Spiegare come ottimizzare l'archiviazione di Azure per le macchine virtuali SQL Server
Le prestazioni delle risorse di archiviazione costituiscono un elemento fondamentale di un'applicazione con un elevato numero di operazioni di I/O come ad esempio un motore di database. Azure offre un'ampia gamma di opzioni di archiviazione e consente persino di creare la propria soluzione di archiviazione per soddisfare i requisiti dei carichi di lavoro.
Archiviazione di Azure è una piattaforma affidabile e sicura progettata per soddisfare le diverse esigenze di varie applicazioni. Offre un'ampia gamma di soluzioni scalabili, garantendo che tutti i tipi di archiviazione supportino la crittografia dei dati inattivi. Gli utenti possono scegliere tra una chiave di crittografia gestita da Microsoft o una chiave di crittografia definita dall'utente per una maggiore sicurezza.
Archiviazione BLOB: l'archiviazione BLOB è nota come archiviazione basata su oggetti e include livelli di archiviazione offline sicura, ad accesso frequente e archivio. In un ambiente SQL Server, l'archiviazione BLOB viene solitamente usata per i backup dei database tramite la funzionalità di backup su URL di SQL Server.
Archiviazione file: l'archiviazione file è in realtà una condivisione di file che può essere montata all'interno di una macchina virtuale senza dover configurare hardware. SQL Server può usare l'archiviazione file come destinazione di archiviazione per un'istanza del cluster di failover.
Archiviazione su disco: i dischi gestiti di Azure offrono l'archiviazione a blocchi presentata a una macchina virtuale. Questi dischi vengono gestiti esattamente come un disco fisico in un server locale, ad eccezione del fatto che sono virtualizzati. All'interno dei dischi gestiti sono disponibili diversi livelli di prestazioni a seconda del carico di lavoro. Questo tipo di risorsa di archiviazione è il tipo usato più di frequente per i file di dati e di log delle transazioni di SQL Server.
Dischi gestiti di Azure
I dischi gestiti di Azure sono volumi di archiviazione a livello di blocco presentati alle macchine virtuali di Azure. L'archiviazione a livello di blocco si riferisce a volumi raw di archiviazione che vengono creati e possono essere considerati come un singolo disco rigido. Questi dispositivi a blocchi possono essere gestiti all'interno del sistema operativo e il livello di archiviazione non riconosce il contenuto del disco. L'alternativa all'archiviazione a blocchi è l'archiviazione di oggetti, in cui i file e i relativi metadati vengono archiviati nel sistema di archiviazione sottostante. Archiviazione BLOB di Azure è un esempio di modello di archiviazione di oggetti. Sebbene l'archiviazione di oggetti funzioni bene per molte soluzioni di sviluppo moderne, la maggior parte dei carichi di lavoro in esecuzione nelle macchine virtuali usa l'archiviazione a blocchi.
La configurazione dei dischi gestiti è importante per le prestazioni dei carichi di lavoro di SQL Server. Se si passa da un ambiente locale, è importante acquisire metriche come i secondi medi del disco/lettura e la scrittura media del disco da Performance Monitor come descritto in precedenza. Un'altra metrica da acquisire è Operazioni I/O al secondo, che può essere acquisita usando i contatori SQL Server: Statistiche del pool di risorse di I/O letti da disco/sec o I/O scritti su disco/sec, che mostrano il numero di operazioni di I/O servite da SQL Server al picco. È importante comprendere i carichi di lavoro. Si vuole progettare l'archiviazione e la macchina virtuale per soddisfare le esigenze di tali picchi di carico di lavoro senza incorrere in una latenza significativa. Ogni tipo di macchina virtuale di Azure ha un limite per gli I/O.
I dischi gestiti di Azure sono di quattro tipi:
Disco Ultra: i dischi Ultra supportano carichi di lavoro di I/O elevati per i database cruciali con bassa latenza.
SSD Premium: i dischi SSD Premium offrono velocità effettiva elevata e bassa latenza e possono soddisfare le esigenze della maggior parte dei carichi di lavoro di database in esecuzione nel cloud.
SDD standard: i dischi SSD Standard sono progettati per server Web o carichi di lavoro di sviluppo e test minori, con poche operazioni di I/O e che richiedono una latenza prevedibile.
HDD Standard: i dischi HDD Standard sono adatti per i backup e l'archiviazione di file con accesso sporadico.
In genere, i carichi di lavoro di SQL Server di produzione usano il disco Ultra o l'unità SSD Premium o una combinazione dei due. I dischi Ultra vengono in genere usati in cui si sta cercando una latenza submillisecond in tempo di risposta. I dischi SSD Premium hanno in genere tempi di risposta nell'ordine dei millisecondi a cifra singola, ma costano di meno inferiori e hanno una maggiore flessibilità di progettazione. I dischi SSD Premium inoltre supportano la memorizzazione nella cache di lettura, che può avvantaggiare i carichi di lavoro dei database di lettura intensivi perché riducono il numero di trip al disco. La cache di lettura è archiviata nell'unità SSD locale (l'unità D:\ in Windows o /dev/sdb1/ in Linux), che consente di ridurre il numero di round trip al disco effettivo.
Striping dei dischi per la massima velocità effettiva
Uno dei modi per aumentare le prestazioni e il volume dei dischi di Azure è eseguire lo striping dei dati in più dischi. Questa tecnica non si applica al disco Ultra, perché è possibile ridimensionare operazioni di I/O, velocità effettiva e dimensioni massime in modo indipendente in un singolo disco. Con i dischi SSD Premium, però, può essere vantaggioso ridimensionare sia le operazioni di I/O che volume di archiviazione. Per eseguire lo striping dei dischi in Windows, aggiungere il numero di dischi desiderati alla macchina virtuale e quindi creare un pool usando Spazi di archiviazione in Windows. Non configurare la ridondanza per il pool (che limiterebbe le prestazioni) perché la ridondanza viene fornita dal framework di Azure, che conserva tre copie di tutti i dischi in replica sincrona come protezione da errori del disco. Al momento della sua creazione, il pool include la somma delle operazioni di I/O e la somma del volume di tutti i dischi in esso contenuti. Ad esempio, se sono stati usati 10 dischi P30 ogni 1 TB e sono disponibili 5000 operazioni di I/O per disco, è disponibile un volume di 10 TB con 50.000 operazioni di I/O.
Procedure consigliate di configurazione dell'archiviazione di SQL Server
Vi sono alcune raccomandazioni per le procedure consigliate per SQL Server nelle macchine virtuali di Azure e la relativa configurazione di archiviazione:
- Creare un volume separato per i file di dati e i file di log delle transazioni
- Abilitare la memorizzazione nella cache di lettura nel volume del file di dati
- Non abilitare alcuna memorizzazione nella cache nel volume del file di log
- Pianificare un numero aggiuntivo di 20% di operazioni di I/O e velocità effettiva durante la compilazione dell'archiviazione per la macchina virtuale per gestire i picchi di carico di lavoro
- Usare l'unità D: (unità SSD collegata localmente) per i file TempDB perché TempDB viene ricreata al riavvio del server, quindi non esiste alcun rischio di perdita di dati
- Abilitare l'inizializzazione immediata dei file per ridurre l'impatto delle attività di aumento delle dimensioni dei file.
- Spostare le directory dei file di traccia e dei log degli errori sui dischi di dati
- Per i carichi di lavoro che richiedono una latenza di archiviazione inferiore a 1 millisecondo, prendere in considerazione l'uso del disco Ultra su SSD Premium.
Provider di risorse della macchina virtuale di Azure
Un modo per ridurre la complessità della compilazione dell'archiviazione per SQL Server in una macchina virtuale di Azure consiste nell'usare i modelli di SQL Server in Azure Marketplace, che consentono di configurare l'archiviazione come parte della distribuzione. È possibile configurare gli I/O in base alle esigenze e il modello esegue il lavoro di creazione dei pool di spazi di archiviazione in Windows.
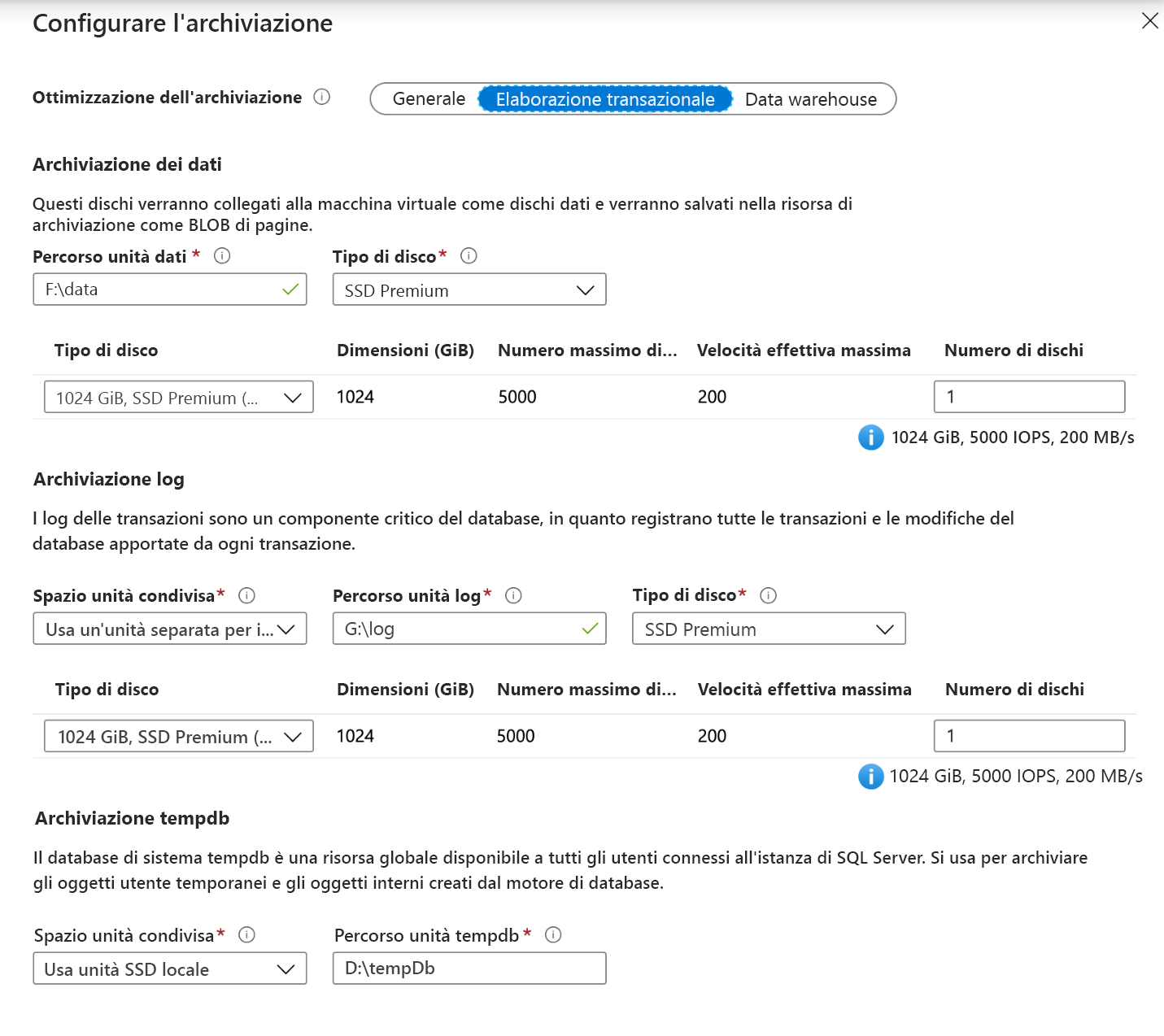
Questo provider di risorse supporta anche l'aggiunta di TempDB all'unità SSD locale e genera un'attività pianificata per creare la cartella all'avvio.