devono essere necessariamente incluse nell'elenco di selezione. Questa operazione è detta anche anti semi join.
Sebbene le condizioni di join includano in genere confronti di uguaglianza (=), è possibile specificare altri operatori di confronto o relazionali e altri predicati. Per altre informazioni, vedere Operatori di confronto e WHERE.
Durante l'elaborazione di join in SQL Server, Query Optimizer sceglie il metodo di elaborazione del join più efficiente tra quelli possibili. Ciò include la scelta del tipo di join fisico più efficiente, l'ordine in cui verranno unite le tabelle e anche l'uso di tipi di operazioni di join logico che non possono essere espresse direttamente con Transact-SQL sintassi, ad esempio semi join e anti semi join. L'esecuzione fisica di vari join può usare molte ottimizzazioni diverse e pertanto non può essere stimata in modo affidabile. Per altre informazioni sui semi join e sui semi join, vedere Informazioni di riferimento sugli operatori showplan logici e fisici.
Le colonne usate in una condizione di join non devono avere lo stesso nome o essere lo stesso tipo di dati. Tuttavia, se i tipi di dati non sono identici, devono essere compatibili o essere tipi che SQL Server può convertire in modo implicito. Se i tipi di dati non possono essere convertiti in modo implicito, la condizione di join deve convertire in modo esplicito il tipo di dati usando la CAST funzione . Per altre informazioni sulle conversioni implicite ed esplicite, vedere Conversione del tipo di dati (motore di database).
La maggior parte delle query che includono un join possono essere riformulate specificando una subquery, ovvero una query nidificata in un'altra query. La maggior parte delle subquery possono a loro volta essere riformulate come join. Per altre informazioni sulle sottoquery, vedere Sottoquery (SQL Server).
Note
Le tabelle non possono essere unite direttamente in join in colonne ntext, text o image. Tuttavia, è possibile unire le tabelle in join indirettamente in base alle colonne di tipo ntext, text o image usando SUBSTRING.
Ad esempio, SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) esegue un inner join tra due tabelle sui primi 20 caratteri di ogni colonna di tipo text delle tabelle t1 e t2.
È possibile anche confrontare colonne di tipo ntext e text di due tabelle confrontando la lunghezza delle colonne con una clausola WHERE, come illustrato nell'esempio seguente: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
Informazioni sui join a cicli annidati
Se l'input di un join è ridotto (inferiore a 10 righe) e l'input dell'altro join è molto esteso e indicizzato in base alle rispettive colonne di join, l'operazione di join più rapida è rappresentata dai nested loop join indicizzati poiché questi richiedono la minore quantità di I/O e il minor numero di operazioni di confronto.
Il join a cicli annidati, detto anche iterazione nidificata, usa un input di join come tabella di input esterna, visualizzata come input superiore nel piano di esecuzione grafico, e un input di join come tabella di input interna (inferiore). Il ciclo esterno elabora la tabella di input esterna, una riga alla volta. Il ciclo interno, eseguito per ogni riga esterna, cerca le righe corrispondenti nella tabella di input interna.
Nel caso più semplice, ovvero un join a cicli annidati di tipo naive, la ricerca comporta l'analisi di un'intera tabella o indice. Se la ricerca sfrutta un indice, viene chiamato join di cicli annidati di indice. Se l'indice viene compilato come parte del piano di query (e eliminato al completamento della query), viene chiamato join di cicli annidati di indice temporaneo. Tutte queste varianti vengono elaborate da Query Optimizer.
Un nested loop join è particolarmente efficace se l'input esterno è di dimensioni ridotte mentre l'input interno è preindicizzato e di dimensioni notevoli. In molte transazioni di dimensioni ridotte, ad esempio quelle relative a set di righe limitati, i nested loop join indicizzati offrono prestazioni superiori rispetto ai merge join e agli hash join. Per le query di notevoli dimensioni, tuttavia, i nested loop join rappresentano raramente la scelta ottimale.
Quando l'attributo OPTIMIZED dell'operatore di join a cicli annidati viene impostato su True, significa che vengono usati cicli annidati ottimizzati (o l'ordinamento in batch) per ridurre al minimo le operazioni di I/O quando la tabella interna è di grandi dimensioni, indipendentemente dal fatto che sia parallelizzata o meno. La presenza di questa ottimizzazione in un determinato piano potrebbe non essere ovvia durante l'analisi di un piano di esecuzione, dato che l'ordinamento stesso è un'operazione nascosta. La presenza dell'attributo OPTIMIZED nel codice XML del piano, tuttavia, indica che il join a cicli annidati potrebbe tentare di riordinare le righe di input per migliorare le prestazioni di I/O.
Merge join
Se i due input di join non sono di piccole dimensioni, ma vengono ordinati sulla colonna join( ad esempio, se sono stati ottenuti analizzando gli indici ordinati), un join di merge è l'operazione di join più veloce. Se entrambi gli input di join sono di dimensioni notevoli e analoghe, un merge join con ordinamento eseguito in precedenza e un hash join offrono prestazioni simili. Le operazioni di hash join, tuttavia, risultano spesso molto più rapide se le dimensioni dei due input differiscono in modo significativo.
Il merge join richiede l'ordinamento di entrambi gli input per le colonne di merge, definite dalle clausole di uguaglianza (ON) del predicato di join. In genere Query Optimizer esegue l'analisi di un indice, se questo esiste nel set di colonne, oppure inserisce un operatore di ordinamento sotto il merge join. In rari casi possono esistere più clausole di uguaglianza, ma le colonne di merge vengono ricavate soltanto da alcune delle clausole disponibili.
Poiché ogni input è ordinato, l'operatore Merge Join recupera una riga da ogni input ed esegue il confronto tra le righe. Ad esempio, per operazioni di inner join, le righe vengono restituite se sono uguali. Se non sono uguali, la riga con valore inferiore viene eliminata e un'altra riga viene ottenuta da tale input. Questo processo si ripete fino al completamento dell'elaborazione di tutte le righe.
L'operazione di merge join è un'operazione regolare o un'operazione molti-a-molti. Un merge join molti-a-molti utilizza una tabella temporanea per l'archiviazione delle righe. Se sono presenti valori duplicati in entrambi gli input, uno degli input deve tornare all'inizio dei duplicati durante l'elaborazione di ogni duplicato dell'altro input.
Se è presente un predicato residuo, tutte le righe conformi al predicato di merge vengono valutate da tale predicato e vengono restituite soltanto quelle che lo soddisfano.
Il merge join è di per sé un'operazione molto rapida, ma può essere una scelta onerosa se sono necessarie operazioni di ordinamento. Se tuttavia il volume dei dati è elevato ed è possibile ottenere i dati desiderati già ordinati da indici ad albero B esistenti, il merge join risulta spesso l'algoritmo di join più veloce.
Hash join
Gli hash join consentono l'elaborazione efficiente di input di grandi dimensioni, non ordinati e non indicizzati. Tali join sono utili per ottenere risultati intermedi in query complesse, in quanto:
- I risultati intermedi non vengono indicizzati (a meno che non vengano salvati in modo esplicito su disco e quindi indicizzati) e spesso non siano ordinati in modo appropriato per l'operazione successiva nel piano di query.
- Query Optimizer stima esclusivamente le dimensioni dei risultati intermedi. Poiché le stime relative a query complesse possono essere estremamente imprecise, è necessario non solo che gli algoritmi di elaborazione dei risultati intermedi siano efficienti, ma anche che vengano ridotti gradualmente nel caso in cui un risultato intermedio risulti molto più grande del previsto.
Gli hash join consentono di ridurre la denormalizzazione. In genere, la denormalizzazione viene utilizzata per ottenere prestazioni migliori tramite la riduzione delle operazioni di join, nonostante rischi di ridondanza quali aggiornamenti non consistenti. Gli hash join riducono la necessità di utilizzo della denormalizzazione. Gli hash join rendono il partizionamento verticale (la rappresentazione di gruppi di colonne di un'unica tabella in file o indici separati) un'opzione adeguata per la progettazione fisica dei database.
Gli hash join prevedono due tipi di input, ovvero l'input di compilazione e l'input probe. Query Optimizer assegna all'input più piccolo il ruolo di input di compilazione.
Gli hash join vengono utilizzati per vari tipi di operazioni di corrispondenza tra set, ovvero inner join, outer join sinistro, destro e completo, semi-join sinistro e destro, intersezione, unione e differenza. Una variante dell'hash join può anche eseguire la rimozione dei duplicati e il raggruppamento, ad esempio SUM(salary) GROUP BY department. Queste modifiche utilizzano un solo input sia per il ruolo di compilazione che per il ruolo probe.
Nelle sezioni seguenti vengono descritti i diversi tipi di hash join: hash join in memoria, grace hash join e hash join ricorsivo.
Hash join in memoria
L'hash join esegue in primo luogo l'analisi o il calcolo dell'intero input di compilazione, quindi compila una tabella hash in memoria. Ogni riga viene inserita in un hash bucket in base al valore hash calcolato per la chiave hash. Se l'intero input di compilazione è inferiore alla memoria disponibile, tutte le righe possono essere inserite nella tabella hash. A questa fase di compilazione segue la fase probe. Viene eseguita l'analisi o il calcolo dell'intero input probe, una riga alla volta. Per ogni riga probe viene calcolato il valore della chiave hash, viene eseguita l'analisi dell'hash bucket corrispondente e vengono prodotte le corrispondenze.
Grace hash join (tecnica di giunzione dei dati nei database)
Se l'input di compilazione non rientra nella memoria, un hash join procede in diversi passaggi. In questo caso, l'hash join viene definito grace hash join. Ogni passaggio prevede una fase di compilazione e una fase probe. L'input di compilazione e l'input probe vengono inizialmente analizzati e partizionati in più file, tramite una funzione di hashing sulle chiavi hash. L'utilizzo della funzione di hashing sulle chiavi hash garantisce che ogni coppia di record su cui si basa il join si trovi nella stessa coppia di file. In tal modo il join di due input di grandi dimensioni risulta convertito in più istanze di dimensioni ridotte della stessa attività. L'hash join viene quindi applicato a ogni coppia di file partizionati.
Hash join ricorsivo
Se l'input di compilazione ha dimensioni tali per cui gli input per un'unione esterna standard richiedono più livelli di unione, saranno necessari più passaggi di partizionamento e più livelli di partizionamento. Se soltanto alcune partizioni sono di grandi dimensioni, i passaggi di partizionamento aggiuntivi vengono utilizzati soltanto per tali partizioni. Per velocizzare al massimo i passaggi di partizionamento vengono utilizzate operazioni di I/O asincrone di grandi dimensioni, per cui un unico thread può tenere occupate più unità disco.
Note
Se l'input di compilazione non ha dimensioni di molto superiori a quelle della memoria disponibile, gli elementi dell'hash join in memoria e del grace hash join vengono combinati in un unico passaggio, producendo un hash join ibrido.
Non è sempre possibile durante l'ottimizzazione determinare quale hash join viene usato. Pertanto, SQL Server usa inizialmente un hash join in memoria, quindi passa gradualmente a grace hash join e hash join ricorsivo a seconda delle dimensioni dell'input di compilazione.
Se Query Optimizer non prevede correttamente quale dei due input è il più piccolo, al quale quindi deve essere assegnato il ruolo di input di compilazione, i ruoli di input di compilazione e di input probe vengono invertiti dinamicamente. L'hash join utilizza comunque come input di compilazione il file di overflow più piccolo. Questa tecnica è detta inversione dei ruoli. L'inversione dei ruoli si verifica all'interno dell'hash join dopo l'esecuzione di almeno uno spill sul disco.
Note
L'inversione dei ruoli si verifica in maniera indipendente da qualsiasi struttura o hint per la query L'inversione del ruolo non viene visualizzata nel piano di query; quando si verifica, è trasparente per l'utente.
Bailout hash
Il termine hash bailout è talvolta usato per descrivere grace hash join o hash join ricorsivi.
Note
Gli hash join ricorsivi e gli hash bailout causano una riduzione delle prestazioni del server. Se si nota la presenza di molti eventi di avviso di hash in una traccia, aggiornare le statistiche sulle colonne che si sta unendo in join.
Per altre informazioni sugli hash bailout, vedere Hash Warning - classe di evento.
Join adattivi
Modalità batch I join adattivi consentono di rimandare a dopo la scansione del primo input la scelta tra l'esecuzione di un metodo hash join e l'esecuzione di un metodo join a cicli annidati. L'operatore Join adattivo definisce una soglia che viene usata per stabilire quando passare a un piano Cicli annidati. Durante l'esecuzione, un piano di query può pertanto passare a una strategia di join più efficace senza dover essere ricompilato.
Tip
Questa funzionalità è ottimale per i carichi di lavoro con frequenti oscillazioni tra i volumi di input di join rilevati.
La decisione in fase di esecuzione è basata sui passaggi seguenti:
- Se il conteggio delle righe dell'input del join di compilazione è così ridotto che un join a cicli annidati è preferibile a un hash join, il piano passa a un algoritmo a cicli annidati.
- Se l'input del join di compilazione supera una determinata soglia di numero di righe, non si verifica alcun cambiamento e il piano continua con un hash join.
La query seguente illustra un esempio di join adattivo:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
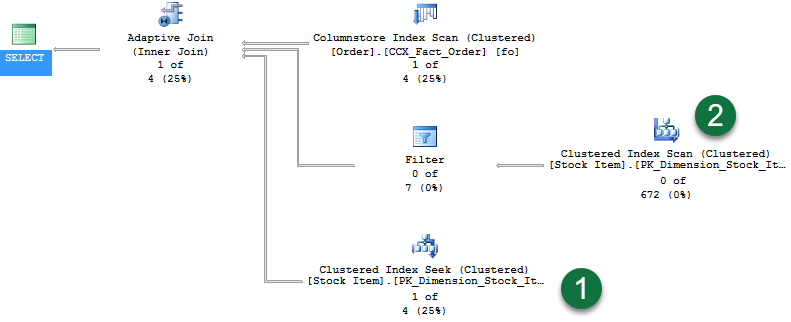
La query restituisce 336 righe. Se si attiva Statistiche query dinamiche, viene visualizzato il piano seguente:

Nel piano notare quanto segue:
- Un'analisi dell'indice columnstore che specifica le righe per la fase di compilazione dell'hash join.
- Il nuovo operatore di join adattivo. L'operatore definisce la soglia usata per il passaggio a un piano Cicli annidati. In questo esempio la soglia corrisponde a 78 righe. Se il risultato è >= 78 righe, verrà usato un hash join. Se è inferiore alla soglia, verrà usato un join a cicli annidati.
- Dato che la query restituisce 336 righe, questa soglia viene superata e pertanto il secondo ramo rappresenta la fase di probe di un'operazione hash join standard. Statistiche query dinamiche visualizza le righe del flusso tra gli operatori, in questo caso "672 di 672".
- L'ultimo ramo è una Ricerca indice cluster che il join a cicli annidati avrebbe usato se la soglia non fosse stata superata. Il valore visualizzato è "0 di 336" righe (il ramo non viene usato).
Confrontare ora il piano con la stessa query, ma in questo caso quando il valore Quantity ha una sola riga nella tabella:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
La query restituisce una riga. Con l'abilitazione di Statistiche query dinamiche viene visualizzato il piano seguente:
Nel piano notare quanto segue:
- Con una sola riga restituita, ora il flusso di righe attraversa Ricerca indice cluster.
- Poiché la fase di compilazione hash join non è continuata, non sono presenti righe che passano attraverso il secondo ramo.
Osservazioni per i join adattivi
I join adattivi presentano requisiti di memoria superiori rispetto a un piano equivalente con join a cicli annidati indicizzati. La memoria aggiuntiva risulta necessaria, come se il join a cicli annidati fosse un hash join. Esiste anche un sovraccarico per la fase di compilazione come operazione stop-and-go rispetto a un join equivalente allo streaming nested Loops. A tale costo aggiuntivo corrisponde una maggior flessibilità per gli scenari in cui i conteggi delle righe variano nell'input di compilazione.
I join adattivi in modalità batch funzionano per l'esecuzione iniziale di un'istruzione. Dopo la compilazione, le esecuzioni consecutive restano adattive sulla base della soglia di join adattivo di compilazione e delle righe di runtime del flusso di dati della fase di compilazione dell'input esterno.
Se un join adattivo passa al funzionamento con cicli annidati usa le righe già lette dalla compilazione hash join. L'operatore non legge di nuovo le righe del riferimento esterno.
Rilevare le attività di join adattivo
L'operatore Join adattivo ha i seguenti attributi dell'operatore del piano:
| Attributo plan | Description |
|---|---|
| AdaptiveThresholdRows | Visualizza l'uso della soglia che determina il passaggio da un hash join a un join a cicli annidati. |
| EstimatedJoinType | Probabile tipo del join. |
| ActualJoinType | In un piano reale visualizza l'algoritmo di join scelto in base alla soglia. |
Il piano stimato visualizza la struttura del piano di join adattivo, la soglia di join adattivo definita e il tipo di join stimato.
Tip
Query Store acquisisce e può imporre un piano di join adattivo in modalità batch.
Istruzioni idonee per i join adattivi
Alcune condizioni rendono un join logico idoneo per un join adattivo in modalità batch:
- Il livello di compatibilità del database è 140 o superiore.
- La query è un'istruzione
SELECT(attualmente le istruzioni di modifica dei dati non sono idonee). - Il join è idoneo per l'esecuzione in un algoritmo fisico di join a cicli annidati indicizzati o di hash join.
- L'hash join usa la modalità batch, abilitata dalla presenza di un indice columnstore nella query globale, una tabella columnstore indicizzata a cui fa riferimento direttamente il join o la modalità batch per rowstore.
- Il primo elemento figlio (riferimento esterno) deve essere identico per le soluzioni alternative generate dal join a cicli annidati e dall'hash join.
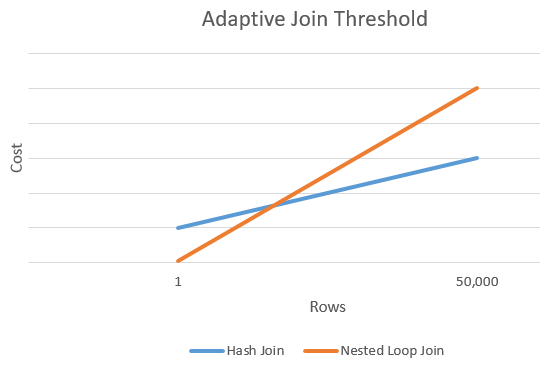
Righe della soglia adattiva
Il grafico seguente visualizza un esempio di intersezione tra il costo di un hash join e il costo di un join a cicli annidati alternativo. In questo punto di intersezione viene determinata la soglia, che a sua volta determina l'algoritmo usato per l'operazione di join.
Disabilitare i join adattivi senza modificare il livello di compatibilità
È possibile disabilitare i join adattivi nell'ambito del database o dell'istruzione mantenendo comunque la compatibilità sul livello 140 o livelli superiori.
Per disabilitare i join adattivi per tutte le esecuzioni di query provenienti dal database, eseguire l'istruzione seguente all'interno del contesto del database applicabile:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
Quando è abilitata, questa impostazione viene visualizzata come abilitata in sys.database_scoped_configurations.
Per abilitare nuovamente i join adattivi per tutte le esecuzioni di query provenienti dal database, eseguire l'istruzione seguente all'interno del contesto del database applicabile:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
È anche possibile disabilitare i join adattivi per una query specifica, definendo DISABLE_BATCH_MODE_ADAPTIVE_JOINS come hint per la query USE HINT. Per esempio:
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Note
Un USE HINT hint per la query ha la precedenza su un'impostazione di configurazione o flag di traccia con ambito database.
Valori Null e join
Quando sono presenti valori Null nelle colonne delle tabelle unite in join, i valori Null non corrispondono tra loro. La presenza di valori Null in una colonna di una delle tabelle da unire in join viene restituita solo se si usa un outer join, a meno che la clausola WHERE non escluda i valori Null.
Le due tabelle riportate di seguito includono entrambe NULL nella colonna interessata dal join:
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
Un join che confronta i valori nella colonna con la colonna ac non ottiene una corrispondenza nelle colonne con valori di NULL:
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Viene restituita una sola riga con valore 4 nelle colonne a e c:
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
I valori Null restituiti da una tabella di base non sono inoltre facilmente distinguibili dai valori Null restituiti da un outer join. L'istruzione SELECT seguente, ad esempio, esegue un left outer join sull due tabelle seguenti:
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Il set di risultati è il seguente.
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
I risultati non semplificano la distinzione tra i NULL dati di un NULL oggetto che rappresenta un errore di join. Quando NULL i valori sono presenti nei dati aggiunti, è in genere preferibile ometterli dai risultati usando un join normale.