Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server
SQL Server
In genere la replica di tipo merge, come la replica transazionale, inizia con uno snapshot degli oggetti e dei dati del database di pubblicazione. Eventuali modifiche dei dati e dello schema apportate successivamente nel server di pubblicazione e nei Sottoscrittori vengono rilevate tramite trigger. Al momento della connessione alla rete il Sottoscrittore esegue la sincronizzazione con il server di pubblicazione e scambia con esso le righe modificate dopo l'ultima sincronizzazione.
In genere la replica di tipo merge è utilizzata in ambienti server-to-client. La replica di tipo merge è adatta alle seguenti situazioni:
Più Sottoscrittori potrebbero richiedere l'aggiornamento dei dati in ore diverse e la distribuzione delle modifiche al server di pubblicazione e ad altri Sottoscrittori.
I Sottoscrittori devono ricevere i dati, eseguire le modifiche offline e sincronizzarle successivamente con il server di pubblicazione e i Sottoscrittori.
Per ogni Sottoscrittore è necessaria una diversa partizione di dati.
È necessario essere in grado di individuare e risolvere tempestivamente eventuali conflitti che potrebbero verificarsi.
È necessario lo scambio di dati net piuttosto che l'accesso a stati di dati intermedi. Ad esempio, se una riga viene modificata cinque volte nel Sottoscrittore prima della sincronizzazione con un server di pubblicazione, la riga verrà modificata solo una volta nel server di pubblicazione per riflettere la modifica dei dati net, ovvero il quinto valore.
La replica di tipo merge consente a vari siti di eseguire elaborazioni in modo autonomo e di unire quindi gli aggiornamenti in un unico risultato uniforme. Poiché gli aggiornamenti vengono eseguiti in più nodi, gli stessi dati potrebbero essere stati aggiornati dal server di pubblicazione e da più sottoscrittori. Pertanto, i conflitti possono verificarsi quando gli aggiornamenti vengono uniti e la replica di tipo merge offre diversi modi per gestire i conflitti.
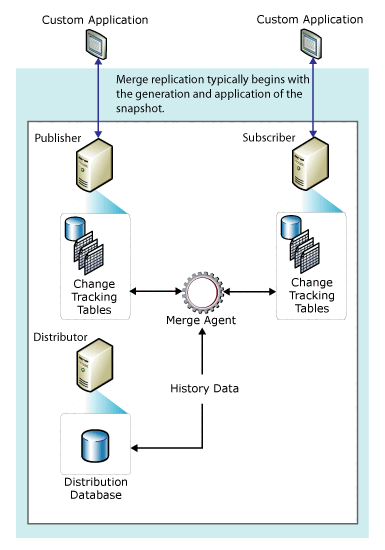
La replica di tipo merge viene implementata dall'agente snapshot e dall'agente di merge di SQL Server. Se la pubblicazione non è filtrata o utilizza filtri statici, l'agente snapshot crea un singolo snapshot. Se la pubblicazione utilizza filtri con parametri, l'agente snapshot crea uno snapshot per ogni partizione di dati. L'agente di merge applica gli snapshot iniziali ai Sottoscrittori e unisce le modifiche ai dati incrementali apportate nel server di pubblicazione o nei Sottoscrittori dopo la creazione dello snapshot iniziale, quindi rileva e risolve eventuali conflitti in base alle regole configurate.
Per tener traccia delle modifiche, tramite la replica di tipo merge e la replica transazionale con sottoscrizioni ad aggiornamento in coda deve essere possibile identificare in modo univoco ogni riga di ogni tabella pubblicata. Per eseguire questa replica di tipo merge, la colonna rowguid viene aggiunta a ogni tabella, a meno che la tabella non disponga già di una colonna di tipo di dati uniqueidentifier con il ROWGUIDCOL set di proprietà , nel qual caso viene usata questa colonna. Se la tabella viene eliminata dalla pubblicazione, la rowguid colonna viene rimossa. Se per il rilevamento è stata utilizzata una colonna esistente, la colonna non viene rimossa. In un filtro non deve essere inclusa la colonna rowguidcol utilizzata dalla replica per identificare le righe. La funzione newid() viene fornita come predefinita per la rowguid colonna, ma i clienti possono fornire un GUID per ogni riga, se necessario. Tuttavia, non fornire il valore 00000000-0000-0000-0000-000000000000.
Nella figura seguente vengono illustrati i componenti utilizzati nella replica di tipo merge.
Configurare la crittografia TLS 1.3
SQL Server 2025 (17.x) introduce il supporto TDS 8.0 per la replica di tipo merge, che include:
- Configurazione degli agenti di replica per l'uso della crittografia TLS 1.3 tra istanze di SQL Server 2025 (17.x) e anche tra SQL Server 2025 (17.x) e Istanza gestita di SQL di Azure.
- Crittografia predefinita per la comunicazione tra server collegati tra istanze di SQL Server 2025 (17.x) in una topologia di replica. I server collegati in SQL Server 2025 (17.x) utilizzano il driver OLE DB v19, che per impostazione predefinita utilizza la crittografia
Encrypt=Mandatory.
Annotazioni
Per le topologie di replica con un server di distribuzione remoto:
In questa sezione
- Come la replica di tipo merge inizializza pubblicazioni e sottoscrizioni
- Come la replica di tipo merge tiene traccia ed enumera le modifiche
- Come la replica di tipo merge valuta le partizioni nelle pubblicazioni filtrate
- Come la replica di tipo merge rileva e risolve i conflitti
- Esempio di risoluzione dei conflitti di merge in base al tipo di sottoscrizione e alle priorità assegnate
- Come la replica di tipo merge gestisce la scadenza della sottoscrizione e la pulizia dei metadati