Distribuire le applicazioni nel cloud
Dopo che un'applicazione cloud è stata progettata e sviluppata, può passare alla distribuzione per il rilascio ai client. Il processo di distribuzione può essere articolato in più fasi, ciascuno dei quali prevede una serie di controlli per assicurare che gli obiettivi dell'applicazione siano soddisfatti.
Prima di distribuire un'applicazione cloud nell'ambiente di produzione, è utile preparare un elenco di controllo che consenta di valutare l'applicazione in base a una serie di procedure consigliate essenziali. Gli esempi includono l'elenco di controllo per la distribuzione di AWS e Azure. Molti provider di servizi cloud offrono un elenco completo di strumenti e servizi che supportano la distribuzione, ad esempio questo documento di Azure.
Processo di distribuzione
La distribuzione di un'applicazione cloud è un processo iterativo che inizia dalla fine dello sviluppo e prosegue fino al rilascio dell'applicazione nelle risorse di produzione:
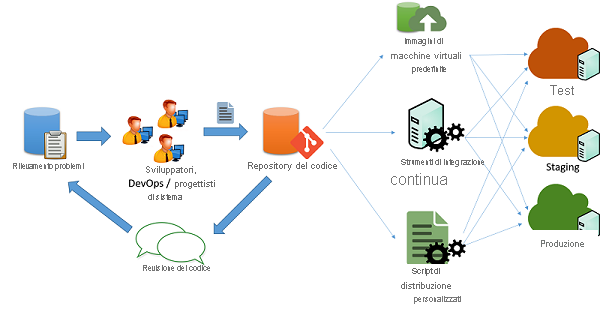
Figura 1: Processo di distribuzione del codice
Sviluppatori di applicazioni cloud gestiscono in genere più versioni simultanee delle applicazioni per la distribuzione nelle diverse fasi della pipeline:
- Test
- Gestione temporanea
- Produzione
Ognuna delle tre fasi dovrebbe teoricamente avere le stesse risorse e la stessa configurazione, consentendo agli sviluppatori di testare e distribuire l'applicazione e ridurre al minimo le probabilità di incoerenze dovute a un cambiamento di ambiente e configurazione.
Pipeline delle modifiche all'applicazione
In uno scenario tipico di sviluppo di applicazioni agile, come illustrato nella figura precedente, le applicazioni vengono gestite da un gruppo di tecnici e sviluppatori che collaborano per risolvere problemi e bug adottando un apposito meccanismo di rilevamento dei problemi. Le modifiche al codice vengono gestite tramite un sistema di repository del codice (ad esempio, svn, mercurial o git), in cui vengono gestiti rami distinti per il rilascio del codice. Una volta superati i passaggi di modifica, revisione e approvazione, il codice può passare alle fasi di test, gestione temporanea e produzione. Questa operazione può essere eseguita in diversi modi:
Script personalizzati: gli sviluppatori possono usare script personalizzati per eseguire il pull della versione più recente del codice ed eseguire comandi specifici per compilare l'applicazione e inserirli in uno stato di produzione.
Immagini di macchine virtuali preconfigurate: gli sviluppatori possono anche provvedere al provisioning e configurare una macchina virtuale con tutto l'ambiente e il software necessari per implementare l'applicazione. Una volta configurata la macchina virtuale, è possibile crearne uno snapshot ed esportarla in un'immagine di macchina virtuale. Questa immagine può essere fornita a diversi sistemi di orchestrazione nel cloud da distribuire e configurare automaticamente per un ambiente di produzione.
Sistemi di integrazione continua: per semplificare le varie attività coinvolte nella distribuzione, è possibile usare strumenti di integrazione continua (CI) per automatizzare le attività (ad esempio il recupero della versione più recente da un repository, la compilazione di file binari dell'applicazione e l'esecuzione di test case) che devono essere completate nei vari computer che costituiscono l'infrastruttura di produzione. Tra gli strumenti di integrazione continua più diffusi sono inclusi Jenkins, Bamboo e Travis. Azure Pipelines è uno strumento di integrazione continua specifico di Azure, appositamente progettato per le distribuzioni di Azure.
Gestione dei tempi di inattività
Alcune modifiche all'applicazione possono richiedere un'interruzione parziale o completa dei servizi dell'applicazione per incorporare una modifica nel back-end dell'applicazione. Gli sviluppatori devono in genere pianificare un'ora specifica del giorno in modo da ridurre al minimo le interruzioni per i clienti dell'applicazione. Le applicazioni progettate per l'integrazione continua possono essere in grado di eseguire queste modifiche in tempo reale nei sistemi di produzione con interruzioni minime o senza interruzioni dei client dell'applicazione.
Ridondanza e tolleranza di errore
Le procedure consigliate per la distribuzione di applicazioni in genere presuppongono che l'infrastruttura cloud sia temporanea e che possa essere non disponibile o comunque cambiare in qualsiasi momento. Le macchine virtuali distribuite in un servizio IaaS, ad esempio, possono essere pianificate per la terminazione a discrezione del provider di servizi cloud, in base al tipo di contratto di servizio.
Le applicazioni devono evitare di impostare le risorse come hardcoded o presupporre endpoint statici per diversi componenti, ad esempio i database e gli endpoint di archiviazione. In teoria, le applicazioni progettate correttamente dovrebbero usare API di servizio per eseguire query sulle risorse, individuarle e connettersi ad esse in modo dinamico.
Gli errori irreversibili delle risorse o della connettività possono verificarsi da un momento all'altro, senza preavviso. Le applicazioni critiche devono essere progettate in previsione di tali errori in modo da assicurare la ridondanza del failover.
Molti provider di servizi cloud progettano i data center in aree e zone. Un'area è un luogo geografico specifico che ospita un data center completo, mentre le zone sono singole sezioni all'interno di un data center che vengono isolate per la tolleranza di errore. Due o più zone all'interno di un data center, ad esempio, possono avere un'infrastruttura di alimentazione, raffreddamento e connettività separata, in modo che un errore in una zona non influisca sull'infrastruttura dell'altra zona. I provider di servizi cloud rendono in genere disponibili le informazioni su aree e zone ai client e agli sviluppatori per consentire loro di progettare e sviluppare applicazioni in grado di sfruttare questa proprietà di isolamento.
Gli sviluppatori possono quindi configurare l'applicazione per l'uso di risorse in più aree o zone in modo da migliorare la disponibilità dell'applicazione e assicurarne la tolleranza agli errori che possono verificarsi in una zona o in un'area. A tale scopo, dovranno configurare sistemi in grado di instradare e bilanciare il traffico tra aree e zone. È anche possibile configurare i server DNS per rispondere alle richieste di ricerca del dominio a indirizzi IP specifici di ogni zona, a seconda della provenienza della richiesta. In questo modo viene fornito un metodo di bilanciamento del carico basato sulla prossimità geografica dei client.
Sicurezza e protezione avanzata in produzione
L'esecuzione di applicazioni Internet in un cloud pubblico deve essere gestita con cautela. Poiché gli intervalli IP del cloud sono posizioni note per destinazioni di valore elevato, è importante assicurarsi che tutte le applicazioni distribuite nel cloud seguano le procedure consigliate per la sicurezza e la protezione avanzata di endpoint e interfacce. Di seguito sono riportati alcuni principi fondamentali da seguire:
- Tutto il software deve passare alla modalità di produzione. La maggior parte del software supporta la "modalità di debug" per i test locali e la "modalità di produzione" per le distribuzioni effettive. Le applicazioni in modalità di debug in genere comportano la perdita di una grande quantità di informazioni che gli utenti malintenzionati possono sfruttare inviando input in formato non valido e quindi rappresentano una facile fonte di esplorazione per gli hacker. Indipendentemente dal fatto che si usi un framework Web come Django e Rails o un database come Oracle, è importante attenersi alle linee guida pertinenti per la distribuzione di applicazioni di produzione.
- L'accesso ai servizi non pubblici deve essere limitato a determinati indirizzi IP interni per l'accesso amministrativo. Assicurarsi che gli amministratori non possano accedere direttamente a una risorsa critica da Internet senza prima visualizzare una finestra di avvio interna. Configurare i firewall con l'indirizzo IP e le regole basate su porta per consentire il set minimo di accessi richiesti, in particolare tramite SSH e altri strumenti di connettività remota.
- Seguire il principio dei privilegi minimi. Eseguire tutti i servizi come utente con privilegi minimi che può svolgere il ruolo richiesto. Limitare l'uso di credenziali radice a specifici accessi manuali da parte degli amministratori di sistema che devono eseguire il debug o configurare alcuni problemi critici nel sistema. Questo vale anche per l'accesso ai database e ai pannelli amministrativi. Gli accessi devono in genere essere protetti con una coppia di chiavi pubblica/privata lunga e casuale e la coppia di chiavi deve essere archiviata in modo sicuro in un percorso crittografato ad accesso limitato. Tutte le password devono rispettare rigorosi requisiti di complessità.
- Usare tecniche e strumenti di difesa noti per sistemi di rilevamento e prevenzione delle intrusioni (IDS/IPS), tecnologie di informazioni di sicurezza e gestione degli eventi (SIEM), firewall a livello di applicazione e sistemi anti-malware.
- Configurare una pianificazione per l'applicazione di patch che coincide con le versioni di patch rilasciate dal fornitore dei sistemi in uso. I fornitori come Microsoft seguono spesso un ciclo di rilascio ben definito per le patch.