Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server
SQL Server![]() Database SQL di Azure
Database SQL di Azure![]() Istanza gestita di Azure SQL
Istanza gestita di Azure SQL![]() Database SQL in Microsoft Fabric
Database SQL in Microsoft Fabric
La progettazione di indici efficienti è fondamentale per ottenere prestazioni ottimali del database e dell'applicazione. La mancanza di indici, l'over-indexing o gli indici progettati in modo non appropriato sono le principali fonti di problemi di prestazioni del database.
Questa guida descrive l'architettura e i concetti fondamentali dell'indice e fornisce procedure consigliate che consentono di progettare indici efficaci per soddisfare le esigenze delle applicazioni.
Per altre informazioni sui tipi di indice disponibili, vedere Indici.
In questa guida vengono illustrati i tipi di indici seguenti:
| Formato di archiviazione principale | Tipo di indice |
|---|---|
| Rowstore basato su disco | |
| Clustered | |
| Nonclustered | |
| Unique | |
| Filtered | |
| Columnstore | |
| Columnstore clusterizzato | |
| Columnstore non cluster | |
| Memory-optimized | |
| Hash | |
| Indici non clusterizzati ottimizzati per la memoria |
Per informazioni sugli indici XML, vedere Indici XML (server SQL) e Indici XML selettivi (SXI).
Per informazioni sugli indici spaziali, vedere Panoramica degli indici spaziali.
Per informazioni sugli indici full-text, vedere Popolare indici full-text.
Nozioni di base sugli indici
Si pensi a un libro: alla fine del libro è disponibile un indice che consente di trovare rapidamente le informazioni all'interno del libro. L'indice è un elenco ordinato di parole chiave e a ogni parola chiave segue un gruppo di numeri di pagina, che riporta alle pagine in cui è possibile trovare ciascuna parola chiave.
Un indice rowstore è simile: si tratta di un elenco ordinato di valori e per ogni valore sono presenti puntatori alle pagine dati in cui si trovano questi valori. L'indice stesso viene archiviato anche nelle pagine, denominate pagine di indice. In un normale libro, se l'indice si estende su più pagine ed è necessario trovare puntatori a tutte le pagine che contengono la parola, ad esempio, è necessario sfogliare dall'inizio dell'indice fino a quando non si individua la pagina di indice contenente la parola SQL chiave SQL. Quindi si seguono i puntatori che rimandano a tutte le pagine del libro. Questa operazione può essere ulteriormente ottimizzata se all'inizio dell'indice si crea una singola pagina contenente un elenco alfabetico indicante dove è possibile trovare ogni lettera. Ad esempio: "Da A a D - pagina 121", "Da E a G - pagina 122" e così via. Questa pagina extra eliminerà il passaggio di consultazione dell'intero indice per trovare il punto di partenza. Questa pagina non esiste nei libri normali, ma esiste in un indice rowstore. Questa pagina singola viene definita pagina radice dell'indice. La pagina radice è la pagina iniziale della struttura ad albero usata da un indice. Per continuare con l'esempio dell'albero, le pagine finali contenenti puntatori ai dati effettivi sono definite "pagine foglia" dell'albero.
Un indice è una struttura su disco o memoria associata a una tabella o a una vista che consente di recuperare in modo rapido le righe della tabella o della vista. Un indice rowstore contiene chiavi derivanti dai valori presenti in una o più colonne della tabella o della vista. Per gli indici rowstore, queste chiavi vengono archiviate in una struttura ad albero (albero B+) che consente al motore di database di trovare le righe associate ai valori chiave in modo rapido ed efficiente.
Un indice rowstore archivia i dati organizzati logicamente come tabella con righe e colonne e archiviati fisicamente in un formato di dati row-wise denominato rowstore1. Esiste un modo alternativo per archiviare le colonne di dati, denominate columnstore.
La progettazione degli indici corretti per un database e il relativo carico di lavoro è un'operazione complessa di bilanciamento tra velocità delle query, costi di aggiornamento degli indici e costi di archiviazione. Gli indici rowstore basati su disco ristretti o gli indici con poche colonne nella chiave di indice richiedono meno spazio di archiviazione e un sovraccarico di aggiornamento inferiore. Gli indici larghi, invece, potrebbero migliorare più query. Potrebbe essere necessario sperimentare diverse progettazioni prima di trovare il set di indici più efficiente. Man mano che l'applicazione si evolve, gli indici potrebbero dover modificare per mantenere prestazioni ottimali. Gli indici possono essere aggiunti, modificati e rimossi senza influire sullo schema del database o sulla progettazione dell'applicazione. È pertanto opportuno sperimentare il funzionamento di vari tipi di indice.
Query Optimizer nel motore di database sceglie in genere gli indici più efficaci per eseguire una query. Per visualizzare gli indici usati da Query Optimizer per una query specifica, in SQL Server Management Studio scegliere Visualizza piano di esecuzione stimato o Includi piano di esecuzione effettivo nel menu Query.
L'utilizzo di indici non consente necessariamente di ottenere prestazioni ottimali e prestazioni ottimali non sempre sono da mettere in relazione all'utilizzo di indici. Se l'utilizzo di un indice garantisse sempre le prestazioni migliori, il processo di Query Optimizer risulterebbe semplice. In realtà, una scelta non corretta di un indice può portare a prestazioni per niente ottimali. Di conseguenza, l'attività di Query Optimizer consiste nel selezionare un indice o una combinazione di indici, solo quando migliora le prestazioni ed evitare il recupero indicizzato quando ostacola le prestazioni.
Un errore di progettazione comune consiste nel creare molti indici speculativamente per "dare le scelte di Optimizer". L'overindexing risultante rallenta le modifiche ai dati e può causare problemi di concorrenza.
1 Il formato rowstore è il metodo di archiviazione tradizionale per i dati relazionali di tabella. Rowstore fa riferimento a una tabella in cui il formato di archiviazione dati sottostante è un heap, un albero B+ (indice cluster) o una tabella ottimizzata per la memoria. Rowstore basato su disco esclude le tabelle ottimizzate per la memoria.
Attività di progettazione di indici
Le attività seguenti costituiscono la strategia consigliata per la progettazione di indici:
Comprendere le caratteristiche del database e dell'applicazione.
Ad esempio, in un database OLTP (Online Transaction Processing) con frequenti modifiche ai dati che devono sostenere una velocità effettiva elevata, alcuni indici rowstore ristretti destinati alle query più critiche sarebbero una progettazione di indice iniziale ottimale. Per prestazioni estremamente elevate, prendere in considerazione tabelle e indici ottimizzati per la memoria, che offrono un design privo di blocchi e latch. Per altre informazioni, vedere Linee guida per la progettazione di indici non cluster ottimizzati per la memoria e Linee guida per la progettazione degli indici hash in questa guida.
Viceversa, per un database di analisi o data warehousing (OLAP) che deve elaborare rapidamente set di dati di grandi dimensioni, l'uso di indici columnstore cluster sarebbe particolarmente appropriato. Per altre informazioni, vedere Indici columnstore: panoramica o architettura dell'indice Columnstore in questa guida.
Comprendere le caratteristiche delle query usate più di frequente.
Ad esempio, sapendo che una query usata di frequente unisce due o più tabelle consente di determinare il set di indici per queste tabelle.
Comprendere la distribuzione dei dati nelle colonne usate nei predicati di query.
Ad esempio, un indice può essere utile per le colonne con molti valori di dati distinti, ma meno per le colonne con molti valori duplicati. Per le colonne con molti valori NULL o con subset ben definiti di dati, è possibile usare un indice filtrato. Per ulteriori informazioni, vedere Linee guida per la progettazione di indici filtrati in questa guida.
Determinare quali opzioni di indice possono migliorare le prestazioni.
Ad esempio, la creazione di un indice clusterizzato su una tabella grande esistente può trarre vantaggio dall'opzione di indice
ONLINE. L'opzioneONLINEconsente l'esecuzione di attività simultanee sui dati sottostanti durante la creazione o la ricompilazione dell'indice. L'uso della compressione dei dati di riga o di pagina può migliorare le prestazioni riducendo il footprint di I/O e memoria dell'indice. Per altre informazioni, vedere CREATE INDEX.Esaminare gli indici esistenti nella tabella per impedire la creazione di indici duplicati o molto simili.
Spesso è preferibile modificare un indice esistente rispetto a creare un indice nuovo ma principalmente duplicato. Si consideri ad esempio l'aggiunta di una o due colonne incluse aggiuntive a un indice esistente, anziché creare un nuovo indice con queste colonne. Ciò è particolarmente rilevante quando si ottimizzano gli indici non clusterizzati con suggerimenti per indici mancanti o se si usa il Consulente per l'ottimizzazione del motore di database, dove potrebbero essere offerte variazioni simili di indici sulla stessa tabella e sulle stesse colonne.
Linee guida generali per la progettazione di indici
Comprendere le caratteristiche del database, delle query e delle colonne di tabella consente di progettare indici ottimali inizialmente e di modificare la progettazione man mano che le applicazioni si evolvono.
Considerazioni sul database
Quando si progetta un indice è consigliabile attenersi alle linee guida seguenti sui database:
Un numero elevato di indici in una tabella influisce sulle prestazioni delle
INSERTistruzioni,UPDATE,DELETEeMERGEperché i dati negli indici potrebbero dover cambiare al variare dei dati nella tabella. Ad esempio, se una colonna viene usata in più indici ed è stata eseguita un'istruzioneUPDATEche modifica i dati della colonna, ogni indice che contiene tale colonna deve essere aggiornato.Evitare di creare un numero eccessivo di indici in tabelle che vengono aggiornate spesso e mantenere indici di piccole dimensioni, vale a dire con il minor numero possibile di colonne.
È possibile avere più indici nelle tabelle con poche modifiche ai dati, ma volumi elevati di dati. Per tali tabelle, un'ampia gamma di indici può aiutare le prestazioni delle query mentre l'overhead di aggiornamento dell'indice rimane accettabile. Tuttavia, non creare indici speculativi. Monitorare l'utilizzo degli indici e rimuovere gli indici inutilizzati nel tempo.
L'indicizzazione di tabelle di piccole dimensioni potrebbe non essere ottimale perché il motore di database può richiedere più tempo per attraversare l'indice alla ricerca di dati che per eseguire un'analisi della tabella di base. Pertanto, gli indici in tabelle di piccole dimensioni potrebbero non essere mai usati, ma devono comunque essere aggiornati man mano che i dati nella tabella vengono aggiornati.
Gli indici nelle viste possono offrire miglioramenti significativi delle prestazioni quando la vista contiene aggregazioni e/o join. Per altre informazioni, vedere Creare viste indicizzate.
I database nelle repliche primarie di database SQL di Azure generano automaticamente raccomandazioni sulle prestazioni di Database Advisor per gli indici. Facoltativamente è possibile abilitare l'ottimizzazione automatica degli indici.
Query Store consente di identificare le query con prestazioni non ottimali e fornisce una cronologia dei piani di esecuzione delle query che consentono di visualizzare gli indici selezionati dall'ottimizzatore. È possibile usare questi dati per apportare le modifiche di ottimizzazione dell'indice in modo più significativo concentrandosi sulle query più frequenti e di consumo di risorse.
Considerazioni sulle query
Quando si progetta un indice è consigliabile attenersi alle linee guida seguenti sulle query:
Creare indici non clusterizzati nelle colonne frequentemente usate nei predicati e nelle espressioni di join nelle query. Queste sono le colonne SARGable. Tuttavia, è consigliabile evitare di aggiungere colonne non necessarie agli indici. L'aggiunta di troppe colonne di indice può influire negativamente sullo spazio su disco e sulle prestazioni di aggiornamento dell'indice.
Il termine SARGable nei database relazionali si riferisce a un predicato Search ARGumentable che può usare un indice per velocizzare l'esecuzione della query. Per altre informazioni, vedere Guida all'architettura e alla progettazione degli indici di SQL Server e Azure SQL.
Tip
Assicurarsi sempre che gli indici creati vengano effettivamente usati dal carico di lavoro della query. Eliminare gli indici inutilizzati.
Le statistiche di utilizzo degli indici sono disponibili in sys.dm_db_index_usage_stats e sys.dm_db_index_operational_stats.
Gli indici di copertura possono migliorare le prestazioni delle query, perché tutti i dati necessari per soddisfare i requisiti della query esistono all'interno dell'indice stesso. In altre parole, per recuperare i dati richiesti sono necessarie solo le pagine di indice, e non le pagine di dati della tabella o dell'indice cluster. Viene dunque ridotto l'I/O complessivo del disco. Ad esempio, una query di colonne
AeBsu una tabella con un indice composto creato nelle colonneA,BeCpuò recuperare i dati specificati dall'indice solo.Note
Un indice di copertura è un indice non cluster che soddisfa tutti gli accessi ai dati direttamente da una query senza accedere alla tabella di base.
Tali indici hanno tutte le colonne SARGable necessarie nella chiave di indice e colonne non SARGable come colonne incluse . Ciò significa che tutte le colonne necessarie per la query, nelle clausole
WHERE,JOINeGROUP BY, o nelle clausoleSELECToUPDATE, sono presenti nell'indice.L'I/O è potenzialmente molto inferiore per eseguire la query, se l'indice è sufficientemente ristretto rispetto alle righe e alle colonne della tabella stessa, ovvero è un piccolo subset di tutte le colonne.
Prendere in considerazione la copertura degli indici durante il recupero di una piccola parte di una tabella di grandi dimensioni, e dove tale piccola parte è determinata da un predicato fisso.
Evitare di creare un indice coprente con troppe colonne, poiché questo ne riduce i benefici, aumentando la memoria di archiviazione del database, l'I/O e l'occupazione di memoria.
Scrivere query che inseriscono o modificano il numero più alto possibile di righe con una sola istruzione, anziché utilizzare più query per aggiornare le stesse righe. In questo modo si riduce il sovraccarico di aggiornamento dell'indice.
Considerazioni sulle colonne
Quando si progetta un indice, considerare le seguenti linee guida per le colonne:
Mantenere breve la lunghezza della chiave di indice, in particolare per gli indici cluster.
Le colonne dei tipi di dati ntext, text, image, varchar(max), nvarchar(max), varbinary(max), json e vector non possono essere specificate come colonne chiave dell'indice. Tuttavia, le colonne con questi tipi di dati possono essere aggiunte a un indice non cluster come colonne di indice non chiave (incluse). Per altre informazioni, vedere la sezione Usare colonne incluse in indici non cluster in questa guida.
Esamina l'unicità della colonna. Un indice univoco anziché un indice non univoco nelle stesse colonne chiave fornisce informazioni aggiuntive per Query Optimizer che rende l'indice più utile. Per ulteriori informazioni, vedere Linee guida per la progettazione di indici univoci in questa guida.
Esaminare la distribuzione dei dati nella colonna. La creazione di un indice in una colonna con molte righe ma pochi valori distinti potrebbe non migliorare le prestazioni delle query anche se l'indice viene usato da Query Optimizer. Come analogia, un elenco telefonico fisico ordinato alfabeticamente in base al cognome non facilita la ricerca di una persona se tutte le persone in città si chiamano Smith o Jones. Per altre informazioni sulla distribuzione dei dati, vedere Statistiche.
È consigliabile usare indici filtrati in colonne con subset ben definiti, ad esempio colonne con molti valori NULL, colonne con categorie di valori e colonne con intervalli distinti di valori. Un indice filtrato ben progettato può migliorare le prestazioni delle query, ridurre i costi di aggiornamento degli indici e ridurre i costi di archiviazione archiviando un piccolo subset di tutte le righe della tabella, se tale subset è rilevante per molte query.
Prendere in considerazione l'ordine delle colonne chiave di indice se la chiave contiene più colonne. La colonna utilizzata nel predicato di query in un'uguaglianza (
=), una disuguaglianza (>,>=,<,<=) o un'espressioneBETWEEN, o che partecipa a un join, deve essere inserita per prima. Le colonne aggiuntive devono essere ordinate in base al loro livello di distintività, vale a dire dalla più distinta alla meno distinta.Ad esempio, se l'indice è definito come
LastName,FirstName, l'indice è utile quando il predicato diWHEREquery nella clausola èWHERE LastName = 'Smith'oWHERE LastName = Smith AND FirstName LIKE 'J%'. Tuttavia, Query Optimizer non usa l'indice per una query in cui è stata eseguita la ricerca solo inWHERE FirstName = 'Jane'o l'indice non migliorerebbe le prestazioni di una query di questo tipo.Valutare la possibilità di indicizzare le colonne calcolate se sono incluse nei predicati di query. Per altre informazioni, vedere Indici per le colonne calcolate.
Caratteristiche dell'indice
Dopo avere stabilito che un indice è adeguato a una query, è possibile scegliere il tipo di indice più adatto alla situazione. Le caratteristiche dell'indice includono:
- Clusterizzato o non clusterizzato
- Univoco o non univoco
- Colonna singola o multicolonna
- Ordine crescente o decrescente per le colonne chiave nell'indice
- Tutte le righe o righe filtrate, per indici non clusterizzati
- Columnstore o rowstore
- Hash o nonclusterizzato per tabelle ottimizzate per la memoria
Posizione degli indici nei filegroup o negli schemi di partizioni
Durante lo sviluppo della strategia di progettazione degli indici, è opportuno considerare la posizione degli indici nei filegroup associati al database.
Per impostazione predefinita, gli indici vengono archiviati nello stesso filegroup della tabella di base (indice cluster o heap) in cui viene creato l'indice. Sono possibili altre configurazioni, tra cui:
Creare indici non cluster in un filegroup diverso dal filegroup della tabella di base.
Partizionare indici cluster e non cluster tra più filegroup.
Per le tabelle non partizionate, l'approccio più semplice è in genere il migliore: creare tutte le tabelle nello stesso filegroup e aggiungere il numero di file di dati al filegroup necessario per usare tutte le risorse di archiviazione fisiche disponibili.
È possibile considerare approcci di posizionamento degli indici più avanzati quando è disponibile l'archiviazione a livelli. Ad esempio, è possibile creare un filegroup per tabelle a cui si accede di frequente con file su dischi più veloci e un filegroup per le tabelle di archiviazione su dischi più lenti.
È possibile spostare una tabella con un indice cluster da un filegroup a un altro eliminando l'indice cluster e specificando un nuovo filegroup o schema di partizione nella MOVE TO clausola dell'istruzione DROP INDEX o usando l'istruzione CREATE INDEX con la DROP_EXISTING clausola .
Indici partizionati
È anche possibile prendere in considerazione il partizionamento di heap basati su disco, indici clusterizzati e non clusterizzati su più gruppi di file. Gli indici partizionati vengono partizionati orizzontalmente (per riga), in base a una funzione di partizione. La funzione di partizione definisce la modalità di mapping di ogni riga a una partizione in base ai valori di una determinata colonna designata, denominata colonna di partizionamento. Uno schema di partizionamento specifica la mappatura di un set di partizioni a un filegroup.
Il partizionamento di un indice può offrire i vantaggi seguenti:
Rendere più gestibili i database di grandi dimensioni. I sistemi OLAP, ad esempio, possono implementare ETL con riconoscimento della partizione che semplifica notevolmente l'aggiunta e la rimozione di dati in blocco.
Rendere più veloci alcuni tipi di query, ad esempio le query a esecuzione prolungata e analitiche. Quando le query usano un indice partizionato, il motore di database può elaborare più partizioni contemporaneamente e ignorare (eliminare) partizioni non necessarie per la query.
Avvertimento
Il partizionamento migliora raramente le prestazioni delle query nei sistemi OLTP, ma può comportare un sovraccarico significativo se una query transazionale deve accedere a molte partizioni.
Per ulteriori informazioni, vedere Tabelle e indici partizionati.
Linee guida per la progettazione dell'ordinamento dell'indice
Quando si definiscono gli indici, valutare se ogni colonna chiave di indice deve essere archiviata in ordine crescente o decrescente. L'ordine crescente è l'impostazione predefinita. La sintassi delle istruzioni CREATE INDEX, CREATE TABLE e ALTER TABLE supporta le parole chiave ASC (crescente) e DESC (decrescente) per singole colonne di indici e vincoli.
È utile specificare l'ordine di archiviazione dei valori chiave in un indice nel caso in cui le query che fanno riferimento alla tabella includono clausole ORDER BY che specificano direzioni diverse per la colonna o le colonne chiave nell'indice. In questi casi, l'indice può rimuovere la necessità di un operatoreSort nel piano di query.
Gli acquirenti nel reparto acquisti di Adventure Works Cycles, ad esempio, devono valutare la qualità dei prodotti acquistati dai fornitori. Gli acquirenti sono più interessati a trovare i prodotti inviati dai fornitori con un tasso di rifiuto elevato.
Come illustrato nella query seguente rispetto al database di esempio AdventureWorks, per recuperare i dati che soddisfano questo criterio è necessario che la colonna RejectedQty della tabella Purchasing.PurchaseOrderDetail sia disposta in ordine decrescente, ovvero dal valore più grande al più piccolo, e che la colonna ProductID sia disposta in ordine crescente, ovvero dal valore più piccolo al più grande.
SELECT RejectedQty,
((RejectedQty / OrderQty) * 100) AS RejectionRate,
ProductID,
DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
Il piano di esecuzione seguente per questa query mostra che Query Optimizer ha usato un operatore Sort per restituire il set di risultati nell'ordine specificato dalla ORDER BY clausola .

Se viene creato un indice rowstore basato su disco con colonne chiave corrispondenti a quelle ORDER BY nella clausola nella query, l'operatore Sort nel piano di query viene eliminato, rendendo più efficiente il piano di query.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
Dopo che la query è stata eseguita di nuovo, il piano di esecuzione seguente mostra che l'operatore Sort non è più presente e viene usato l'indice non clusterizzato appena creato.
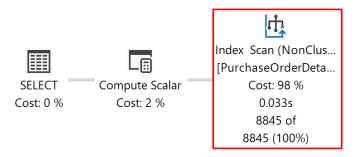
Il motore di database può analizzare un indice in entrambe le direzioni. Un indice definito come RejectedQty DESC, ProductID ASC può comunque essere usato per una query in cui le direzioni di ordinamento delle colonne nella ORDER BY clausola vengono invertite. Ad esempio, una query con la ORDER BY clausola ORDER BY RejectedQty ASC, ProductID DESC può usare lo stesso indice.
È possibile specificare l'ordinamento solo per le colonne chiave nell'indice. La vista del catalogo sys.index_columns indica se una colonna di indice è archiviata in ordine crescente o decrescente.
linee guida per la progettazione di indici cluster
L'indice cluster archivia tutte le righe e tutte le colonne di una tabella. Le righe vengono ordinate nell'ordine dei valori della chiave di indice. Può essere presente un solo indice cluster per ogni tabella.
Il termine tabella di base può fare riferimento a un indice cluster o a un heap. Un heap è una struttura di dati non interrotta su disco che contiene tutte le righe e tutte le colonne di una tabella.
Con alcune eccezioni, ogni tabella deve avere un indice cluster. Le proprietà desiderate dell'indice cluster sono:
| Proprietà | Description |
|---|---|
| Stretto | La chiave di indice cluster fa parte di qualsiasi indice non clusterizzato nella stessa tabella di base. Una chiave stretta o una chiave in cui la lunghezza totale delle colonne chiave è piccola, riduce l'overhead di archiviazione, I/O e memoria di tutti gli indici in una tabella. Per calcolare la lunghezza della chiave, aggiungere le dimensioni di archiviazione per i tipi di dati usati dalle colonne chiave. Per altre informazioni, vedere Categorie di tipi di dati. |
| Unico | Se l'indice cluster non è univoco, una colonna univoca interna a 4 byte viene aggiunta automaticamente alla chiave di indice per garantire l'univocità. L'aggiunta di una colonna unica esistente alla chiave dell'indice raggruppato evita l'overhead di archiviazione, I/O e memoria della colonna uniqueifier in tutti gli indici di una tabella. Inoltre, Query Optimizer può generare piani di query più efficienti quando un indice è univoco. |
| Sempre crescente | In un indice sempre crescente, i dati verranno sempre aggiunti nell'ultima pagina dell'indice. In questo modo si evitano divisioni di pagina al centro dell'indice, riducendo la densità della pagina e riducendo le prestazioni. |
| Immutabile | La chiave di indice raggruppato fa parte di qualsiasi indice non raggruppato. Quando viene modificata una colonna chiave di un indice cluster, è necessario apportare anche una modifica in tutti gli indici non cluster, che aggiunge un sovraccarico di CPU, registrazione, I/O e memoria. L'overhead viene evitato se le colonne chiave dell'indice clusterizzato non sono modificabili. |
| Ha solo colonne non nullable | Se una riga contiene colonne nullable, deve includere una struttura interna denominata blocco NULL, che aggiunge 3-4 byte di archiviazione per riga in un indice. Rendere non nullable tutte le colonne dell'indice cluster evita questo sovraccarico. |
| Ha solo colonne a larghezza fissa | Le colonne che usano tipi di dati a larghezza variabile, ad esempio varchar o nvarchar , usano altri 2 byte per valore rispetto ai tipi di dati a larghezza fissa. L'uso di tipi di dati a larghezza fissa, ad esempio int , evita questo sovraccarico in tutti gli indici della tabella. |
Soddisfare il maggior numero possibile di queste proprietà quando si progetta un indice cluster non solo rende più efficiente l'indice cluster, ma anche tutti gli indici non cluster nella stessa tabella. Le prestazioni sono migliorate evitando sovraccarichi di archiviazione, I/O e memoria.
Ad esempio, una chiave di indice cluster con una singola colonna int o bigint non nullable include tutte queste proprietà se viene popolata da una IDENTITY clausola o da un vincolo predefinito usando una sequenza e non viene aggiornata dopo l'inserimento di una riga.
Al contrario, una chiave di indice cluster con una singola colonna uniqueidentifier è più ampia perché usa 16 byte di archiviazione invece di 4 byte per int e 8 byte per bigint e non soddisfa la proprietà sempre crescente a meno che i valori non vengano generati in sequenza.
Tip
Quando si crea un PRIMARY KEY vincolo, viene creato automaticamente un indice univoco che supporta il vincolo. Per impostazione predefinita, questo indice è cluster; Tuttavia, se questo indice non soddisfa le proprietà desiderate dell'indice cluster, è possibile creare il vincolo come non cluster e creare invece un indice cluster diverso.
Se non si crea un indice clusterizzato, la tabella viene archiviata come heap, che in genere non è consigliato.
Architettura dell'indice clusterizzato
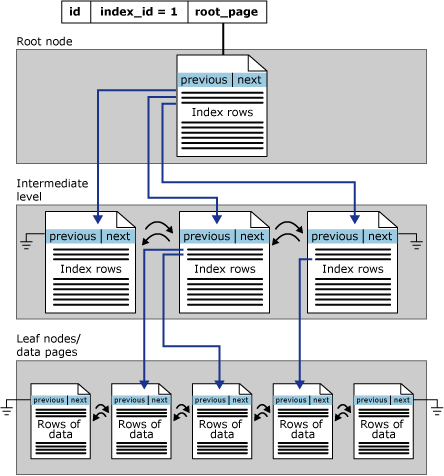
Gli indici rowstore sono organizzati come alberi B+. Ogni pagina dell'albero B+ di un indice viene definita nodo dell'indice. Il nodo di livello superiore dell'albero B+ viene definito nodo principale. I nodi inferiori dell'indice vengono definiti nodi foglia. I livelli dell'indice compresi tra il nodo radice e i nodi foglia sono noti come livelli intermedi. In un indice clusterizzato, i nodi foglia contengono le pagine di dati della tabella sottostante. I nodi di livello radice e intermedio contengono pagine di indice che includono le righe dell'indice. Ogni riga di indice contiene un valore di chiave e un puntatore a una pagina di livello intermedio nell'albero B+ o a una riga di dati nel livello foglia dell'indice. Le pagine di ogni livello dell'indice sono collegate in un elenco collegato doppiamente.
Gli indici cluster hanno una riga in sys.partitions per ogni partizione usata dall'indice, con index_id = 1. Per impostazione predefinita, un indice cluster include una singola partizione. Quando un indice cluster ha più partizioni, ogni partizione ha una struttura ad albero B+ separata che contiene i dati per tale partizione specifica. Ad esempio, se un indice cluster ha quattro partizioni, sono presenti quattro strutture ad albero B+, una in ogni partizione.
In base al tipo di dati nell'indice cluster, ogni struttura dell'indice cluster avrà una o più unità di allocazione in cui archiviare e gestire i dati per una partizione specifica. Ogni indice cluster contiene almeno un'unità di allocazione IN_ROW_DATA per partizione. L'indice cluster include anche un'unità LOB_DATA di allocazione per partizione se contiene colonne LOB (Large Object), ad esempio nvarchar(max). Ha anche un'unità ROW_OVERFLOW_DATA di allocazione per partizione se contiene colonne a lunghezza variabile che superano il limite di dimensioni di riga di 8.060 byte.
Le pagine nella struttura ad albero B+ vengono ordinate sul valore della chiave di indice cluster. Tutti gli inserimenti vengono eseguiti nella pagina in cui il valore della chiave nella riga inserita rientra nella sequenza di ordinamento tra le pagine esistenti. All'interno di una pagina, le righe non vengono necessariamente archiviate in un ordine fisico. Tuttavia, la pagina mantiene un ordinamento logico delle righe usando una struttura interna denominata matrice di slot. Le voci nello slot array vengono ordinate nell'ordine della chiave di indice.
Nella figura seguente viene illustrata la struttura di un indice cluster in una singola partizione.
Linee guida per la progettazione di indici non cluster
La differenza principale tra un indice cluster e un indice non cluster consiste nel fatto che un indice non cluster contiene un subset delle colonne della tabella, in genere ordinato in modo diverso dall'indice cluster. Facoltativamente, è possibile filtrare un indice non cluster, il che significa che contiene un subset di tutte le righe della tabella.
Un indice rowstore non clusterizzato basato su disco contiene i localizzatori di righe che puntano alla posizione di memoria della riga nella tabella di base. È possibile creare più indici non clusterizzati in una tabella o vista indicizzata. In genere, gli indici non cluster devono essere progettati per migliorare le prestazioni delle query usate di frequente che dovranno analizzare la tabella di base in caso contrario.
Analogamente a quando si utilizza l'indice di un libro, Query Optimizer cerca un valore di dati eseguendo una ricerca nell'indice non cluster per trovare la posizione del valore di dati nella tabella e quindi recupera i dati direttamente da quella posizione. Per questo motivo, gli indici non cluster sono la scelta ottimale per le query di corrispondenza esatta, in quanto l'indice contiene le voci che descrivono la posizione esatta nella tabella dei valori di dati cercati dalle query.
Ad esempio, per eseguire una query sulla HumanResources.Employee tabella per tutti i dipendenti che riportano a un responsabile specifico, Query Optimizer potrebbe usare l'indice IX_Employee_ManagerID non cluster, che ha ManagerID come prima colonna chiave. Poiché i ManagerID valori sono ordinati nell'indice non cluster, Query Optimizer può trovare rapidamente tutte le voci nell'indice che corrispondono al valore specificato ManagerID . Ogni voce di indice punta alla pagina esatta e alla riga nella tabella di base in cui è possibile recuperare i dati corrispondenti di tutte le altre colonne. Dopo che Query Optimizer trova tutte le voci nell'indice, può passare direttamente alla pagina e alla riga esatte per recuperare i dati anziché analizzare l'intera tabella di base.
Architettura dell'indice non clusterizzato
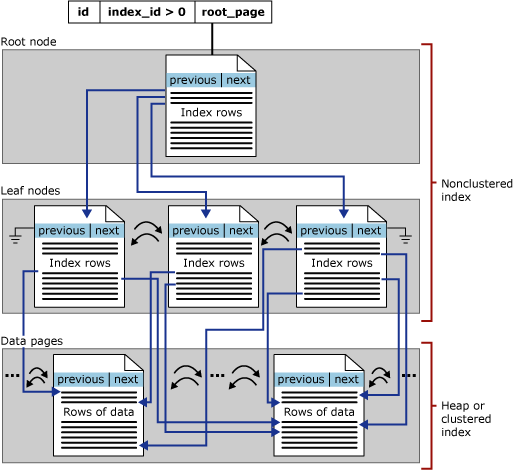
Gli indici rowstore non cluster basati su disco hanno la stessa struttura ad albero B+ degli indici cluster, ad eccezione delle differenze seguenti:
Un indice non cluster non contiene necessariamente tutte le colonne e le righe della tabella.
Il livello foglia di un indice non cluster è composto da pagine di indice invece che da pagine di dati. Le pagine di indice a livello foglia di un indice non cluster contengono colonne chiave. Facoltativamente, possono contenere anche un subset di altre colonne della tabella come colonne incluse, per evitare di recuperarle dalla tabella di base.
I localizzatori di righe nelle righe di indice non clusterizzato sono un puntatore a una riga, oppure sono una chiave dell'indice clusterizzato per una riga, come descritto di seguito.
Se una tabella include un indice cluster oppure l'indice è riferito a una vista indicizzata, l'indicatore di posizione delle righe corrisponde alla chiave di indice cluster per la riga.
Se la tabella è un heap, ovvero non ha un indice clusterizzato, il localizzatore di riga è un puntatore alla riga. Il puntatore è costituito dall'identificatore del file (ID), dal numero di pagina e dal numero di riga sulla pagina. L'intero puntatore è chiamato ID di riga (RID).
I localizzatori di riga garantiscono anche l'univocità nelle righe degli indici non clusterizzati. Nella tabella seguente viene descritto come il motore di database aggiunge a indici non cluster gli indicatori di posizione delle righe:
| Tipo di tabella di base | Tipo di indice non clusterizzato | Localizzatore di righe |
|---|---|---|
| Heap | ||
| Nonunique | RID aggiunto alle colonne chiave | |
| Unique | RID aggiunto alle colonne incluse | |
| Indice cluster univoco | ||
| Nonunique | Chiavi di indice clusterizzato aggiunte alle colonne chiave | |
| Unique | Chiavi di indice cluster aggiunte alle colonne incluse | |
| Indice cluster non univoco | ||
| Nonunique | Chiavi dell'indice clusterizzato e identificatore univoco (se presente) aggiunti alle colonne della chiave | |
| Unique | Chiavi di indice clusterizzato e uniqueifier (se presenti) aggiunti alle colonne incluse |
Il motore di database non archivia mai una determinata colonna più di una volta in un indice non cluster. L'ordine della chiave di indice specificato dall'utente quando crea un indice non cluster viene sempre rispettato: tutte le colonne del localizzatore di righe che devono essere aggiunte alla chiave di un indice non cluster vengono aggiunte alla fine della chiave, seguendo le colonne specificate nella definizione dell'indice. I localizzatori di righe della chiave dell'indice clusterizzato in un indice non clusterizzato possono essere utilizzati nell'elaborazione delle query, indipendentemente dal fatto che siano specificati in modo esplicito nella definizione dell'indice o aggiunti implicitamente.
Gli esempi seguenti illustrano come gli indicatori di posizione delle righe vengono implementati in indici non cluster:
| Indice raggruppato | Definizione di indice non clusterizzato | Definizione di indice non clusterizzato con dei localizzatori di riga | Explanation |
|---|---|---|---|
Indice cluster univoco con colonne chiave (A, B, C) |
Indice non cluster non univoco con colonne chiave (B, A) e colonne incluse (E, G) |
Colonne chiave (B, A, C) e colonne incluse (E, G) |
L'indice non cluster è non univoco, pertanto l'indicatore di posizione delle righe deve essere presente nelle chiavi di indice. Le colonne B e A dall'indicatore di posizione delle righe sono già presenti, pertanto solo la colonna C viene aggiunta. La colonna C viene aggiunta alla fine dell'elenco delle colonne chiave. |
Indice cluster univoco con colonna chiave (A) |
Indice non cluster non univoco con colonne chiave (B, C) e colonna inclusa (A) |
Colonne chiave (B, C, A) |
L'indice non cluster è non univoco, quindi alla chiave viene aggiunto l'indicatore di posizione delle righe. La colonna A non è già specificata come colonna chiave, quindi viene aggiunta alla fine dell'elenco delle colonne chiave. La colonna A è ora nella chiave, quindi non è necessario archiviarla come una colonna inclusa. |
Indice cluster univoco con colonna chiave (A, B) |
Indice non cluster univoco con colonna chiave (C) |
Colonna chiave (C) e colonne incluse (A, B) |
L'indice non cluster è univoco, quindi alle colonne incluse viene aggiunto l'indicatore di posizione delle righe. |
Gli indici non cluster hanno una riga in sys.partitions per ogni partizione usata dall'indice, con index_id > 1. Per impostazione predefinita, un indice non cluster include una singola partizione. Quando in un indice non cluster sono incluse più partizioni, ogni partizione ha una struttura ad albero B+ contenente le righe di indice per la partizione specifica. Ad esempio, se un indice non cluster ha quattro partizioni, sono presenti quattro strutture ad albero B+, una in ogni partizione.
In base ai tipi di dati nell'indice non cluster, ogni struttura dell'indice non cluster dispone di una o più unità di allocazione in cui archiviare e gestire i dati per una partizione specifica. Come minimo, ogni indice non clusterizzato ha un'unità IN_ROW_DATA di allocazione per partizione che memorizza le pagine dell'albero B+ dell'indice. L'indice non cluster include anche un'unità LOB_DATA di allocazione per partizione se contiene colonne LOB (Large Object), ad esempio nvarchar(max). Inoltre, ha un'unità ROW_OVERFLOW_DATA di allocazione per partizione se contiene colonne di lunghezza variabile che superano il limite di dimensioni di riga di 8.060 byte.
Nella figura seguente viene illustrata la struttura di un indice non cluster in una singola partizione.
Usare colonne incluse negli indici non clusterizzati
Oltre alle colonne chiave, un indice non cluster può includere anche colonne non chiave archiviate a livello foglia. Queste colonne non chiave vengono chiamate colonne incluse e vengono specificate nella INCLUDE clausola dell'istruzione CREATE INDEX .
Un indice con colonne non chiave incluse può migliorare significativamente le prestazioni delle query quando copre la query, ovvero quando tutte le colonne usate nella query si trovano nell'indice come colonne chiave o non chiave. Si ottengono miglioramenti delle prestazioni perché il motore di database può individuare tutti i valori di colonna all'interno dell'indice; la tabella di base non è accessibile, con conseguente minor numero di operazioni di I/O su disco.
Se una colonna deve essere recuperata da una query, ma non viene usata nei predicati della query, nelle aggregazioni e negli ordinamenti, aggiungerla come colonna inclusa e non come colonna chiave. Questo presenta i vantaggi seguenti:
Le colonne incluse possono usare tipi di dati non consentiti come colonne chiave di indice.
Le colonne incluse non vengono considerate dal motore di database quando si calcola il numero di colonne chiave di indice o le dimensioni della chiave di indice. Con le colonne incluse, le dimensioni massime della chiave non sono limitate a 900 byte. È possibile creare indici più ampi che coprono più query.
Quando si sposta una colonna dalla chiave di indice alle colonne incluse, la compilazione dell'indice richiede meno tempo perché l'operazione di ordinamento dell'indice diventa più veloce.
Se la tabella ha un indice clusterizzato, la colonna o le colonne definite nella chiave di indice clusterizzato vengono aggiunte automaticamente a ogni indice non clusterizzato nella tabella. Non è necessario specificarli né nella chiave di indice non clusterizzato né come colonne incluse.
Linee guida per gli indici con colonne incluse
Quando si progettano indici non cluster con colonne incluse, tenere presenti le linee guida seguenti:
Le colonne incluse possono essere definite esclusivamente in indici non clusterizzati di tabelle o viste indicizzate.
È possibile usare qualsiasi tipo di dati, ad eccezione di text, ntexte image.
Come colonne incluse è possibile utilizzare colonne calcolate che sono deterministiche, sia precise che imprecise. Per altre informazioni, vedere Indici per le colonne calcolate.
Come per le colonne chiave, le colonne calcolate derivate dai tipi di dati image, ntext e text possono essere incluse, purché il tipo di dati della colonna calcolata sia consentito in una colonna inclusa.
Non è possibile specificare i nomi delle colonne sia nell'elenco
INCLUDEsia nell'elenco delle colonne chiave.Non è possibile ripetere i nomi delle colonne nell'elenco
INCLUDE.Almeno una colonna chiave deve essere definita in un indice. Il numero massimo di colonne incluse è 1.023. Questo limite è rappresentato dal numero massimo di colonne nelle tabelle meno 1.
Indipendentemente dalla presenza di colonne incluse, le colonne chiave di indice devono rispettare le restrizioni esistenti relative alle dimensioni dell'indice pari al massimo a 16 colonne chiave e una dimensione totale della chiave di indice di 900 byte.
Consigli di progettazione per gli indici con colonne incluse
È consigliabile riprogettare gli indici non-clustered con una dimensione elevata della chiave dell'indice in modo che solo le colonne usate in predicati di query, aggregazioni e ordinamenti siano incluse come colonne chiave. Rendere tutte le altre colonne necessarie per la query colonne non chiave incluse. In questo modo si hanno tutte le colonne necessarie per coprire la query, contenendo al tempo stesso le dimensioni della chiave dell'indice e mantenendone l'efficienza.
Si supponga, ad esempio, che si desideri progettare un indice per coprire la query seguente.
SELECT AddressLine1,
AddressLine2,
City,
StateProvinceID,
PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
Per coprire la query è necessario definire tutte le colonne nell'indice. Sebbene sia possibile definire tutte le colonne come colonne chiave, la dimensione delle chiavi sarebbe di 334 byte. Dal momento che la sola colonna utilizzata come criterio di ricerca è la colonna PostalCode, la quale ha una lunghezza pari a 30 byte, è possibile migliorare la progettazione degli indici definendo PostalCode come colonna chiave e includendo tutte le altre colonne come colonne non chiave.
Nell'istruzione seguente viene creato un indice con colonne incluse per coprire la query.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Per accertarsi che l'indice copra la query, creare l'indice, quindi visualizzare il piano di esecuzione stimato. Se il piano di esecuzione mostra un operatore Index Seek per l'indice IX_Address_PostalCode , la query viene coperta dall'indice.
Considerazioni sulle prestazioni per gli indici con colonne incluse
Evitare di creare indici con un numero molto elevato di colonne incluse. Anche se l'indice potrebbe coprire più query, il vantaggio in termini di prestazioni diminuisce perché:
In una pagina rientrano meno righe di indice. Ciò aumenta l'I/O del disco e riduce l'efficienza della cache.
Per archiviare l'indice è necessario più spazio su disco. In particolare, l'aggiunta di tipi di dati varchar(max), nvarchar(max), varbinary(max)o xml nelle colonne incluse può aumentare significativamente i requisiti di spazio su disco. Ciò accade perché i valori delle colonne vengono copiati nel livello foglia dell'indice. risiedendo in tal modo sia nell'indice che nella tabella di base.
Le prestazioni di modifica dei dati diminuiscono perché molte colonne devono essere modificate sia nella tabella basata che nell'indice non cluster.
È necessario determinare se i miglioramenti delle prestazioni delle query superano la diminuzione delle prestazioni di modifica dei dati e l'aumento dei requisiti di spazio su disco.
Linee guida per la progettazione di indici univoci
Un indice univoco garantisce che la chiave di indice non contenga valori duplicati. La creazione di un indice univoco è possibile solo quando l'univocità è una caratteristica dei dati stessi. Per verificare, ad esempio, che i valori della colonna NationalIDNumber nella tabella HumanResources.Employee siano univoci quando la chiave primaria è EmployeeID, creare un vincolo UNIQUE nella colonna NationalIDNumber. Il vincolo rifiuta qualsiasi tentativo di introdurre righe con numeri ID nazionali duplicati.
Per gli indici univoci a più colonne, l'indice garantisce che ogni combinazione di valori nella chiave dell'indice sia univoca. Ad esempio, se viene creato un indice univoco in una combinazione di LastNamecolonne , FirstNamee MiddleName , non è possibile che due righe nella tabella abbiano gli stessi valori per queste colonne.
Sia gli indici clustered che quelli nonclustered possono essere univoci. È possibile creare un indice cluster univoco e più indici non cluster univoci nella stessa tabella.
I vantaggi degli indici univoci includono:
- Le regole business che richiedono l'univocità dei dati vengono applicate.
- Vengono fornite informazioni aggiuntive utili per l'ottimizzatore di query.
Se si crea un vincolo PRIMARY KEY o UNIQUE, viene creato automaticamente un indice univoco basato sulle colonne specificate. Non esistono differenze significative tra la creazione determinata da un vincolo UNIQUE e la creazione di un indice univoco indipendente da un vincolo. La convalida dei dati viene eseguita nello stesso modo e Query Optimizer non differenzia un indice univoco creato da un vincolo da un indice creato in modo manuale. Tuttavia, è consigliabile creare un UNIQUE o PRIMARY KEY vincolo sulla colonna quando l'applicazione delle regole aziendali è l'obiettivo. In questo modo l'obiettivo dell'indice risulta chiaro.
Considerazioni sugli indici univoci
Se nei dati sono presenti valori di chiave duplicati, non è possibile creare un indice univoco, un vincolo
UNIQUEo un vincoloPRIMARY KEY.Se i dati sono univoci e si desidera imporre l'unicità, la creazione di un indice univoco anziché di un indice non univoco per la stessa combinazione di colonne fornirà a Query Optimizer una maggiore quantità di informazioni che consentiranno di creare piani di esecuzione più efficienti. In questo caso, è consigliabile creare un
UNIQUEvincolo o un indice univoco.In un indice non cluster univoco possono essere contenute colonne non chiave. Per altre informazioni, vedere Usare colonne incluse in indici non cluster.
A differenza di un
PRIMARY KEYvincolo, è possibile creare unUNIQUEvincolo o un indice univoco con una colonna nullable nella chiave di indice. Ai fini dell'applicazione dell'univocità, due valori NULL sono considerati uguali. Ciò significa, ad esempio, che in un indice univoco a colonna singola la colonna può essere NULL solo per una riga della tabella.
Linee guida per la progettazione di indici filtrati
Un indice filtrato è un indice non cluster ottimizzato, particolarmente adatto per le query che richiedono un piccolo subset di dati nella tabella. Usa un predicato di filtro nella definizione dell'indice per indicizzare una parte di righe nella tabella. Un indice filtrato ben progettato può migliorare le prestazioni delle query, ridurre i costi di aggiornamento degli indici e ridurre i costi di archiviazione degli indici rispetto a un indice di tabella completa.
Rispetto agli indici di tabella completa, gli indici filtrati consentono di ottenere i vantaggi seguenti:
Prestazioni di esecuzione delle query e qualità del piano migliorate
Un indice filtrato ben progettato migliora le prestazioni delle query e la qualità del piano di esecuzione perché è più piccolo di un indice non clusterizzato di tabella completa. Un indice filtrato dispone di statistiche filtrate, che sono più accurate delle statistiche di tabella completa perché coprono solo le righe nell'indice filtrato.
Riduzione dei costi di aggiornamento degli indici
Un indice viene aggiornato solo quando le istruzioni DML (Data Manipulation Language) influiscono sui dati nell'indice. Un indice filtrato riduce i costi di aggiornamento degli indici rispetto a un indice non cluster di tabella completa perché è più piccolo e viene aggiornato solo quando i dati nell'indice sono interessati. È possibile disporre di un numero elevato di indici filtrati, soprattutto quando questi ultimi contengono dati interessati raramente. Analogamente, se un indice filtrato contiene solo i dati interessati di frequente, le dimensioni minori dell'indice riducono il costo dell'aggiornamento delle statistiche.
Costi di archiviazione dell'indice ridotti
La creazione di un indice filtrato può ridurre lo spazio di archiviazione su disco per gli indici non cluster nel caso in cui non sia necessario un indice di tabella completa. Potrebbe essere possibile sostituire un indice non clusterizzato con più indici filtrati senza aumentare significativamente i requisiti di memoria.
Gli indici filtrati sono utili quando le colonne contengono subset ben definiti di dati. Di seguito sono riportati alcuni esempi:
Colonne che contengono molti valori NULL.
Colonne eterogenee che contengono categorie di dati.
Colonne che contengono intervalli di valori, ad esempio quantità, tempo e date.
I costi di aggiornamento ridotti per gli indici filtrati sono più evidenti quando il numero di righe nell'indice è ridotto rispetto a un indice di tabella completa. Se l'indice filtrato include la maggior parte delle righe della tabella, è possibile che i costi di manutenzione siano maggiori rispetto a quelli relativi a un indice di tabella completa. In questo caso è opportuno utilizzare un indice di tabella completa anziché un indice filtrato.
Gli indici filtrati sono definiti in una tabella e supportano solo operatori di confronto semplici. Se è necessaria un'espressione di filtro con logica complessa o fa riferimento a più tabelle, è necessario creare una colonna calcolata indicizzata o una vista indicizzata.
Considerazioni sulla progettazione degli indici filtrati
Per progettare indici filtrati efficaci, è importante comprendere quali sono le query utilizzate dall'applicazione e il modo in cui sono correlate ai subset dei dati. Alcuni esempi di dati con subset ben definiti sono colonne con molti valori NULL, colonne con categorie eterogenee di valori e colonne con intervalli distinti di valori.
Le considerazioni di progettazione seguenti offrono diversi scenari per i casi in cui un indice filtrato può offrire vantaggi rispetto agli indici di tabella completa.
Indici filtrati per sottoinsiemi di dati
Quando una colonna dispone solo di un numero ridotto di valori rilevanti per le query, è possibile creare un indice filtrato sul sottoinsieme di valori. Ad esempio, quando la colonna è principalmente NULL e la query richiede solo valori non NULL, è possibile creare un indice filtrato contenente le righe non NULL.
Nel database di esempio AdventureWorks, ad esempio, è disponibile una tabella Production.BillOfMaterials con 2.679 righe. La EndDate colonna contiene solo 199 righe che contengono un valore non NULL e le altre 2480 righe contengono NULL. L'indice filtrato seguente illustra le query che restituiscono le colonne definite nell'indice e che richiedono solo righe con un valore non NULL per EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
L'indice filtrato FIBillOfMaterialsWithEndDate è valido per la query seguente.
Visualizzare il piano di esecuzione stimato per determinare se l'ottimizzatore di query ha utilizzato l'indice filtrato.
SELECT ProductAssemblyID,
ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
Per altre informazioni sulla creazione di indici filtrati e sulla definizione dell'espressione del predicato dell'indice filtrato, vedere Creare indici filtrati.
Indici filtrati per dati eterogenei
Se in una tabella sono presenti righe di dati eterogenei, è possibile creare un indice filtrato per una o più categorie di dati.
Ogni prodotto elencato nella tabella Production.Product , ad esempio, è assegnato a un ProductSubcategoryID, associato a sua volta alle categorie di prodotti Bikes, Components, Clothing o Accessories. Queste categorie sono eterogenee poiché i valori di colonna relativi nella tabella Production.Product non sono strettamente correlati. Ad esempio, le colonne Color, ReorderPoint, ListPrice, Weight, Classe Style dispongono di caratteristiche univoche per ogni categoria di prodotti. Supponiamo che vi siano query frequenti per gli accessori, che hanno sottocategorie comprese tra 27 e 36, estremi inclusi. È possibile migliorare le prestazioni delle query per gli accessori creando un indice filtrato sulle sottocategorie degli accessori, come illustrato nell'esempio seguente.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
INCLUDE (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
L'indice FIProductAccessories filtrato copre la query seguente perché i risultati della query sono contenuti nell'indice e il piano di query non richiede l'accesso alla tabella di base. Ad esempio, l'espressione del predicato di query ProductSubcategoryID = 33 è un subset del predicato dell'indice filtrato ProductSubcategoryID >= 27 e ProductSubcategoryID <= 36, le colonne ProductSubcategoryID e ListPrice nel predicato di query sono entrambe colonne chiave nell'indice e il nome è archiviato al livello foglia dell'indice come colonna inclusa.
SELECT Name,
ProductSubcategoryID,
ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33
AND ListPrice > 25.00;
Chiave e colonne incluse negli indici filtrati
È consigliabile aggiungere un numero ridotto di colonne in una definizione di indice filtrata, solo in base alle esigenze di Query Optimizer per scegliere l'indice filtrato per il piano di esecuzione della query. L'ottimizzatore delle query può scegliere un indice filtrato per la query indipendentemente dal fatto che la copra o che non la copra. Tuttavia, è più probabile che l'ottimizzatore di query scelga un indice filtrato quando copre la query.
In alcuni casi, un indice filtrato copre la query senza includere le colonne nell'espressione che lo definisce come colonne chiave o incluse nella definizione dell'indice stesso. Le linee guida seguenti indicano quando una colonna nell'espressione che definisce l'indice filtrato deve essere una colonna chiave o inclusa nella definizione dell'indice filtrato stesso. Gli esempi si riferiscono all'indice filtrato FIBillOfMaterialsWithEndDate creato in precedenza.
Non è necessario che una colonna nell'espressione che definisce l'indice filtrato sia una colonna chiave o sia inclusa nella definizione dell'indice stesso, se l'espressione che definisce l'indice filtrato è equivalente al predicato della query e la query non restituisce la colonna in tale espressione con i risultati della query. L'indice FIBillOfMaterialsWithEndDate, ad esempio, copre la query seguente perché il predicato della query è equivalente all'espressione filtro ed EndDate non viene restituito con i risultati della query. Non è necessario che l'indice FIBillOfMaterialsWithEndDate contenga EndDate come chiave o colonna inclusa nella definizione dell'indice filtrato.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Una colonna nell'espressione che definisce l'indice filtrato deve essere una colonna chiave o inclusa nella definizione dell'indice se il predicato della query la utilizza in un confronto non equivalente all'espressione che definisce l'indice filtrato. L'indice FIBillOfMaterialsWithEndDate , ad esempio, è valido per la query seguente perché seleziona un subset di righe dall'indice filtrato. Tale indice tuttavia non copre la query seguente poiché EndDate viene utilizzato nel confronto EndDate > '20040101', che non è equivalente all'espressione che definisce l'indice filtrato. Query Processor non può eseguire questa query senza esaminare i valori di EndDate. Di conseguenza, EndDate deve essere una colonna chiave o inclusa nella definizione dell'indice filtrato.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Una colonna nell'espressione che definisce l'indice filtrato deve essere una colonna chiave o inclusa nella definizione dell'indice se è presente nel set di risultati della query. L'indice FIBillOfMaterialsWithEndDate, ad esempio, non copre la query seguente perché restituisce la colonna EndDate nei risultati della query. Di conseguenza, EndDate deve essere una colonna chiave o inclusa nella definizione dell'indice filtrato.
SELECT ComponentID,
StartDate,
EndDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Non è necessario che la chiave di indice cluster della tabella sia una colonna chiave o inclusa nella definizione dell'indice filtrato. La chiave dell'indice clusterizzato viene inclusa automaticamente in tutti gli indici non clusterizzati, inclusi gli indici filtrati.
Operatori di conversione dei dati nel predicato del filtro
Se l'operatore di confronto specificato nell'espressione che definisce l'indice filtrato determina una conversione dei dati implicita o esplicita, si verificherà un errore se la conversione viene eseguita sul lato sinistro di un operatore di confronto. Una soluzione consiste nello scrivere l'espressione che definisce l'indice filtrato con l'operatore di conversione dei dati (CAST o CONVERT) sul lato destro dell'operatore di confronto.
Nell'esempio seguente viene creata una tabella con colonne di tipi di dati diversi.
CREATE TABLE dbo.TestTable
(
a INT,
b VARBINARY(4)
);
Nella definizione di indice filtrata seguente, la colonna b viene convertita in modo implicito in un tipo di dati integer per confrontarla con la costante 1. Verrà generato un messaggio di errore 10611 poiché la conversione viene eseguita sul lato sinistro dell'operatore nel predicato filtrato.
CREATE NONCLUSTERED INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = 1;
La soluzione consiste nel convertire la costante sul lato destro in modo che sia dello stesso tipo della colonna b, come illustrato nell'esempio seguente:
CREATE INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = CONVERT (VARBINARY(4), 1);
Lo spostamento della conversione dei dati dal lato sinistro a quello destro di un operatore di confronto potrebbe modificare il significato della conversione. Nell'esempio precedente, quando l'operatore CONVERT è stato aggiunto a destra, il confronto è cambiato da un confronto int a un confronto varbinary .
Architettura degli indici columnstore
Un indice columnstore è una tecnologia per l'archiviazione, il recupero e la gestione dei dati usando un formato di dati a colonne, denominato columnstore. Per ulteriori informazioni, consultare Panoramica sugli indici columnstore.
Per informazioni sulla versione e per scoprire le novità, vedere Novità negli indici columnstore.
Conoscere queste nozioni di base semplifica la comprensione di altri articoli columnstore che spiegano come usare questa tecnologia in modo efficace.
L'archiviazione dati usa columnstore e rowstore
Quando si parla di indici columnstore, si usano i termini rowstore e columnstore per enfatizzare il formato per l'archiviazione dei dati. Gli indici columnstore usano entrambi i tipi di archiviazione.
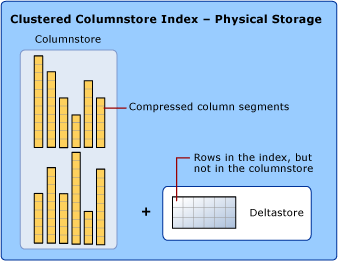
Un columnstore è un insieme di dati organizzati logicamente sotto forma di tabella con righe e colonne e archiviati fisicamente in un formato colonnare.
Un indice columnstore archivia fisicamente la maggior parte dei dati nel formato columnstore. Nel formato columnstore i dati vengono compressi e decompressi come colonne. Non è necessario decomprimere altri valori in ogni riga, se non sono richiesti dalla query. Ciò consente di analizzare in modo veloce un'intera colonna di una tabella di grandi dimensioni.
Un rowstore è un insieme di dati organizzati logicamente in forma di tabella con righe e colonne e archiviati fisicamente in un formato orientato alle righe. Questo è stato il modo tradizionale per archiviare dati di tabella relazionali, ad esempio un indice ad albero B+ clustered o un heap.
Un indice columnstore archivia fisicamente anche alcune righe in un formato rowstore denominato deltastore. Il deltastore, detto anche gruppi di righe delta, è un'area di conservazione temporanea per le righe in numero insufficiente per poter essere compresse nel columnstore. Ogni rowgroup differenziale viene implementato come indice ad albero B+ clusterizzato, ovvero un rowstore.
Le operazioni vengono eseguite sui rowgroup e sui segmenti di colonna
L'indice columnstore raggruppa le righe in unità gestibili. Ognuna di queste unità viene chiamata rowgroup. Per prestazioni ottimali, il numero di righe in un rowgroup è sufficientemente grande da migliorare il rapporto di compressione e sufficientemente piccolo da trarre vantaggio dalle operazioni di memoria.
Ad esempio, l'indice columnstore esegue queste operazioni sui rowgroup:
Compressione dei rowgroup nel columnstore. La compressione viene eseguita su ogni segmento di colonna all'interno di un rowgroup.
Unisce i rowgroup durante un'operazione
ALTER INDEX ... REORGANIZE, inclusa la rimozione dei dati eliminati.Ricrea tutti i gruppi di righe durante un'operazione
ALTER INDEX ... REBUILD.Restituzione di informazioni sull'integrità e la frammentazione dei rowgroup nelle viste a gestione dinamica (DMV).
Il deltastore è composto da uno o più gruppi di righe denominati gruppi di righe delta. Ogni rowgroup differenziale è un indice B+ tree clusterizzato che archivia piccoli caricamenti massivi e inserimenti fino a quando il rowgroup non contiene 1.048.576 righe, momento in cui un processo chiamato tuple-mover comprime automaticamente un rowgroup chiuso nel columnstore.
Per altre informazioni sugli stati dei rowgroup, vedere sys.dm_db_column_store_row_group_physical_stats.
Tip
La presenza di un numero eccessivo di rowgroup di piccole dimensioni riduce la qualità dell'indice columnstore. Un'operazione di riorganizzazione unisce i rowgroup più piccoli in base a un criterio di soglia interna, che determina come rimuovere le righe eliminate e combinare i rowgroup compressi. Dopo un'unione, la qualità dell'indice viene migliorata.
In SQL Server 2019 (15.x) e versioni successive, il tuple-mover è supportato da un'attività di unione in background che comprime automaticamente i rowgroup differenziali aperti più piccoli che sono esistiti per un certo periodo, come determinato da una soglia interna, o unisce i rowgroup compressi dai quali è stato eliminato un numero elevato di righe.
Ogni colonna dispone di alcuni dei relativi valori in ogni rowgroup. Questi valori sono denominati segmenti di colonna. Ogni rowgroup contiene un segmento di colonna per ogni colonna della tabella. Ogni colonna ha una sezione di colonna in ogni gruppo di righe.
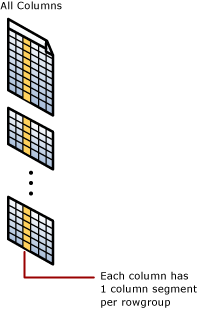
Quando l'indice columnstore comprime un rowgroup, ogni segmento di colonna viene compresso separatamente. Per decomprimere un'intera colonna, l'indice columnstore deve semplicemente decomprimere un segmento di colonna da ogni rowgroup.
I caricamenti e gli inserimenti di piccole dimensioni vanno nel deltastore
Un indice columnstore migliora le prestazioni e la compressione del columnstore comprimendo almeno 102.400 righe alla volta nell'indice columnstore. Per comprimere le righe in blocco, l'indice columnstore accumula piccoli caricamenti e inserimenti nel deltastore. Le operazioni deltastore vengono gestite in background. Per restituire i risultati della query, l'indice columnstore clusterizzato combina i risultati della query sia dal columnstore che dal deltastore.
Le righe passano al deltastore quando sono:
Inserito con l'istruzione
INSERT INTO ... VALUES.Alla fine di un caricamento in blocco, e il loro numero è inferiore a 102.400.
Updated. Ogni aggiornamento viene implementato come un'eliminazione e un inserimento.
L'archivio differenziale archivia anche un elenco di ID delle righe eliminate, contrassegnate come tali ma non ancora eliminate fisicamente dall'archivio colonnare.
Quando i gruppi di righe delta sono pieni, vengono compressi nel columnstore
Gli indici columnstore clusterizzati raccolgono fino a 1.048.576 righe in ogni gruppo di righe delta prima di comprimere il gruppo di righe nell'archivio columnstore. migliorando così la compressione dell'indice columnstore. Quando un rowgroup delta raggiunge il numero massimo di righe, passa dallo stato OPEN allo stato CLOSED. Un processo in background denominato tuple-mover verifica la presenza di gruppi di righe chiusi. Se il processo trova un rowgroup chiuso, lo comprime e lo archivia nel columnstore.
Quando un rowgroup delta è stato compresso, il rowgroup delta esistente passa nello stato TOMBSTONE per essere successivamente rimosso dal tuple-mover quando non vi sono più riferimenti ad esso, mentre il nuovo rowgroup compresso viene contrassegnato come COMPRESSED.
Per altre informazioni sugli stati dei rowgroup, vedere sys.dm_db_column_store_row_group_physical_stats.
È possibile forzare l'inserimento dei gruppi di righe delta nel columnstore utilizzando ALTER INDEX per ricreare o riorganizzare l'indice. In caso di utilizzo elevato di memoria durante la compressione, l'indice columnstore potrebbe ridurre il numero di righe nel rowgroup compresso.
Ogni partizione della tabella dispone dei propri rowgroup e rowgroup delta
Il concetto di partizionamento è lo stesso in un indice cluster, in un heap e in un indice columnstore. Il partizionamento di una tabella suddivide la tabella in piccoli gruppi di righe in base a un intervallo di valori di colonna e viene spesso usato per la gestione dei dati. Ad esempio, è possibile creare una partizione per ogni anno di dati e quindi usare il cambio di partizione per archiviare i dati obsoleti in una risorsa di archiviazione meno costosa.
I rowgroup sono sempre definiti all'interno di una partizione di tabella. Quando un indice columnstore è partizionato, ogni partizione ha i propri rowgroup compressi e rowgroup delta. Una tabella non partizionata contiene una partizione.
Tip
Se è necessario rimuovere i dati dal columnstore, è consigliabile usare il partizionamento delle tabelle. Sostituire e troncare le partizioni che non sono più necessarie è una strategia efficiente per rimuovere i dati senza introdurre frammentazione nell'archivio colonnare.
Ogni partizione può avere più rowgroup delta
Ogni partizione può avere più di un rowgroup differenziale. Quando l'indice columnstore deve aggiungere dati a un rowgroup differenziale e il rowgroup differenziale è bloccato da un'altra transazione, l'indice columnstore tenta di ottenere un blocco su un rowgroup differenziale diverso. In assenza di rowgroup differenziali disponibili, l'indice columnstore crea un nuovo rowgroup differenziale. Ad esempio, una tabella con 10 partizioni potrebbe avere facilmente 20 o più rowgroup delta.
Combinare indici columnstore e rowstore nella stessa tabella
Un indice non cluster contiene una copia totale o parziale di tutte le righe e colonne della tabella sottostante. L'indice è definito sotto forma di una o più colonne della tabella e ha una condizione facoltativa che consente di filtrare le righe.
È possibile creare un indice columnstore non cluster aggiornabile su una tabella rowstore. L'indice columnstore archivia una copia dei dati, pertanto è necessario spazio di archiviazione aggiuntivo. Tuttavia, i dati nell'indice columnstore vengono compressi in dimensioni molto inferiori rispetto alle richieste della tabella rowstore. In questo modo, è possibile eseguire analisi sull'indice columnstore e sui carichi di lavoro OLTP nell'indice rowstore contemporaneamente. Il columnstore viene aggiornato quando i dati nella tabella rowstore vengono modificati. In questo modo entrambi gli indici possono usare gli stessi dati.
Una tabella rowstore può avere un solo indice columnstore non clusterizzato. Per ulteriori informazioni, vedere Indici Columnstore - Linee guida per la progettazione.
È possibile avere uno o più indici rowstore non clusterizzati su una tabella columnstore clusterizzata. In questo modo, è possibile eseguire efficienti operazioni di ricerca nelle tabelle del columnstore sottostante. Sono disponibili anche altre opzioni. Ad esempio, è possibile applicare l'univocità usando un UNIQUE vincolo nella tabella rowstore. Quando un valore non univoco non viene inserito nella tabella rowstore, il motore di database non inserisce neanche il valore nel columnstore.
Considerazioni sulle prestazioni dei columnstore non clusterizzati
La definizione dell'indice columnstore nonclustered supporta una condizione di filtro. Per ridurre al minimo l'impatto sulle prestazioni dell'aggiunta di un indice columnstore, usare un'espressione di filtro per creare un indice columnstore non clusterizzato solo sul subset di dati necessario per analitiche.
Una tabella ottimizzata per la memoria può avere un indice di tipo columnstore. È possibile crearlo quando la tabella viene creata o aggiungerla in un secondo momento con ALTER TABLE.
Per altre informazioni, vedere Indici columnstore - Prestazioni delle query.
Linee guida per la progettazione di indici hash ottimizzati per la memoria
Quando si usa In-Memory OLTP, tutte le tabelle ottimizzate per la memoria devono avere almeno un indice. Per una tabella ottimizzata per la memoria, ogni indice è ottimizzato per la memoria. Gli indici hash sono uno dei tipi di indice possibili in una tabella ottimizzata per la memoria. Per ulteriori informazioni, vedere Indici per le tabelle ottimizzate per la memoria.
Architettura dell'indice hash ottimizzata per la memoria
Un indice hash è costituito da una matrice di puntatori e ogni elemento della matrice viene definito bucket di hash.
- Ogni bucket è costituito da 8 byte, utilizzati per memorizzare l'indirizzo di memoria di una lista concatenata di elementi chiave.
- Ogni voce rappresenta un valore per una chiave di indice, oltre all'indirizzo della riga corrispondente nella tabella ottimizzata per la memoria sottostante.
- Ogni voce punta alla voce successiva in una lista concatenata di voci, tutte concatenate al bucket corrente.
Il numero di bucket deve essere specificato in fase di creazione dell'indice:
- Quanto più basso è il rapporto tra bucket e righe della tabella o tra bucket e valori distinti, tanto più lunga è in media la lista concatenata del bucket.
- Gli elenchi di collegamenti brevi risultano più veloci rispetto agli elenchi di collegamenti lunghi.
- Il numero massimo di bucket negli indici hash è 1.073.741.824.
Tip
Per determinare il corretto BUCKET_COUNT per i propri dati, vedere Configurare il numero di bucket dell'indice hash.
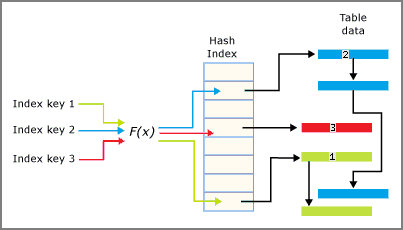
La funzione hash si applica alle colonne chiave dell'indice e il risultato della funzione determina il bucket in cui rientra la chiave. Ogni bucket ha un puntatore alle righe i cui valori di chiave hash sono associati a quel bucket.
La funzione di hashing utilizzata per gli indici hash presenta le caratteristiche seguenti:
- Il motore di database include una funzione hash che viene usata per tutti gli indici hash.
- La funzione hash è deterministica. Nell'indice hash, lo stesso valore della chiave di input viene sempre associato allo stesso bucket.
- È possibile che venga eseguito il mapping di più chiavi di indice allo stesso bucket di hash.
- La funzione hash è bilanciata, il che significa che la distribuzione dei valori delle chiavi di indice nei bucket hash segue in genere una distribuzione di Poisson o a campana, non una distribuzione lineare uniforme.
- La distribuzione di probabilità di Poisson non è uniforme. I valori delle chiavi di indice non vengono distribuiti in modo uniforme nei bucket di hash.
- Se viene eseguito il mapping di due chiavi dell'indice allo stesso bucket di hash, si verifica una collisione hash. Un numero elevato di collisioni hash può avere un effetto sulle prestazioni per le operazioni di lettura. Un obiettivo realistico è che il 30% dei bucket contenga due valori chiave diversi.
Nell'immagine seguente è riepilogata l'interazione tra l'indice hash e i bucket.
Configurare il numero di bucket dell'indice hash
Il numero di bucket dell'indice hash viene specificato al momento della creazione dell'indice e può essere modificato tramite la sintassi ALTER TABLE...ALTER INDEX REBUILD.
Nella maggior parte dei casi, il numero di bucket deve essere compreso tra 1 e 2 volte il numero di valori distinti nella chiave di indice.
Potrebbe non essere sempre possibile stimare il numero di valori di una determinata chiave di indice. Le prestazioni sono di norma ancora soddisfacenti se il valore BUCKET_COUNTè al massimo 10 volte superiore al numero effettivo di valori chiave e la stima di un valore superiore è in genere migliore della stima di un valore inferiore.
Un numero di bucket troppo ridotto può avere i seguenti svantaggi:
- Più collisioni hash di valori di chiave distinti.
- Ciascun valore distinto è obbligato a condividere lo stesso bucket con un altro valore distinto.
- La lunghezza media della catena per ciascun bucket aumenta.
- Più lunga è la catena di bucket, più lente sono le ricerche per uguaglianza nell'indice.
Un numero di bucket troppo elevato può avere i seguenti svantaggi:
- Un numero di bucket troppo elevato può comportare la presenza di più bucket vuoti.
- I bucket vuoti influiscono sulle prestazioni delle analisi complete degli indici. Se vengono eseguite scansioni regolarmente, è consigliabile scegliere un numero di bucket vicino al numero di valori distinti della chiave dell'indice.
- I bucket vuoti utilizzano memoria, anche se ogni bucket utilizza solo 8 byte.
Note
L'aggiunta di ulteriori bucket non determina in alcun modo la riduzione del concatenamento di voci che condividono un valore duplicato. La frequenza di duplicazione dei valori viene usata per decidere se un indice hash o un indice non cluster è il tipo di indice appropriato, non per calcolare il numero di bucket.
Considerazioni sulle prestazioni per gli indici hash
Le prestazioni di un indice hash sono:
- Eccellenti quando il predicato nella clausola
WHEREspecifica un valore esatto per ogni colonna della chiave di indice hash. Un indice hash ricorre a una scansione in presenza di un predicato di disuguaglianza. - Prestazioni scarse quando il predicato nella clausola
WHEREcerca un intervallo di valori nella chiave dell'indice. - Scarse quando il predicato nella clausola
WHEREspecifica un determinato valore per la prima colonna di una chiave di indice hash a due colonne, ma non specifica un valore per altre colonne della chiave.
Tip
Il predicato deve includere tutte le colonne nella chiave dell'indice hash. L'indice hash richiede l'intera chiave per accedere all'indice.
Se viene utilizzato un indice hash e il numero di chiavi di indice uniche è più di 100 volte inferiore al numero di righe, considerare un aumento del numero di bucket per evitare lunghe catene di righe, oppure utilizzare un indice noncluster invece.
Creare un indice hash
Quando si crea un indice hash, considerare quanto segue:
- Un indice hash può essere presente solo in una tabella ottimizzata per la memoria. Non può esistere in una tabella basata su disco.
- Un indice hash non è univoco per impostazione predefinita, ma può essere dichiarato come univoco.
L'esempio seguente crea un indice hash univoco:
ALTER TABLE MyTable_memop ADD INDEX ix_hash_Column2
UNIQUE HASH (Column2) WITH (BUCKET_COUNT = 64);
Versioni delle righe e raccolta dei rifiuti nelle tabelle ottimizzate per la memoria
In una tabella ottimizzata per la memoria, quando una riga è interessata da un'istruzione UPDATE , la tabella crea una versione aggiornata della riga. Durante la transazione di aggiornamento, altre sessioni potrebbero riuscire a leggere la versione precedente della riga e quindi evitare il rallentamento delle prestazioni associato a un blocco di riga.
L'indice hash potrebbe anche avere versioni diverse delle relative voci per includere l'aggiornamento.
In seguito, quando le versioni precedenti non sono più necessarie, un thread di Garbage Collection (GC) attraversa i bucket e i relativi elenchi di collegamenti per eliminare le voci obsolete. Il thread GC offre prestazioni migliori se le catene degli elenchi di collegamenti sono brevi. Per altre informazioni, vedere Garbage Collection per OLTP in memoria.
Linee guida per la progettazione di indici non cluster ottimizzati per la memoria
Oltre agli indici hash, gli indici non cluster sono gli altri tipi di indice possibili in una tabella ottimizzata per la memoria. Per ulteriori informazioni, vedere Indici per le tabelle ottimizzate per la memoria.
Architettura dell'indice non clusterizzato ottimizzata per la memoria
Gli indici non cluster nelle tabelle ottimizzate per la memoria vengono implementati usando una struttura di dati denominata albero Bw, originariamente immaginata e descritta da Microsoft Research nel 2011. Un Bw-tree è una variante di B-tree priva di lock e latch. Per ulteriori informazioni, vedere Albero Bw: un albero B per nuove piattaforme Hardware.
A livello generale, l'albero Bw può essere compreso come una mappa di pagine organizzate in base all'ID pagina (PidMap), una funzionalità per allocare e riutilizzare gli ID di pagina (PidAlloc) e un set di pagine collegate nella mappa della pagina e tra loro. Questi tre sottocomponenti di alto livello costituiscono la struttura interna di base di un albero Bw.
La struttura è simile a quella di un normale albero B in quanto ogni pagina ha una raccolta di valori di chiave ordinati e sono presenti livelli di indice che puntano a un livello inferiore e livelli foglia che puntano a una riga di dati. Tuttavia sono presenti delle differenze.
Analogamente agli indici hash, è possibile collegare più righe di dati per supportare il controllo delle versioni. I puntatori di pagina tra i livelli sono ID di pagina logici, ovvero offset in una tabella di mappatura delle pagine, che a sua volta contiene l'indirizzo fisico di ogni pagina.
Non sono previsti aggiornamenti in-place delle pagine dell'indice. A questo scopo, vengono introdotte nuove pagine delta.
- Per aggiornare la pagina, non sono richiesti meccanismi di latch o di lock.
- Le pagine di indice non hanno dimensioni fisse.
Il valore della chiave in ogni pagina di livello non foglia è il valore più alto contenuto nell'elemento figlio a cui punta, e ogni riga contiene anche l'ID logico di quella pagina. Nelle pagine a livello di foglia, oltre al valore chiave, è contenuto l'indirizzo fisico della riga di dati.
Le ricerche dei punti sono simili agli alberi B, ad eccezione del fatto che poiché le pagine sono collegate in una sola direzione, il motore di database segue i puntatori a pagina destra, in cui ogni pagina non foglia ha il valore più alto del relativo elemento figlio, anziché il valore più basso come in un albero B.
Se è necessario modificare una pagina a livello foglia, il motore di database non modifica la pagina stessa. Il motore di database crea invece un record differenziale che descrive la modifica e lo aggiunge alla pagina precedente. Quindi aggiorna anche l’indirizzo della tabella di mappatura delle pagine della pagina precedente con l’indirizzo del record delta, che ora diventa l’indirizzo fisico di questa pagina.
Per la gestione della struttura di un albero Bw sono possibili tre opzioni diverse: consolidamento, divisione e unione.
Consolidamento delta
Una lunga catena di record differenziali può infine ridurre le prestazioni di ricerca in quanto potrebbe richiedere un attraversamento a catena lunga durante la ricerca in un indice. Se un nuovo record delta viene aggiunto a una catena che ha già 16 elementi, le modifiche nei record delta vengono consolidate nella pagina indice di riferimento, che viene quindi ricostruita, incluse le modifiche indicate dal nuovo record delta che ha attivato il consolidamento. La nuova pagina ha lo stesso ID ma un nuovo indirizzo di memoria.
Pagina divisa
Una pagina di indice nell'albero Bw aumenta in base alle esigenze a partire dall'archiviazione di una singola riga fino all'archiviazione di un massimo di 8 KB. Una volta che la pagina di indice ha raggiunto 8 KB, un nuovo inserimento di una riga singola causa la divisione della pagina di indice. Per una pagina interna, ciò significa che non è disponibile più spazio per aggiungere altri valori chiave e puntatori. Per una pagina foglia, ciò significa che, una volta incorporati tutti i record delta, la riga risulta troppo grande per la pagina. Le informazioni statistiche nell'intestazione di una pagina foglia indicano la quantità di spazio necessaria per consolidare i record delta. Queste informazioni vengono regolate quando un nuovo record delta viene aggiunto.
Un'operazione di divisione è effettuata in due passaggi atomici. Nel diagramma seguente, si supponga che una pagina foglia causi una divisione perché viene inserita una chiave di valore 5 e che esista una pagina non foglia che punta alla fine dell’attuale pagina del livello foglia (valore della chiave 4).

Passaggio 1: assegnare due nuove pagine P1 e P2 e suddividere le righe dalla pagina P1 precedente in queste nuove pagine, inclusa la riga appena inserita. Un nuovo slot nella tabella di mapping della pagina viene usato per archiviare l'indirizzo fisico della pagina P2. Le pagine P1 e P2 non sono ancora accessibili alle operazioni simultanee. Inoltre, il puntatore logico da P1 a P2 viene impostato. Quindi, per modificare il puntatore dal vecchio P1 al nuovo P1, aggiornare la tabella di mapping della pagina in un unico passaggio atomico.
Passaggio 2: La pagina interna punta a P1, ma non esiste alcun puntatore diretto da una pagina interna a P2.
P2 è raggiungibile solo tramite P1. Per creare un puntatore da una pagina non foglia a P2, allocare una nuova pagina non foglia (pagina di indice interno), copiare tutte le righe dalla pagina foglia precedente e aggiungere una nuova riga in modo che punti a P2. Una volta terminata questa operazione, eseguita in un unico passaggio atomico, aggiornare la tabella di mapping della pagina per modificare il puntatore dalla pagina non foglia precedente alla nuova pagina non foglia.
Pagina di unione
Quando un'operazione DELETE restituisce una pagina con dimensioni inferiori al 10% della pagina massima (8 KB) o con una singola riga, tale pagina viene unita a una pagina contigua.
Quando viene eliminata una riga da una pagina, viene aggiunto un record delta per l'eliminazione. Viene inoltre effettuato un controllo per determinare se la pagina di indice (pagina non foglia) è idonea per l'unione. Questo controllo verifica se lo spazio rimanente dopo l'eliminazione della riga è inferiore al 10% delle dimensioni massime della pagina. Se è idoneo, la fusione viene eseguita in tre passaggi atomici.
Nell'immagine seguente si supponga che un'operazione DELETE elimini il valore chiave 10.

Passaggio 1: viene creata una pagina delta che rappresenta il valore di chiave 10 (triangolo blu) e il suo puntatore nella pagina non foglia Pp1 è impostato per la nuova pagina delta. Inoltre, viene creata una speciale pagina merge-delta (triangolo verde), collegata in modo che punti alla pagina delta. In questa fase le due pagine (pagina delta e pagina delta di tipo unione) non sono visibili per le transazioni simultanee. In un unico passaggio atomico, il puntatore alla pagina al livello foglia P1 nella tabella di mappatura delle pagine viene aggiornato per puntare alla pagina merge-delta. Dopo questo passaggio, la voce relativa al valore chiave 10 in Pp1 punta alla pagina delta dell'unione.
Passaggio 2: La riga che rappresenta il valore chiave 7 nella pagina non foglia Pp1 deve essere rimossa e la voce per il valore chiave 10 deve essere aggiornata in modo che punti a P1. A tale scopo, viene allocata una nuova pagina non foglia Pp2 e vengono copiate tutte le righe a partire da Pp1, tranne la riga che rappresenta il valore chiave 7. La riga per il valore chiave 10 viene quindi aggiornata per puntare alla pagina P1. Una volta fatto questo, in un'unica operazione atomica, la voce della tabella di mappatura delle pagine che punta a Pp1 viene aggiornata in modo che punti a Pp2.
Pp1 non è più raggiungibile.
Passaggio 3: le pagine a livello foglia P2 e P1 vengono unite e le pagine delta rimosse. A tale scopo, viene allocata una nuova pagina P3 e le righe da P2 a P1 sono unite. Le modifiche apportate alla pagina delta sono incluse nella nuova pagina P3. Quindi, in un unico passaggio atomico, la voce della tabella di mappatura della pagina che punta alla pagina P1 viene aggiornata in modo che punti alla pagina P3.
Considerazioni sulle prestazioni per gli indici non cluster ottimizzati per la memoria
Le prestazioni di un indice non cluster sono migliori rispetto agli indici hash durante l'esecuzione di query su una tabella ottimizzata per la memoria con predicati di disuguaglianza.
Una colonna di una tabella ottimizzata per la memoria può far parte sia di un indice hash che di un indice non cluster.
Quando in un indice non cluster una colonna chiave contiene molti valori duplicati, le prestazioni per le operazioni di aggiornamento, inserimento ed eliminazione potrebbero risultare ridotte. Un modo per migliorare le prestazioni in questa situazione consiste nell'aggiungere una colonna che abbia una migliore selettività nella chiave di indice.
Metadati di indice
Per esaminare i metadati dell'indice, ad esempio definizioni di indice, proprietà e statistiche dei dati, usare le viste di sistema seguenti:
- sys.objects
- sys.indexes
- sys.index_columns
- sys.columns
- sys.types
- sys.partitions
- sys.internal_partitions
- sys.dm_db_index_usage_stats
- sys.dm_db_partition_stats
- sys.dm_db_index_operational_stats
Le viste precedenti si applicano a tutti i tipi di indice. Per gli indici columnstore, usare anche le viste seguenti:
- sys.column_store_row_groups
- sys.column_store_segments
- sys.column_store_dictionaries
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
Tutte le colonne di un indice columnstore vengono archiviate nei metadati come colonne incluse. L'indice columnstore non contiene colonne chiave.
Per gli indici nelle tabelle ottimizzate per la memoria, usare anche le viste seguenti:
- sys.hash_indexes
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.memory_optimized_tables_internal_attributes
Contenuti correlati
- CREATE INDEX (Transact-SQL)
- Ottimizzare la manutenzione dell'indice per migliorare le prestazioni delle query e ridurre il consumo di risorse
- Tabelle e indici partizionati
- Indici in tabelle con ottimizzazione per la memoria
- Panoramica sugli indici columnstore
- Indici per le colonne calcolate
- Ottimizzare gli indici non clusterizzati usando i suggerimenti per gli indici mancanti