Usare l'API di conversione da voce a testo
Azure Speech in Foundry Tools supporta il riconoscimento vocale tramite l'API Speech to text*. Anche se i dettagli specifici variano, a seconda dell'SDK usato (Python, C# e così via); esiste un modello coerente per l'uso dell'API Riconoscimento vocale :
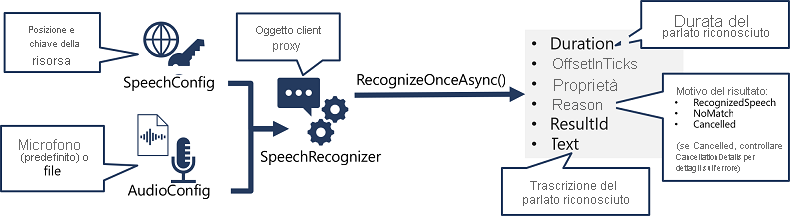
- Usare un oggetto SpeechConfig per incapsulare le informazioni necessarie per connettersi alla risorsa Foundry. In particolare, l'endpoint (o l'area) e la chiave.
- È anche possibile usare un oggetto AudioConfig per definire l'origine di input per l'audio da trascrivere. Per impostazione predefinita, si tratta del microfono di sistema predefinito, ma è anche possibile specificare un file audio.
- Usare SpeechConfig e AudioConfig per creare un oggetto SpeechRecognizer . Questo oggetto è un client proxy per l'API Riconoscimento vocale .
- Usare i metodi dell'oggetto SpeechRecognizer per chiamare le funzioni API sottostanti. Ad esempio, il metodo RecognizeOnceAsync() usa il servizio Voce di Azure per trascrivere in modo asincrono una singola espressione parlata.
- Elaborare la risposta. Nel caso del metodo RecognizeOnceAsync(), il risultato è un oggetto SpeechRecognitionResult che include le proprietà seguenti:
- Durata
- OffsetInTicks
- Proprietà
- Motivo
- ResultId
- Testo
Se l'operazione ha esito positivo, la proprietà Reason ha il valore enumerato RecognizedSpeech e la proprietà Text contiene la trascrizione. Altri valori possibili per Result includono NoMatch (che indica che l'audio è stato analizzato correttamente ma non è stato riconosciuto il riconoscimento vocale) o Canceled, a indicare che si è verificato un errore (in questo caso, è possibile controllare l'insieme Properties per la proprietà CancellationReason per determinare cosa è andato storto).
Esempio - Trascrizione di un file audio
L'esempio python seguente usa Speech di Azure in Foundry Tools per trascrivere il parlato in un file audio.
import azure.cognitiveservices.speech as speech_sdk
# Speech config encapsulates the connection to the resource
speech_config = speech_sdk.SpeechConfig(subscription="YOUR_FOUNDRY_KEY",
endpoint="YOUR_FOUNDRY_ENDPOINT")
# Audio config determines the audio stream source (defaults to system mic)
file_path = "audio.wav"
audio_config = speech_sdk.audio.AudioConfig(filename=file_path)
# Use a speech recognizer to transcribe the audio
speech_recognizer = speech_sdk.SpeechRecognizer(speech_config=speech_config,
audio_config=audio_config)
result = speech_recognizer.recognize_once_async().get()
# Did it succeeed
if result.reason == speech_sdk.ResultReason.RecognizedSpeech:
# Yes!
print(f"Transcription:\n{result.text}")
else:
# No. Try to determine why.
print("Error transcribing message: {}".format(result.reason))