Panoramica dei cubi OLAP di Service Manager per l'analisi avanzata
In Service Manager i dati presenti nel data warehouse possono essere consolidati da varie origini. Viene presentato tramite Service Manager usando cubi di dati OLAP (Online Analytical Processing) predefiniti e personalizzati. In breve, l'analisi avanzata in Service Manager consiste nel pubblicare, visualizzare e modificare i dati del cubo, in genere in Microsoft Excel o Microsoft SharePoint. Excel viene utilizzato principalmente da solo per visualizzare e modificare i dati. SharePoint viene utilizzato principalmente come mezzo per la pubblicazione e la condivisione dei dati del cubo.
Service Manager include un data warehouse a livello di System Center. Di conseguenza, i dati di Operations Manager, Configuration Manager e Service Manager possono essere consolidati nel data warehouse, in cui è possibile usare facilmente più viste dati per ottenere tutte le informazioni desiderate. Questa è anche un'interfaccia in cui è possibile inserire i dati nello stesso data warehouse da origini personalizzate, come applicazioni SAP o applicazioni per le risorse umane di terze parti. Il consolidamento crea un modello di dati comuni e consente analisi approfondite per supportare la creazione di un data warehouse per l'intera infrastruttura IT aziendale al servizio della business intelligence e delle esigenze di reporting.
Quando i dati sono in un modello comune, è possibile manipolare le informazioni e disporre di definizioni comuni e di una comune tassonomia per l'intera azienda. Ciò si realizza tramite la distribuzione di cubi di dati OLAP e tramite l'accesso alle informazioni dai cubi, utilizzando strumenti standard come Excel e SharePoint. In questo modo gli utenti possono utilizzare le competenze già acquisite. È possibile controllare la definizione della logica di business in modo centralizzato. Ad esempio, è possibile definire gli indicatori di prestazione chiave, come le soglie di tempo per la soluzione di eventi imprevisti, e quali valori di soglia saranno verdi, gialli o rossi. È possibile controllare queste scelte in maniera centralizzata e consentire agli utenti di utilizzare i dati in modo semplice, avendo in più la definizione comune visualizzata nei loro report di Excel o nei loro dashboard di SharePoint.
Informazioni sui cubi OLAP di Service Manager
I cubi OLAP (Online Analytical Processing) sono una funzionalità di Service Manager che usa l'infrastruttura del data warehouse esistente per offrire funzionalità di business intelligence self-service agli utenti finali.
Un cubo OLAP è una struttura di dati che supera le limitazioni dei database relazionali, fornendo un'analisi rapida dei dati. I cubi consentono di visualizzare e sommare grandi quantità di dati, fornendo inoltre agli utenti l'accesso a tutti i punti dati per l'esecuzione di ricerche. In questo modo, i dati possono essere distribuiti, sezionati e sdiati in base alle esigenze per gestire la più ampia varietà di domande rilevanti per l'area di interesse di un utente.
I fornitori di software o gli sviluppatori IT con una conoscenza approfondita dei cubi OLAP possono creare Management Pack per definire cubi OLAP estendibili e personalizzabili basati sull'infrastruttura del data warehouse. Tali cubi vengono archiviati in SQL Server Analysis Services (SSAS). Gli strumenti per la business intelligence in modalità self-service, come Excel e SQL Server Reporting Services (SSRS), possono avere come destinazione tali cubi in SSAS, in modo da consentirne l'utilizzo per analizzare i dati da molteplici prospettive.
I database usati dalle aziende per archiviare tutti i record e le transazioni sono detti database OLTP (Online Transaction Processing). In genere questi database includono record che vengono inseriti uno per volta e che contengono moltissime informazioni che possono essere utilizzate dagli strateghi per prendere decisioni informate in merito alle loro attività aziendali. I database usati per archiviare i dati, tuttavia, non sono stati progettati per l'analisi. Il recupero di informazioni da questi database richiede quindi un impegno notevole in termini di tempo e prestazioni. I database OLAP sono database specializzati che consentono di estrarre queste informazioni di business intelligence dai dati.
I cubi OLAP possono essere considerati come l'ultima parte del puzzle di una soluzione di data warehousing. Un cubo OLAP, definito anche cubo multidimensionale o ipercubo, è una struttura di dati in SQL Server Analysis Services (SSAS) generata utilizzando i database OLAP per permettere un'analisi dei dati quasi istantanea. La topologia del sistema è illustrata nella figura seguente.
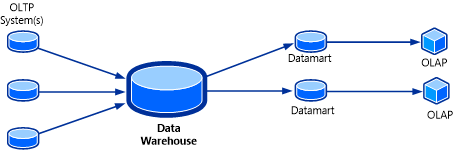
Una funzione utile di un cubo OLAP permette di contenere i dati del cubo in una forma aggregata. All'utente può sembrare che il cubo abbia le risposte in anticipo poiché le combinazioni di valori sono già precalcolate. Senza la necessità di eseguire query sul database OLAP di origine, il cubo può restituire quasi istantaneamente le risposte per una vasta gamma di domande.
L'obiettivo principale dei cubi OLAP di Service Manager è offrire ai fornitori di software o agli sviluppatori IT la possibilità di eseguire analisi quasi istantanee dei dati sia a scopo di analisi cronologica che di tendenza. Service Manager esegue questa operazione:
- Definire i cubi OLAP in Management Pack creati automaticamente in SSAS al momento della distribuzione del Management Pack.
- Gestire automaticamente il cubo senza intervento dell'utente, eseguendo attività quali elaborazione, partizionamento, traduzioni e localizzazione, nonché modifiche dello schema.
- Consentire agli utenti di utilizzare strumenti di business intelligence in modalità self-service, ad esempio Excel, per analizzare i dati da più prospettive.
- Salvare i report generati in Excel come riferimento futuro.
Per vedere come i cubi del data warehouse sono rappresentati nella console di Service Manager, passare all'area di lavoro Data Warehouse e selezionare Cubi.
Cubi OLAP di Service Manager
Nella figura seguente è mostrata un'immagine tratta da SQL Server Business Intelligence Development Studio (BIDS) che illustra le parti principali necessarie per i cubi OLAP. Queste parti sono l'origine dati, la vista dell'origine dati, i cubi e le dimensioni. Nelle sezioni riportate di seguito vengono descritte le parti del cubo OLAP e le azioni che gli utenti possono eseguire durante l'utilizzo di tale cubo.

Origine dati
Un'origine dati è l'origine di tutti i dati contenuti all'interno di un cubo OLAP. Un cubo OLAP consente di connettersi a un'origine dati per leggere ed elaborare dati non elaborati e per eseguire calcoli e aggregazioni per le misure associate. L'origine dati per tutti i cubi OLAP di Service Manager è costituita dai data mart, inclusi i data mart per Operations Manager e Configuration Manager. È necessario memorizzare le informazioni di autenticazione sull'origine dati in SQL Server Analysis Services (SSAS) per stabilire il corretto livello di autorizzazioni.
Vista origine dati
La vista origine dati (DSV) è una raccolta di viste che rappresentano la dimensione, il fatto e le tabelle outrigger dall'origine dati, ad esempio i data mart di Service Manager. La vista origine dati contiene tutte le relazioni tra tabelle, ad esempio le chiavi primarie e le chiavi esterne. In altre parole, la DSV specifica la modalità in cui il database SSAS eseguirà il mapping rispetto allo schema relazionale e fornisce un livello di astrazione al di sopra del database relazionale. Tramite questo livello di astrazione, è possibile definire le relazioni tra le tabelle del fatto e della dimensione, anche in assenza di una relazione all'interno del database relazionale di origine. Nella DSV è possibile inoltre definire calcoli denominati, misure personalizzate e nuovi attributi che potrebbero non esistere in forma nativa nello schema dimensionale del data warehouse. Ad esempio, un calcolo denominato che definisce un valore booleano per Incidents Resolved calcola il valore come true se lo stato di un evento imprevisto viene risolto o chiuso. Usando il calcolo denominato, Service Manager può quindi definire una misura per visualizzare informazioni utili, ad esempio la percentuale di eventi imprevisti risolti, il numero totale di eventi imprevisti risolti e il numero totale di eventi imprevisti che non vengono risolti.
Un altro esempio semplice di un calcolo denominato è ReleasesImplementedOnSchedule. Questo calcolo denominato offre un rapido controllo sullo stato di integrità del numero di record versione in cui la data effettiva di fine è inferiore o uguale alla data di fine pianificata.
Cubi OLAP
Un cubo OLAP è una struttura di dati che supera le limitazioni dei database relazionali, fornendo un'analisi rapida dei dati. I cubi OLAP possono visualizzare e sommare grandi quantità di dati fornendo anche agli utenti l'accesso ricercabile a qualsiasi punto dati in modo che i dati possano essere distribuiti, sezionati e sbattuti in base alle esigenze per gestire la più ampia varietà di domande rilevanti per l'area di interesse di un utente.
Dimensioni
Una dimensione in SSAS fa riferimento a una dimensione dal data warehouse di Service Manager. In Service Manager una dimensione equivale approssimativamente a una classe Management Pack. Ogni classe del Management Pack ha un elenco di proprietà, mentre ogni dimensione contiene un elenco di attributi nel quale ciascun attributo corrisponde a una proprietà in una classe. Le dimensioni consentono di filtrare, raggruppare ed etichettare i dati. Ad esempio, è possibile filtrare i computer in base al sistema operativo installato e raggruppare le persone in categorie per sesso o età. I dati possono quindi essere presentati in un formato in cui i dati vengono classificati naturalmente in queste gerarchie e categorie per consentire un'analisi più approfondita. Le dimensioni possono anche avere gerarchie naturali per consentire agli utenti di "eseguire il drill-down" a livelli di dettaglio più dettagliati. Ad esempio, la dimensione Data ha una gerarchia che può essere approfondita per Anno, quindi per Trimestre, per Mese, per Settimana e infine per Giorno.
Nella figura seguente viene illustrato un cubo OLAP che contiene le dimensioni Data, Area e Prodotto.
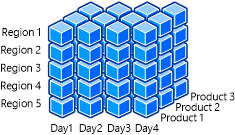
Ad esempio, i membri del team Microsoft potrebbero volere un riepilogo rapido e semplice delle vendite della console di gioco Xbox One nella versione applicabile. È possibile eseguire ulteriormente il drill down per ottenere le cifre di vendita relative a un periodo di tempo più specifico. Gli analisti aziendali potrebbero voler esaminare il modo in cui le vendite delle console Xbox One sono state influenzate dal lancio della nuova progettazione della console e di Kinect per Xbox One. Ciò consente di determinare le tendenze di vendita in corso e quali eventuali revisioni della strategia aziendale siano necessarie. Filtrando la dimensione Data, queste informazioni possono essere fornite e utilizzate rapidamente. Le funzioni di slicing e dicing dei dati sono attivate solo perché le dimensioni sono state progettate con attributi e dati che possono essere facilmente filtrati e raggruppati dal cliente.
In Service Manager tutti i cubi OLAP condividono un set comune di dimensioni. Tutte le dimensioni utilizzano come origine il data mart del data warehouse primario, anche negli scenari in cui sono presenti più data mart. Negli scenari con più data mart ciò potrebbe causare errori di chiave della dimensione durante l'elaborazione del cubo.
Gruppo di misure
Nella terminologia dei data warehouse, un gruppo di misure è lo stesso concetto di un fatto. Come i fatti contengono misure numeriche in un data warehouse, un gruppo di misure contiene misure per un cubo OLAP. Tutte le misure presenti in un cubo OLAP che derivano da una singola tabella di fatti in una vista origine dati possono essere considerate anch'esse come un gruppo di misure. Tuttavia, possono esistere delle istanze in cui vi saranno più tabelle dei fatti da cui derivano le misure in un cubo OLAP. Le misure dello stesso livello di dettaglio sono unite in un gruppo di misure. I gruppi di misure definiscono quali dati verranno caricati nel sistema, come verranno caricati e come verranno associati al cubo multidimensionale.
Ogni gruppo di misure contiene inoltre un elenco di partizioni che contengono i dati effettivi in sezioni separate, non sovrapposte. Inoltre, i gruppi di misure contengono una struttura di aggregazione che definisce i set di dati già riepilogati calcolati per ciascun gruppo di misure, al fine di migliorare le prestazioni per le query degli utenti.
Misure
Le misure sono i valori numerici che gli utenti vogliono filtrare, dadi, aggregare e analizzare; sono uno dei motivi fondamentali per cui si vogliono creare cubi OLAP usando l'infrastruttura di data warehousing. Tramite i servizi SSAS, è possibile generare cubi OLAP che applichino regole e calcoli aziendali al fine di formattare e visualizzare le misure in un formato personalizzato. La maggior parte del tempo dedicato allo sviluppo di un cubo OLAP viene impiegato per determinare e definire le misure che verranno visualizzate e la modalità con cui verranno calcolate.
Le misure sono valori che generalmente sono mappati a colonne numeriche in una tabella di fatti di un data warehouse, ma possono anche essere creati nella dimensione e degenerare attributi della dimensione. Tali misure sono i valori più importanti di un cubo OLAP che vengono analizzati e rappresentano l'interesse primario degli utenti finali che sfogliano il cubo OLAP. Un esempio di una misura che esiste nel data warehouse è ActivityTotalTimeMeasure. ActivityTotalTimeMeasure è una misura da ActivityStatusDurationFact che rappresenta l'ora in cui ogni attività è in un determinato stato. Il livello di dettaglio di una misura è costituito da tutte le dimensioni a cui fa riferimento. Ad esempio, il livello di dettaglio del fatto di relazione ComputerHostsOperatingSystem è costituito dalle dimensioni Computer e Sistema operativo.
Per consentire un'analisi più approfondita dei dati, in base alle misure vengono calcolate le funzioni di aggregazione. La funzione di aggregazione più comune è Sum. Una semplice query di un cubo OLAP, ad esempio, somma il tempo totale di tutte le attività In Progress. Altre funzioni comuni di aggregazione includono Min, Max e Count.
Dopo che i dati non elaborati sono stati processati in un cubo OLAP, gli utenti possono eseguire calcoli e query più complessi utilizzando espressioni MDX per definire proprie espressioni di misura o propri membri calcolati. MDX è lo standard di settore per l'esecuzione di query e l'accesso ai dati memorizzati nei sistemi OLAP. SQL Server non è stato progettato per funzionare con il modello di dati supportato dai database multidimensionali.
Drill-down
Quando un utente eseguire il drill-down nei dati di un cubo OLAP, esegue l'analisi dei dati a un diverso livello di riepilogo. Mentre l'utente esegue il drill-down, il livello di dettaglio dei dati cambia, permettendo di esaminare i dati a diversi livelli della gerarchia. Durante il drill-down degli utenti, passano dalle informazioni di riepilogo ai dati con uno stato attivo più ristretto. Di seguito sono riportati alcuni esempi di drill-down:
- Drill-down dei dati per ottenere informazioni demografiche sulla popolazione degli Stati Uniti, quindi drill-down nello Stato di Washington, quindi nell'area metropolitana di Seattle, poi nella città di Redmond e infine nella popolazione di Microsoft.
- Eseguire il drill-down dei dati di vendita per le console Xbox One per l'anno di calendario 2015, quindi il quarto trimestre dell'anno, il mese di dicembre, la settimana prima di Natale e infine la vigilia di Natale.
Drill-through
Quando gli utenti esegono il drill-through dei dati, vogliono visualizzare tutte le singole transazioni che hanno contribuito ai dati aggregati del cubo OLAP. In altre parole, l'utente può recuperare al livello inferiore di dettaglio i dati relativi al valore di una misura specificata. Ad esempio, quando vengono forniti i dati di vendita per un determinato mese e categoria di prodotti, è possibile eseguire il drill-through dei dati per visualizzare un elenco di ogni riga di tabella contenuta all'interno di tale cella di dati.
È comune confondere i termini drill-down e drill-through tra loro. La differenza principale tra di esse è che un drill-down opera su una gerarchia predefinita di dati, ad esempio USA, quindi in Washington, quindi in Seattle-within the OLAP cube. Un'attività drill-through passa direttamente al livello più basso di dettaglio dei dati e recupera una serie di righe dell'origine dati che è stata aggregata in un'unica cella.
Indicatore di prestazioni chiave
Un indicatore di prestazione chiave (KPI) permette alle aziende di stimare l'integrità dell'azienda e delle sue prestazioni misurandone i progressi verso gli obiettivi prefissati. Gli indicatori KPI sono metriche aziendali che possono essere definite per monitorare i progressi verso determinati obiettivi predefiniti. Un indicatore KPI ha un valore di destinazione e un valore effettivo, che rappresenta un obiettivo quantitativo fondamentale per il successo dell'organizzazione. Gli indicatori KPI vengono visualizzati in gruppi su una scorecard per mostrare l'integrità complessiva dell'azienda in uno snapshot rapido.
Un esempio di indicatore KPI è quello di completare tutte le richieste di modifica entro 48 ore. Un indicatore KPI consente di misurare la percentuale di richieste di modifica risolte entro tale periodo di tempo. È possibile creare dashboard per rappresentare visivamente gli indicatori KPI. Ad esempio, è possibile definire un valore di destinazione dell'indicatore KPI per il completamento di tutte le richieste di modifica entro 48 ore al 75%.
Partizioni
Una partizione è una struttura di dati che contiene alcuni o tutti i dati in un gruppo di misure. Ogni gruppo di misure è suddiviso in partizioni. Una partizione definisce un sottoinsieme di dati del fatto caricato nel gruppo di misure. SSAS Standard Edition consente solo una partizione per ogni gruppo di misure, mentre SSAS Enterprise Edition consente un gruppo di misure con più partizioni. Le partizioni sono una funzionalità trasparente per l'utente finale, ma hanno un impatto significativo sulle prestazioni e sulla scalabilità dei cubi OLAP. Tutte le partizioni di un gruppo di misure esistono sempre nello stesso database fisico.
Le partizioni consentono a un amministratore di gestire meglio un cubo OLAP e migliorare le prestazioni di un cubo OLAP. Ad esempio, è possibile rimuovere o rielaborare i dati di una partizione di un gruppo di misure senza influire sul resto del gruppo di misure. Quando si caricano nuovi dati in una tabella dei fatti, vengono interessate solo le partizioni che devono contenere nuovi dati.
Il partizionamento migliora anche le prestazioni di elaborazione e query dei cubi OLAP. SSAS può elaborare più partizioni in parallelo, in modo da rendere più efficiente l'utilizzo delle risorse della CPU e della memoria del server. Mentre esegue una query, SSAS recupera, elabora e aggrega anche i dati di più partizioni, solo le partizioni che contengono i dati rilevanti per una query vengono analizzate, riducendo così la quantità complessiva di input e output.
Un esempio di strategia di partizionamento consiste nell'inserimento dei dati delle tabelle dei fatti di ciascun mese in una partizione mensile. Alla fine di ciascun mese, tutti i nuovi dati vengono inseriti in una nuova partizione, ottenendo una naturale distribuzione dei dati con valori non sovrapposti.
Aggregazioni
Le aggregazioni in un cubo OLAP sono insiemi di dati già riepilogati. Sono analoghi a un'istruzione SQL SELECT con una clausola GROUP BY. SSAS può utilizzare tali aggregazioni nella risposta query, in modo da ridurre la quantità di calcoli necessari e restituire rapidamente le risposte. Le aggregazioni incorporate nel cubo OLAP riducono la quantità di aggregazioni create da SSAS nella fase di query. La creazione delle corrette aggregazioni consente di migliorare drasticamente le prestazioni delle query. Si tratta spesso di un processo in continua evoluzione per tutta la durata del cubo OLAP, con il progressivo cambiamento delle query e dell'utilizzo dello stesso.
In genere viene creato un insieme base di aggregazioni che verrà utilizzato per la maggior parte delle query inviate al cubo OLAP. Le aggregazioni vengono create per ciascuna partizione del cubo OLAP all'interno di un gruppo di misure. Quando viene creata un'aggregazione, alcuni attributi delle dimensioni vengono inclusi nel set di dati già riepilogati. Gli utenti possono effettuare rapidamente query dei dati su queste aggregazioni al momento di esplorare il cubo OLAP. Le aggregazioni devono essere progettate con attenzione, in quanto il numero di aggregazioni potenziali è molto elevato. Pertanto, la creazione di tutte le aggregazioni richiederebbe una quantità immensa di tempo e spazio di archiviazione.
Service Manager usa le due opzioni seguenti per la compilazione e la progettazione di aggregazioni nei cubi OLAP di Service Manager:
- Miglioramento delle prestazioni
- Ottimizzazione sulle statistiche di utilizzo
L'opzione Miglioramento delle prestazioni definisce la percentuale di aggregazioni create. Ad esempio, l'impostazione predefinita dell'opzione e l'utilizzo del valore suggerito del 30 percento comporta la creazione di aggregazioni capaci di migliorare le prestazioni del cubo OLAP di circa il 30 percento. Tuttavia, ciò non significa che verrà compilato il 30% delle possibili aggregazioni.
L'ottimizzazione basata sulle statistiche di utilizzo consente a SSAS di registrare le richieste di dati, in modo che, al momento dell'esecuzione di una query, le informazioni vengono immesse nel processo di progettazione dell'aggregazione. Quindi, SSAS rivede i dati e suggerisce le aggregazioni da creare per ottenere il miglioramento massimo stimato delle prestazioni.
Partizionamento del cubo di Service Manager
Ogni gruppo di misure in un cubo è diviso in partizioni e ciascuna partizione definisce una porzione di dati delle tabelle dei fatti caricati in un gruppo di misure. SQL Server Analysis Services (SSAS) in SQL Server edizione Standard consente una sola partizione per gruppo di misure, mentre nella edizione Enterprise sono consentite più partizioni. Le partizioni sono completamente trasparenti all'utente finale, ma hanno un notevole impatto sulle prestazioni e sulla scalabilità. Ad esempio, le partizioni possono essere elaborate separatamente e in parallelo. Possono avere progettazioni di aggregazioni diverse. In un gruppo di misure è possibile rielaborare una partizione senza modificare tutte le altre partizioni. Inoltre, SSAS analizza automaticamente solo le partizioni che contengono i dati necessari per una query, consentendo così di migliorare notevolmente le prestazioni delle query.
Il partizionamento dei cubi avviene in ogni processo di manutenzione eseguito sul data warehouse, che si svolge ogni ora per impostazione predefinita. Il modulo di processo specifico che viene eseguito è denominato ManageCubePartitions. Viene sempre eseguito dopo il passaggio CreateMartPartitions. I dati sulle dipendenze vengono archiviati nella tabella infra.moduletriggercondition.
La principale libreria di collegamento dinamico (DLL), che gestisce il partizionamento, si trova nella DLL utilità warehouse, Microsoft.EnterpriseManagement.Warehouse.Utility, nella classe PartitionUtil. In particolare, esiste un metodo ManagePartitions() nella classe che gestisce tutta la manutenzione della partizione. La DLL di manutenzione del data warehouse, Microsoft.EnterpriseManagement.Warehouse.Maintenance, e la DLL di elaborazione analitica online (OLAP) del data warehouse, Microsoft.EnterpriseManagement.Warehouse.Olap, richiamano entrambe Microsoft.EnterpriseManagement.Warehouse.Utility per gestire le partizioni durante la manutenzione e la distribuzione dei cubi. Ecco perché la gestione effettiva delle partizioni avviene nella DLL utilità warehouse comune per evitare la duplicazione di logica o codice.
La funzione di manutenzione del partizionamento dei cubi esegue le attività seguenti:
- Creare partizioni
- Eliminazione di partizioni
- Aggiornamento dei limiti delle partizioni
Per questa attività viene letta la tabella SQL (Structured Query Language) etl.TablePartition per determinare tutte le partizioni dei fatti create in precedenza per un gruppo di misure. Si verifica quanto segue:
- Avviare l'elaborazione del cubo per ogni gruppo di misure presente nel cubo
- Ottenere tutte le partizioni dalla tabella etl.TablePartition per il gruppo di misure
- Eliminare tutte le partizioni esistenti nel gruppo di misure, ma che non sono presenti nella tabella etl.TablePartition
- Aggiungere le nuove partizioni create in precedenza e che esistono solo nella tabella etl.TablePartition
- Aggiornare tutte le partizioni che potrebbero essere state modificate facendo corrispondere ogni partizione a RangeStartDate e RangeEndDate nella tabella etl.TablePartition
Tenere presente quanto segue sull'elaborazione del cubo:
- Solo i gruppi di misure destinati a fatti contengono più partizioni in SQL Server edizione Standard. Per impostazione predefinita, tutti i gruppi di misure e le dimensioni contengono solo una partizione. Pertanto, la partizione non ha condizioni limite.
- I limiti di una partizione sono definiti da un'associazione di query basata su chiavi di dati che corrispondono alle chiavi di dati relative alla partizione di fatti nella tabella etl.TablePartition.
Distribuzione del cubo OLAP di Service Manager
La distribuzione di cubi OLAP (Online Analytical Processing) usa l'infrastruttura di distribuzione di Service Manager per creare cubi OLAP nel database di SQL Server Analysis Services (SSAS).
Per riassumere, un elemento distribuibile restituisce un deployer con una raccolta di risorse che sono serializzate e che vengono utilizzate per creare il cubo OLAP nel database SSAS. Per i cubi OLAP, il nome dell'oggetto distribuibile è CubeDeployable per l'elemento SystemCenterCube e CubeExtensionDeployable per l'elemento CubeExtension. Il deployer per entrambi gli elementi è CubeDeployer.
La tabella dbo.Selector nel database DWStagingAndConfig contiene una voce per entrambi gli elementi del Management Pack SystemCenterCube e CubeExtension. Il motore di distribuzione utilizza questi metadati nei casi in cui sia necessario un'ulteriore elaborazione della distribuzione per un elemento Management Pack quando tale Management Pack viene importato nel data warehouse tramite il processo MPSync.
Le distribuzioni utilizzano l'API di Analysis Management Objects (AMO) per creare e modificare tutti i componenti del cubo nel database SSAS. In particolare, AMO in modalità disconnessa viene usato perché l'elemento CubeDeployable non avrà una connessione al database SSAS. L'uso di AMO in modalità disconnessa permette di creare l'intera struttura di oggetti AMO senza la necessità di instaurare una connessione al server. Service Manager serializza quindi la gerarchia degli oggetti come risorse di flusso e le collega all'oggetto deployer passato all'infrastruttura di distribuzione. L'oggetto deployer viene quindi deserializzato, instaura una connessione al database SSAD e crea gli oggetti, inviando le richieste appropriate al server.
Solo gli oggetti principali possono essere serializzati. In AMO vengono considerati oggetti principali le classi che rappresentano un oggetto completo come entità completa e non come parte di un altro oggetto. Ad esempio, gli oggetti principali includono Server, Cube e Dimension, che sono tutte entità autonome. DimensionAttribute, tuttavia, non è un oggetto principale perché può essere creato solo come parte di un oggetto principale padre di Dimension. DimensionAttribute, pertanto, è un oggetto secondario. La progettazione dei cubi OLAP è incentrata sulla creazione di tutti gli oggetti principali che sono necessari per i cubi e di tutti gli oggetti secondari dipendenti. Questi oggetti principali sono gli oggetti che verranno serializzati e, infine, deserializzati prima che gli oggetti vengano creati nel database SSAS.
Le risorse che contengono gli oggetti principali devono essere create in un ordine specifico per la distribuzione al fine di completare correttamente e soddisfare i requisiti di dipendenza degli elementi del cubo OLAP. Nei due elenchi seguenti sono illustrate le sequenze di distribuzione, rispettivamente per gli elementi SystemCenterCube e CubeExtension:
- elementi DataSourceView
- elementi dimensione
- elemento dimensione data
- elemento cubo
- elementi DataSourceView
- elemento cubo
Elaborazione del cubo OLAP di Service Manager
Quando è stato distribuito un cubo OLAP (Online Analytical Processing) e tutte le relative partizioni sono state create, è pronto per essere elaborato in modo che sia visualizzabile. L'elaborazione di un cubo è il passaggio finale dopo l'esecuzione di estrazione, trasformazione e caricamento (ETL). La procedura si svolge nel modo seguente:
- Estrazione: vengono estratti i dati dal sistema di origine
- Trasformazione: vengono applicate le funzioni per conformare i dati a uno schema dimensionale standard
- Caricamento: i dati vengono caricati nel data mart per l'utilizzo
- Processo: i dati vengono caricati dal data mart al cubo OLAP per l'esplorazione
L'elaborazione di un cubo OLAP ha luogo quando sono calcolate tutte le aggregazioni del cubo e il cubo viene caricato con queste aggregazioni e questi dati. Vengono lette le tabelle di dimensioni e fatti, quindi i dati vengono calcolati e caricati nel cubo. Quando si progetta un cubo OLAP, è opportuno considerare con attenzione l'elaborazione, dato l'effetto potenzialmente significativo che tale elaborazione potrebbe avere in un ambiente di produzione, in cui potrebbero esistere milioni di record. Un processo completo di tutte le partizioni in un ambiente di questo tipo potrebbe richiedere da giorni a settimane, che potrebbero rendere inutilizzabile l'infrastruttura e i cubi di Service Manager agli utenti finali. È consigliabile disabilitare la pianificazione dell'elaborazione di tutti i cubi che non vengono usati per ridurre il sovraccarico nel sistema.
L'elaborazione di un cubo OLAP è costituita da due operazioni distinte:
- Elaborazione della dimensione
- Elaborazione di una partizione
Ogni cubo OLAP ha un processo di elaborazione corrispondente nella console di Service Manager e viene eseguito in base a una pianificazione configurabile dall'utente. Ciascun tipo di attività di elaborazione è descritto nelle sezioni riportate di seguito.
Elaborazione della dimensione
Ogni volta che al database SQL Server Analysis Server (SSAS) si aggiunge una nuova dimensione, è necessario eseguire un'elaborazione completa sulla dimensione in modo che sia in uno stato completamente elaborato. Dopo l'elaborazione di una dimensione, tuttavia, non esiste alcuna garanzia che venga elaborata di nuovo quando viene elaborato un altro cubo destinato alla stessa dimensione. La rielaborazione automatica della dimensione impedisce a Service Manager di rielaborare ogni dimensione per ogni cubo. Ciò vale soprattutto se la dimensione è stata elaborata di recente, perché è improbabile che esistano nuovi dati che non sono ancora stati elaborati. Per ottimizzare l'efficienza di elaborazione, è presente una classe singleton, definita nel Management Pack Microsoft.SystemCenter.Datawarehouse.OLAP.Base, denominata Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval. Di seguito è riportato un esempio di questa classe:
<!-- This singleton class defines the minimum interval of time in minutes that must elapse before a shared dimension is reprocessed. -->
<ClassType ID="Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval" Accessibility="Public" Abstract="false" Base="AdminItem!System.AdminItem" Singleton="true">
<Property ID="IntervalInMinutes" Type="int" Required="true" DefaultValue="60"/>
</ClassType>
Questa classe singleton contiene una proprietà, IntervalInMinutes, che descrive la frequenza con cui elaborare una dimensione. Per impostazione predefinita, questa proprietà è impostata su 60 minuti. Ad esempio, se una dimensione è stata elaborata alle 3:05 e un altro cubo destinato alla stessa dimensione viene elaborato alle 3:45, la dimensione non verrà rielaborata. Uno svantaggio di questo approccio è la maggiore probabilità di errori nelle chiavi dimensione. Un meccanismo di riprova gestisce gli errori delle chiavi dimensione per rielaborare la dimensione e quindi la partizione del cubo. Per altre informazioni sugli errori di elaborazione, vedere la sezione "Problemi comuni relativi al debug e alla risoluzione dei problemi".
Quando una dimensione è stata completamente elaborata, viene eseguita l'elaborazione incrementale con ProcessUpdate . L'unica altra volta in cui viene eseguito ProcessFull è quando cambia lo schema di una dimensione poiché la dimensione ritorna a uno stato non elaborato. Tenere presente che se ProcessFull viene eseguito su una dimensione, tutti i cubi interessati e le relative partizioni saranno presenti in uno stato non elaborato e dovranno essere elaborati completamente alla successiva esecuzione pianificata.
Elaborazione di una partizione
L'elaborazione delle partizioni deve essere considerata attentamente perché la rielaborazione di una partizione di grandi dimensioni è lenta e utilizza molte risorse CPU nel server che ospita SSAS. In genere l'elaborazione di una partizione richiede più tempo rispetto all'elaborazione di una dimensione. A differenza dell'elaborazione di una dimensione, l'elaborazione di una partizione non ha effetti collaterali su altri oggetti. Gli unici due tipi di elaborazione eseguiti nei cubi OLAP di System Center - Service Manager sono ProcessFull e ProcessAdd.
In modo simile alle dimensioni, la creazione di nuove partizioni in un cubo OLAP richiede un'attività ProcessFull per la partizione, in modo che sia in uno stato interrogabile. Dato che un'attività ProcessFull è un'operazione dispendiosa, la si dovrebbe eseguire solo quando necessario, ad esempio quando si crea una partizione o quando viene aggiornata una riga. Negli scenari in cui sono state aggiunte righe e nessuna riga è stata aggiornata, Service Manager può eseguire un'attività ProcessAdd. A tale scopo, Service Manager usa filigrane e altri metadati. In particolare, le tabelle etl.cubepartition ed etl.tablepartition vengono interrogate per determinare il tipo di elaborazione da eseguire.
Il diagramma seguente illustra in che modo Service Manager determina il tipo di elaborazione da eseguire in base ai dati della filigrana.
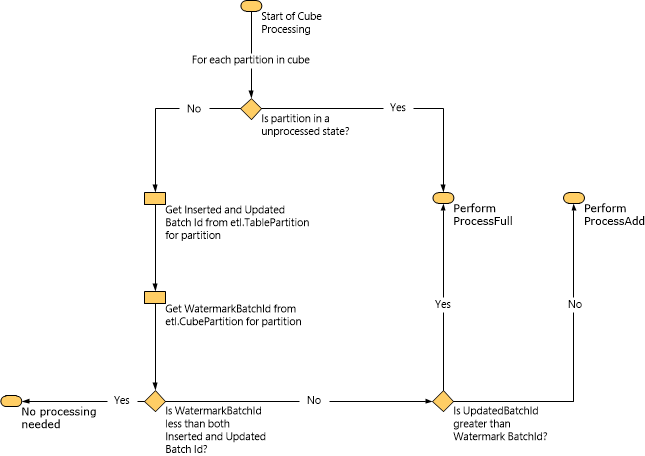
Quando viene eseguita un'attività ProcessAdd, Service Manager limita l'ambito della query usando filigrane. Ad esempio, se il valore InsertedBatchId è 100 e il valore WatermarkBatchId è 50, la query carica i dati soltanto dal data mart in cui InsertedBatchId è maggiore di 50 e minore di 100.
Infine, è importante notare che Service Manager non supporta l'elaborazione manuale dei cubi OLAP usando SSAS o Business Intelligence Development Studio. L'elaborazione di cubi all'esterno dei metodi forniti in System Center - Service Manager, inclusa la console di Service Manager e i cmdlet di Service Manager, non aggiornerà le tabelle limite. È quindi possibile che si verifichino problemi di integrità dei dati. Se il cubo è stato elaborato accidentalmente manualmente, una possibile soluzione alternativa consiste nell'annullare l'elaborazione manuale del cubo OLAP nello stesso modo. Quindi, alla successiva elaborazione del cubo, Service Manager eseguirà automaticamente un'attività ProcessFull perché le partizioni saranno in uno stato non elaborato. Verranno aggiornate correttamente tutte le soglie e i metadati in modo da risolvere eventuali problemi di integrità dei dati.
Gestire cubi OLAP di Service Manager
Nelle sezioni seguenti vengono descritte le procedure ottimali per la manutenzione dei cubi Online Analytical Processing (OLAP).
Rielaborare periodicamente le dimensioni di Analysis Services
Le procedure consigliate per SQL Server Analysis Services (SSAS) raccomandano di elaborare completamente e periodicamente le dimensioni di SSAS. La completa elaborazione periodica delle dimensioni ricostruisce gli indici e ottimizza l'archiviazione dei dati multidimensionali, migliorando così le prestazioni delle query e dei cubi che potrebbero peggiorare nel tempo. Questa procedura è simile a alla deframmentazione periodica del disco rigido di un computer.
Tuttavia, una rielaborazione completa delle dimensioni di SSAS comporta uno svantaggio: tutti i cubi OLAP coinvolti diventano non elaborati e pertanto devono anch'essi essere elaborati completamente per ripristinarne lo stato in cui sia possibile eseguire le query. Service Manager non elabora in modo esplicito le dimensioni di SSAS. Pertanto, è necessario decidere quando eseguire questa attività di manutenzione.
Considerazioni sulla memoria
Se si eseguono operazioni di estrazione, trasformazione e caricamento (ETL) del data warehouse mentre il cubo OLAP è operativo su un server, occorre considerare attentamente le esigenze di memoria del sistema operativo, del data warehouse e di SSAS per garantire che il server sia in grado di gestire tutte le operazioni eseguite in contemporanea che utilizzano un'ingente quantità di dati. Ciò è particolarmente importante poiché l'elaborazione dei cubi OLAP è un'operazione che richiede molta memoria.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per