Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server
SQL Server![]() Istanza gestita di Azure SQL
Istanza gestita di Azure SQL
L'I/O di un'istanza del motore di database di SQL Server include letture logiche e fisiche. Una lettura logica viene eseguita ogni volta che il motore di database richiede una pagina dalla cache del buffer, nota anche come pool di buffer. Se la pagina non è attualmente presente nella cache del buffer, una lettura fisica copia prima la pagina dal disco nella cache.
Le richieste di lettura generate da un'istanza del motore di database sono controllate dal motore relazionale e ottimizzate dal motore di archiviazione. Il motore relazionale determina il metodo di accesso più efficace, ad esempio un'analisi di tabella, un'analisi dell'indice o una lettura con chiave. I metodi di accesso e i componenti di gestione buffer del motore di archiviazione determinano il modello generale di letture da eseguire e ottimizzano le letture necessarie per implementare il metodo di accesso. Il thread che esegue il batch pianifica le operazioni di lettura.
Pre-lettura
Il motore di database supporta un meccanismo di ottimizzazione delle prestazioni detto read-ahead. Read-ahead prevede le pagine di dati e indici necessarie per soddisfare un piano di esecuzione delle query e inserisce le pagine nella cache del buffer prima che vengano usate dalla query. Questo processo consente il calcolo e l'I/O di sovrapporsi, sfruttando appieno sia la CPU che il disco.
Il meccanismo read-ahead consente al motore di database di leggere fino a 64 pagine contigue (512 KB) da un file. La lettura viene eseguita come lettura a dispersione singola per il numero appropriato di buffer (probabilmente non contigui) nella cache del buffer. Se una delle pagine dell'intervallo è già presente nella cache del buffer, la pagina corrispondente dalla lettura viene rimossa al termine della lettura. L'intervallo di pagine potrebbe anche essere "tagliato" da entrambe le estremità se le pagine corrispondenti sono già presenti nella cache.
Esistono due tipi di read-ahead: uno per le pagine di dati e uno per le pagine di indice.
Leggere le pagine di dati
Le analisi delle tabelle utilizzate dal motore di database per leggere le pagine di dati sono efficienti. Nelle pagine IAM (Index Allocation Map, mappa di allocazione degli indici) di un database di SQL Server vengono elencati gli extent usati da una tabella o da un indice. Il motore di archiviazione può leggere la pagina IAM per compilare un elenco ordinato degli indirizzi di disco che è necessario leggere. Questo consente al motore di archiviazione di ottimizzare le operazioni di I/O come se si trattasse di letture sequenziali di grandi dimensioni eseguite in sequenza, in base alla relativa posizione nel disco. Per altre informazioni sulle pagine IAM, vedere Gestire lo spazio usato dagli oggetti.
Leggere le pagine di indice
Il motore di archiviazione legge le pagine di indice in modo seriale, in base all'ordine delle chiavi. Nella figura seguente è ad esempio illustrata una rappresentazione semplificata di un set di pagine foglia contenente un set di chiavi e il nodo di indice intermedio che esegue il mapping delle pagine foglia. Per ulteriori informazioni sulla struttura delle pagine in un indice, consultare Indici clusterizzati e non clusterizzati.
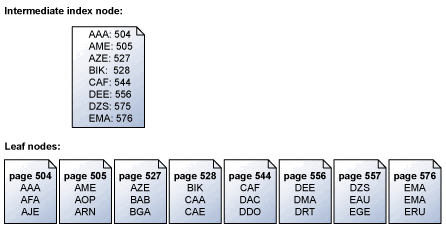
Il motore di archiviazione utilizza le informazioni della pagina di indice intermedio sopra il livello delle foglie per pianificare letture seriali in anticipo per le pagine che contengono le chiavi. Se viene effettuata una richiesta per tutte le chiavi da ABC a DEF, il motore di archiviazione legge prima la pagina di indice sopra la pagina foglia. Tuttavia, non legge solo ogni pagina di dati in sequenza dalla pagina 504 alla pagina 556 (l'ultima pagina con chiavi nell'intervallo specificato). Al contrario, il motore di archiviazione esegue l'analisi della pagina di indice intermedio e compila un elenco delle pagine foglia che devono essere lette. Il motore di archiviazione pianifica quindi tutte le letture in base all'ordine delle chiavi. Il motore di archiviazione riconosce inoltre che le pagine 504/505 e 527/528 sono contigue ed esegue una singola lettura sequenziale per recuperare le pagine adiacenti in una sola operazione. Se in un'operazione seriale è necessario recuperare molte pagine, il motore di archiviazione pianifica un blocco di letture per volta. Quando viene completato un subset di queste letture, il motore di archiviazione pianifica un numero uguale di nuove letture fino a quando non vengono pianificate tutte le letture necessarie.
Il motore di archiviazione usa la prelettura per velocizzare le ricerche di tabelle di base da indici non cluster. Le righe foglia di un indice non clusterizzato contengono puntatori alle righe di dati che includono ogni specifico valore di chiave. Mentre il motore di archiviazione legge le pagine foglia dell'indice non clusterizzato, inizia anche a programmare letture asincrone per le righe di dati i cui puntatori sono già stati recuperati. Ciò consente al motore di archiviazione di recuperare le righe di dati dalla tabella sottostante prima di completare l'analisi dell'indice non cluster. La prelettura viene utilizzata indipendentemente dal fatto che alla tabella sia associato o meno un indice clusterizzato. SQL Server Enterprise Edition usa più prelettura rispetto ad altre edizioni di SQL Server, consentendo la lettura di più pagine. Il livello di prelettura non è configurabile su alcuna edizione. Per ulteriori informazioni sugli indici nonclustered, vedere indici clustered e nonclustered.
Analisi avanzata
In SQL Server Enterprise Edition la funzionalità di analisi avanzata consente a più attività di condividere analisi di tabelle complete. Se in base al piano di esecuzione di un'istruzione Transact-SQL è necessaria l'analisi delle pagine di dati di una tabella e il motore di database rileva che tale tabella è già sottoposta ad analisi da un altro piano di esecuzione, il motore di database unisce la seconda analisi alla prima nella posizione corrente della seconda analisi. Il motore di database legge ogni pagina una sola volta e passa le righe di ognuna a entrambi i piani di esecuzione. Questa procedura continua fino a quando viene raggiunta la fine della tabella.
A questo punto, il primo piano di esecuzione ha i risultati completi di un'analisi. Tuttavia, il secondo piano di esecuzione deve comunque recuperare le pagine di dati lette, prima di unirsi alla scansione in corso. L'analisi del secondo piano di esecuzione riprende quindi dalla prima pagina di dati della tabella e termina in corrispondenza della posizione a partire dalla quale si è unita alla prima analisi. È possibile combinare in questo modo un numero qualsiasi di scansioni. Il motore di database continua a scorrere le pagine di dati fino a quando non completa tutte le analisi. Questo meccanismo è detto anche "merry-go-round scanning" e dimostra il motivo per cui l'ordine dei risultati restituiti da un'istruzione SELECT non può essere garantito senza una ORDER BY clausola .
Si supponga, ad esempio, che sia disponibile una tabella con 500.000 pagine.
UserA esegue un'istruzione Transact-SQL che richiede un'analisi della tabella. Quando l'analisi ha elaborato 100.000 pagine, UserB esegue un'altra istruzione Transact-SQL che analizza la stessa tabella. Il motore di database pianifica un set di richieste di lettura per le pagine dopo la 100.001 e passa le righe di ogni pagina a entrambe le scansioni. Quando l'analisi raggiunge la pagina 200.000, UserC esegue un'altra istruzione Transact-SQL che analizza la stessa tabella. A partire dalla pagina 200.001, il motore di database passa a tutte e tre le scansioni le righe di ogni pagina che legge. Dopo aver letto la riga 500.000, l'analisi per UserA è stata completata e le analisi per UserB e UserC tornano indietro e iniziano a leggere le pagine a partire dalla pagina 1. Quando il motore di database raggiunge la pagina 100.000, la scansione per UserB è completata. L'analisi per UserC continua da sola fino a leggere la pagina 200.000. A questo punto tutte le analisi risultano completate.
Senza una scansione avanzata, ogni utente dovrebbe competere per lo spazio nel buffer e causare contese sul braccio del disco. Le stesse pagine verrebbero inoltre lette una volta per ogni utente, anziché essere lette una sola volta e condivise tra più utenti, provocando un peggioramento delle prestazioni e un sovraccarico delle risorse.