Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
SQL Server Distributed Replay non è disponibile con SQL Server 2022 (16.x) e versioni successive.
La funzionalità Riesecuzione distribuita di Microsoft SQL Server agevola la valutazione dell'impatto dei futuri aggiornamenti di SQL Server. È possibile usarla anche per valutare l'impatto degli aggiornamenti hardware e del sistema operativo e dell'ottimizzazione di SQL Server.
La funzione Distributed Replay è deprecata in SQL Server 2022
Distributed Replay è deprecato a partire da SQL Server 2022 (16.x), come indicato in Funzionalità deprecate del motore di database in SQL Server 2022 (16.x). Riesecuzione distribuita ha una dipendenza da SQL Server Native Client (SNAC), rimossa da SQL Server 2022 (16.x). Questa modifica è documentata in Criteri di supporto per SQL Server Native Client. Inoltre, Riproduzione distribuita si basa su file
Il controller di Riesecuzione distribuita è stato rimosso dal programma di installazione di SQL Server 2022 (16.x) e il client Riesecuzione distribuita non è più disponibile in SQL Server Management Studio (SSMS) a partire dalla versione 18. Per ottenere il controller di Riesecuzione distribuita, è necessario installare SQL Server 2019 (15.x) o una versione precedente. Per ottenere il Distributed Replay Client, è necessario installare SSMS 17.9.1.
Per i clienti con SQL Server 2022 (16.x), è invece possibile usare le utilità RML (Replay Markup Language), che include ostress per riprodurre un carico di lavoro.
Vantaggi di Distributed Replay
Analogamente a SQL Server Profiler, è possibile usare Riesecuzione distribuita per riprodurre una traccia acquisita su un ambiente di testing aggiornato. Diversamente da SQL Server Profiler, Riesecuzione distribuita non si limita alla riproduzione del carico di lavoro da un singolo computer,
Riesecuzione distribuita offre una soluzione più scalabile rispetto a SQL Server Profiler. Con Distributed Replay è possibile riprodurre un carico di lavoro da più computer e simulare in modo migliore un carico di lavoro di importanza critica.
La funzionalità di Riesecuzione Distribuita può utilizzare più computer per riprodurre dati di traccia e simulare un carico di lavoro critico. Utilizzare Distributed Replay per testare la compatibilità delle applicazioni e le prestazioni o per pianificare la capacità.
Quando utilizzare Riesecuzione distribuita
SQL Server Profiler e Riesecuzione distribuita offrono alcune funzionalità sovrapposte.
È possibile usare SQL Server Profiler per riprodurre una traccia acquisita su un ambiente di testing aggiornato. È inoltre possibile analizzare i risultati di riproduzione per cercare possibili incompatibilità funzionali e di prestazioni. Tuttavia, SQL Server Profiler può riprodurre solo un carico di lavoro da un singolo computer. Quando si riproduce un'applicazione OLTP intensiva che ha molte connessioni simultanee attive o una velocità effettiva elevata, SQL Server Profiler può costituire un collo di bottiglia per le risorse.
Riesecuzione distribuita offre una soluzione più scalabile rispetto a SQL Server Profiler. Utilizza Distributed Replay per riprodurre un carico di lavoro da più computer e simulare meglio un carico di lavoro di importanza critica.
Nella tabella seguente viene descritto quando utilizzare ciascuno strumento.
| Strumento | Usa quando |
|---|---|
| SQL Server Profiler (strumento di analisi per SQL Server) | Si desidera utilizzare il meccanismo di riproduzione convenzionale in un singolo computer. In particolare, sono necessarie funzionalità di debug riga per riga, ad esempio i comandi Passaggio, Esegui fino al cursore e Imposta/Rimuovi punto di interruzione. Vuoi riprodurre una traccia di Analysis Services. |
| Riesecuzione distribuita | Si desidera valutare la compatibilità delle applicazioni. Si desidera, ad esempio, testare scenari di aggiornamento di SQL Server e del sistema operativo, gli aggiornamenti hardware o l'ottimizzazione degli indici. La concorrenza nella traccia acquisita è talmente elevata che un singolo client di riproduzione non è in grado di simularla in modo appropriato. |
Concetti di Riesecuzione Distribuita
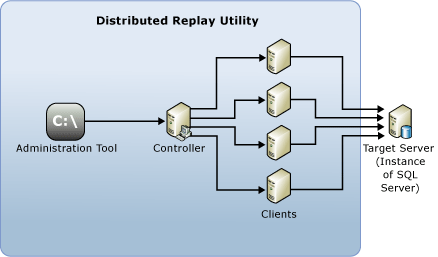
I componenti seguenti costituiscono l'ambiente di Distributed Replay:
Strumento di amministrazione di Riesecuzione distribuita: un'applicazione console, DReplay.exe, usata per comunicare con il controller di Riesecuzione distribuita. Utilizzare lo strumento di amministrazione per controllare la riproduzione distribuita.
Controller di Riesecuzione distribuita: un computer che esegue il servizio Windows denominato controller di Riesecuzione distribuita di Microsoft SQL Server. Il controller di Distributed Replay orchestra le azioni dei client di Distributed Replay. In ogni ambiente di Riesecuzione distribuita può essere presente una sola istanza del controller.
Client di Riesecuzione Distribuita: uno o più computer (fisici o virtuali) che eseguono il servizio Windows chiamato Client di Riesecuzione Distribuita di Microsoft SQL Server. I client di Replay Distribuito lavorano insieme per simulare carichi di lavoro in un'istanza di SQL Server. In ogni ambiente di Riesecuzione distribuita possono essere presenti uno o più client.
Server di destinazione: un'istanza di SQL Server che i client di Distributed Replay possono usare per riprodurre i dati di traccia. È consigliabile posizionare il server di destinazione in un ambiente di testing.
Distributed Replay Administration Tool, Controller e Client possono essere installati in computer diversi o sullo stesso computer. Sullo stesso computer può essere in esecuzione una sola istanza del servizio Distributed Replay Controller o Client.
Nella figura seguente viene mostrata l'architettura fisica di Riesecuzione distribuita di Microsoft SQL Server:
Attività di Riesecuzione Distribuita
| Descrizione dell'attività | Articolo |
|---|---|
| Viene descritto come configurare Distributed Replay. | Configurare Riesecuzione distribuita |
| Viene descritto come preparare i dati di traccia di input. | Preparare i dati di traccia di input |
| Descrive come riprodurre i dati di traccia. | Riavvia i dati di tracciamento |
| Viene descritto come rivedere i risultati dei dati di traccia di Distributed Replay. | Rivedere i risultati del replay |
| Viene descritto come usare lo strumento di amministrazione per avviare, monitorare e annullare operazioni nel controller. | Opzioni della riga di comando dello Strumento di Amministrazione (Utilità di Riesecuzione Distribuita) |
Requisiti
Prima di usare la funzionalità Riesecuzione distribuita è bene considerare i requisiti del prodotto indicati in questo argomento.
Requisiti della traccia di input
Affinché possano essere riprodotti correttamente, i dati di traccia devono soddisfare i requisiti per la versione e il formato e contenere le colonne e gli eventi necessari.
Versioni del tracciamento di input
Riesecuzione distribuita supporta dati di traccia di input raccolti nelle versioni di SQL Server seguenti:
- SQL Server 2019 (15.x)
- SQL Server 2017 (14.x) (aggiornamento cumulativo 1 e versioni successive - vedere versioni build di SQL Server 2017)
- SQL Server 2016 (13.x)
- SQL Server 2014 (12.x)
- SQL Server 2012 (11.x)
- SQL Server 2008 R2 (10.50.x)
- SQL Server 2008 (10.0.x)
- SQL Server 2005 (9.x)
Formati della traccia di input
I dati di traccia di input possono utilizzare uno dei formati seguenti:
Singolo file di traccia con estensione
.trc.Un insieme di file di traccia di rollover che seguono la convenzione di denominazione dei file di rollover, ad esempio
<TraceFile>.trc,<TraceFile>_1.trc,<TraceFile>_2.trc,<TraceFile>_3.trc, ...<TraceFile>_n.trc.
Eventi e colonne della traccia di input
I dati di traccia di input devono contenere colonne ed eventi specifici, che devono essere rieseguiti da Distributed Replay. Il modello TSQL_Replay in SQL Server Profiler contiene tutte le colonne e tutti gli eventi necessari, oltre a informazioni aggiuntive. Per altre informazioni sul modello, vedere Requisiti per la riproduzione.
Avviso
Se non si usa il modello TSQL_Replay per acquisire i dati di traccia di input o se i requisiti della traccia di input non sono soddisfatti, è possibile che si verifichino risultati di riproduzione imprevisti.
È inoltre possibile creare un modello di traccia personalizzato e utilizzarlo per riprodurre eventi con Riesecuzione distribuita, purché contenga gli eventi seguenti:
- Accesso di verifica
- Disconnessione di controllo
- Connessione Esistente
- Parametro di uscita RPC
- RPC:Completed
- RPC:Avvio
- SQL:BatchCompleted
- SQL:BatchStarting
Se si utilizzano cursori lato server, sono necessari anche gli eventi seguenti:
- ChiusuraCursore
- CursorExecute
- CursorOpen
- CursorPrepare
- CursorUnprepare
Se si riproducono istruzioni SQL preparate sul lato server, sono necessari anche gli eventi seguenti:
- Esegui istruzione SQL preparata
- Prepara SQL
Tutti i dati di traccia di input devono contenere le colonne seguenti:
- Classe evento
- Sequenza di eventi
- Dati di testo
- Nome dell'applicazione
- Nome utente
- Nome del database
- ID del database
- Nome dell'Host
- Dati binari
- Sistema Pubblico di Identità Digitale (SPID)
- Ora di avvio
- Ora di Fine
- IsSystem
Combinazioni di traccia di input e server di destinazione supportate
Nella tabella seguente sono elencate le versioni supportate dei dati di traccia e, per ciascuna di esse, sono indicate le versioni supportate di SQL Server su cui è possibile riprodurre i dati.
| Versione dei dati di traccia di input | Versioni supportate di SQL Server per l'istanza del server di destinazione |
|---|---|
| SQL Server 2005 (9.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 (10.0.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 R2 (10.50.x) | SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2012 (11.x) | SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2014 (12.x) | SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2016 (13.x) | SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2017 (14.x) | SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2019 (15.x) | SQL Server 2019 (15.x) |
Requisiti per il sistema operativo
I sistemi operativi supportati per l'esecuzione dello strumento di amministrazione e dei servizi client e del controller sono gli stessi dell'istanza di SQL Server. Per altre informazioni sui sistemi operativi supportati per l'istanza di SQL Server, vedere Requisiti hardware e software per SQL Server 2016 e SQL Server 2017.
Le funzionalità di Riesecuzione distribuita sono supportate sia in sistemi operativi x86 che x64. Per i sistemi operativi basati su x64, è supportata solo la modalità Windows on Windows (WOW).
Limitazioni relative all'installazione
In ogni computer può essere installata una sola istanza di ogni funzionalità di Riesecuzione distribuita. Nella tabella seguente viene indicato il numero di installazioni consentito per ogni funzionalità in un singolo ambiente di Riesecuzione distribuita.
| Funzionalità di Riesecuzione distribuita | Numero massimo di installazioni per ambiente di riproduzione |
|---|---|
| Servizio di controller del SQL Server per la riesecuzione distribuita | 1 |
| Servizio client di Riesecuzione distribuita di SQL Server | 16 (computer fisici o virtuali) |
| Strumento di amministrazione | Illimitato |
Nota
Benché sia possibile installare solo un'istanza dello strumento di amministrazione in ogni computer, è possibile avviare più istanze dello strumento di amministrazione. I comandi eseguiti da più strumenti di amministrazione vengono risolti in base all'ordine di ricezione.
Provider di accesso ai dati
Riesecuzione distribuita supporta solo il provider di accesso ai dati ODBC di SQL Server Native Client.
Requisiti di preparazione del server di destinazione
È consigliabile posizionare il server di destinazione in un ambiente di testing. Per riprodurre dati di traccia su un'istanza di SQL Server diversa rispetto a quella in cui sono stati registrati in origine, verificare che nel server di destinazione siano state effettuate i passaggi seguenti:
Tutti gli account di accesso e gli utenti contenuti nei dati di traccia devono essere presenti nello stesso database nel server di destinazione.
Tutti gli account di accesso e gli utenti presenti nel server di destinazione devono disporre delle stesse autorizzazioni di cui disponevano nel server originale.
È consigliabile che gli ID di database nella destinazione e nell'origine siano uguali. Tuttavia, se non sono uguali, è possibile effettuare una corrispondenza in base a DatabaseName, se presente nella traccia.
Il database predefinito per ogni account di accesso contenuto nei dati di traccia deve essere impostato (nel server di destinazione) sul rispettivo database di destinazione dell'account di accesso. Si supponga, ad esempio, che i dati di traccia da riprodurre contengano attività per l'account di accesso Frednel database Fred_Db nell'istanza originale di SQL Server. Di conseguenza, nel server di destinazione il database predefinito per l'account di accesso Freddeve essere impostato sul database corrispondente a Fred_Db , anche se il nome del database è diverso. Per impostare il database predefinito del login, utilizzare la stored procedure di sistema
sp_defaultdb.
La riproduzione degli eventi associati ad account di accesso mancanti o non corretti genera errori di riproduzione, ma l'operazione non viene interrotta.