Modellazione dei dati per Dataverse
Per le operazioni di archiviazione o visualizzazione dei dati mediante un'app, la struttura dei dati riveste un ruolo particolarmente importante a livello di progettazione. Occorre valutare come vengono usati i dati non solo in un'app o una schermata specifica, ma anche dagli altri utenti. L'analisi di utenti tipo, attività, processi aziendali e obiettivi supporta il processo di definizione e strutturazione dei dati da archiviare.
Tipi di tabella
Dataverse dispone di tre tipi di tabella.
- Standard: tipo di tabelle in cui è possibile archiviare i dati e aggiungerli alla navigazione nelle app basate su modello. La maggior parte delle tabelle che verranno create è di tipo standard. Numerose tabelle standard vengono create in base allo schema Common Data Model in un ambiente Dataverse.
- Attività: questo tipo di tabelle viene usato per archiviare le interazioni, ad esempio le telefonate, le attività e gli appuntamenti. Un set di tabelle attività si trova in un database Dataverse.
- Virtuale: questo tipo di tabelle consente di creare la tabella e le colonne in Dataverse e quindi di usare un'origine dati esterna per archiviare i dati. I dati verranno quindi visualizzati nelle app degli utenti come qualsiasi altro dato.
Quando viene creata una tabella standard personalizzata, è necessario specificarne la proprietà.
- Utente/team: opzione predefinita
- Organizzazione: opzione usata per i dati di riferimento
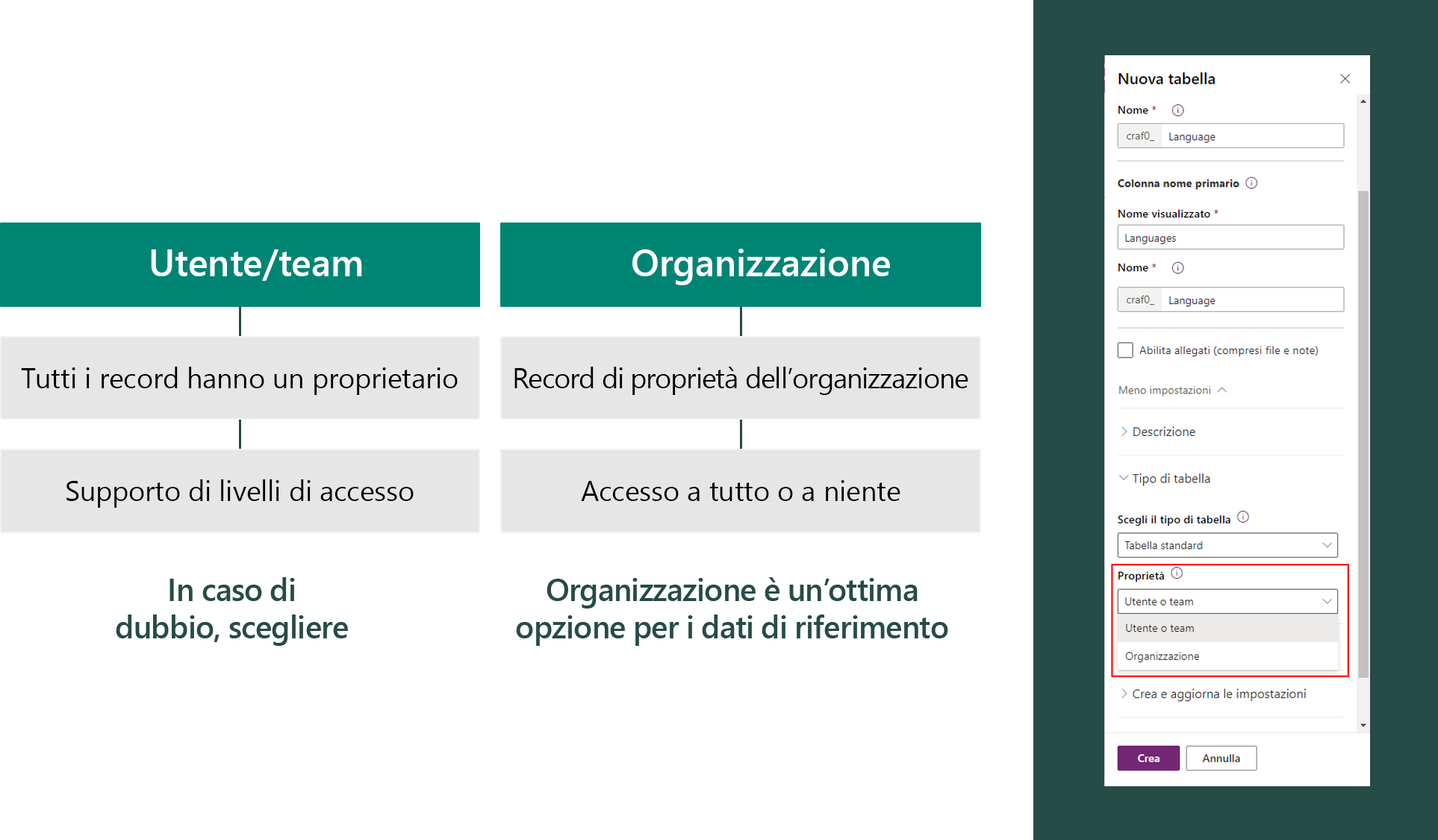
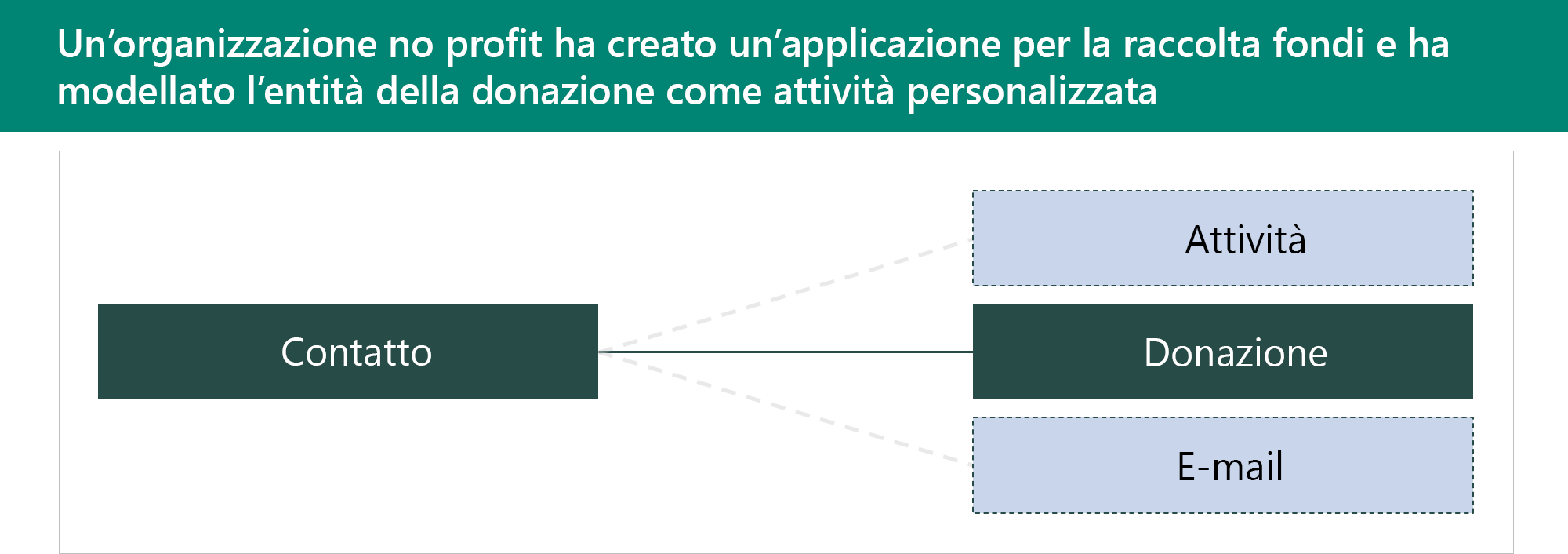
Tabelle di attività personalizzate
Le tabelle attività vengono usate per archiviare le interazioni. Questo tipo di tabelle ha una relazione con tutte le tabelle la cui opzione Abilita per attività è impostata nei relativi metadati. Le tabelle attività condividono lo stesso set di colonne e gli stessi privilegi di sicurezza. Le righe delle tabelle attività vengono visualizzate nella cronologia dei moduli delle app basate su modello. Nell'esempio seguente è stata creata una tabella attività personalizzata denominata Donation (Donazione).
I vantaggi derivanti dall'uso delle tabelle attività personalizzate sono i seguenti:
- Visualizzazione in un elenco con altre attività.
- Possibilità di esecuzione del rollup con altre attività.
- Possibilità di creazione di una donazione in qualsiasi tabella che supporti le attività.
I principali svantaggi derivanti dall'uso delle tabelle attività personalizzate sono i seguenti:
- Configurazione di un livello di sicurezza diverso rispetto a qualsiasi altra attività.
- Controllo delle tabelle correlate a una donazione.
Tipo di dati colonna
È necessario scegliere il tipo di dati per le colonne con particolare attenzione. Ciò è valido soprattutto per i tipi di dati numerici perché non è possibile confrontare colonne numeriche con tipi diversi. Ai tipi di dati per le colonne calcolate e di rollup vengono infatti applicate restrizioni. Dopo aver scelto il tipo di dati, non sarà più possibile modificarlo.
| Tipo di dati | Commenti |
|---|---|
| Sì/No | Assicurarsi che non sia mai necessario disporre di altre scelte |
| File e Immagine | Consente di archiviare file e immagini incorporati in Dataverse |
| Cliente | Può essere un contatto o un account |
| Ricerca/Scelta | Assicurarsi di scegliere il tipo di dati più idoneo |
| Data/Ora | Assicurarsi di scegliere il funzionamento appropriato |
| Numerico | Sono disponibili numerose opzioni da selezionare, prestare particolare attenzione durante la scelta |
Tabella di scelta e tabella di ricerca
La decisione di usare una tabella di ricerca o una tabella di scelta dipende da vari fattori.
Usare una tabella di scelta quando la tabella deve:
- Archiviare solo l'etichetta e il valore come coppia chiave-valore.
- Presenza della localizzazione integrata.
- Essere considerata un componente di soluzione.
- Non avere un modo predefinito per ritirare i valori.
- Essere caratterizzata da un'esperienza utente (UX) che funziona su circa 200 elementi.
- Supportare l'uso di filtri mediante JavaScript.
- Essere archiviata come numero intero sulla riga.
Usare una tabella di ricerca quando la tabella:
- Può archiviare altri dati in colonne nella riga.
- Richiede l'integrazione della localizzazione.
- Viene considerata come dati di riferimento.
- Supporta uno stato inattivo.
- È caratterizzata da un'esperienza utente (UX) la cui scalabilità è valida per molti elementi.
- Può filtrare i dati per viste e sicurezza.
- Viene archiviata come riferimento a entità.
L'archiviazione di altri dati nella tabella di ricerca consente l'accesso quando si eseguono flussi di lavoro o altre personalizzazioni che fanno riferimento ai dati. Ad esempio, una proprietà correlata può essere usata in una condizione di controllo.
Dal momento che è un componente di soluzione, una tabella di scelta è in grado di gestire la risoluzione dell'unione anteponendo al valore il prefisso dell'autore.
L'aggiunta di valori a una tabella di scelta richiede l'accesso a livello di amministratore/personalizzatore, mentre i valori di ricerca possono essere modificati da un utente con l'autorizzazione concessa tramite i ruoli di sicurezza.
L'esperienza utente (UX) per le tabelle di scelta è ideale per piccole quantità di dati, mentre non funziona correttamente per set di grandi dimensioni. Le tabelle di ricerca dispongono di funzionalità relative al tipo di ricerca che non sono disponibili nelle tabelle di scelta.
Se si dispone di colonne a scelta multipla dipendenti l'una dall'altra, questa attività può essere eseguita solo mediante script basati su form, mentre le ricerche possono essere filtrate in base ad altre ricerche mediante la configurazione.
Archiviazione dei dati di file e immagine
Sono disponibili diverse scelte per l'archiviazione di file e immagini.
- Dataverse: consente di archiviare file e immagini usando i tipi di dati File e Immagine.
- SharePoint: da usare per la collaborazione, anche se questa opzione è caratterizzata da un problema di sicurezza. La sicurezza dei file si basa sulle autorizzazioni di SharePoint, ma non è sincronizzata con le autorizzazioni di Dataverse a livello di riga.
- Archiviazione di Azure: da usare per l'archiviazione e l'accesso esterno. Questa scelta è caratterizzata da sicurezza autonoma, ma questo tipo di sicurezza può essere concesso per brevi periodi di tempo in base a un collegamento generato per il consumo (modello di servizio). Archiviazione di Azure può gestire anche file di grandi dimensioni.
Caratteristiche dei tipi di dati file e immagine:
- Sono consigliati per il caricamento e come riferimento.
- La sicurezza fa riferimento alle autorizzazioni a livello di record.
- Sono limitati dalle dimensioni.
Colonne calcolate (colonne Formula Fx)
Le colonne calcolate consentono di eseguire calcoli semplici sui dati in una riga, ovvero:
- Vengono calcolate al momento del recupero di un record.
- Includono un valore di sola lettura.
- Possono includere colonne della stessa riga e colonne in relazioni molti-a-uno.
- Possono includere colonne di rollup nel calcolo.
- Non possono attivare un evento per flussi di lavoro, plug-in o Power Automate.
- Vengono creati usando il linguaggio delle formule Fx.
Colonne di rollup
Le colonne di rollup permettono l'aggregazione di righe correlate in relazioni uno-a-molti, ovvero:
- Vengono calcolate in base a una pianificazione (intervallo minimo di un'ora) e possono essere aggiornate su richiesta da un utente.
- Includono un valore di sola lettura.
- Possono eseguire il rollup delle colonne calcolate.
- Possono usare la gerarchia dei record correlati.
- Possono filtrare i dati tra tabelle correlate.
- Non possono attivare un evento per flussi di lavoro, plug-in o Power Automate.
È possibile eseguire il rollup di colonne calcolate "semplici", ovvero colonne calcolate contenenti funzioni non deterministiche delle quali non è possibile eseguire il rollup.
Relazioni
Le relazioni definiscono il modo in cui le righe sono correlate tra loro in Dataverse. Ogni tabella in Dataverse ha una chiave primaria che definisce un riferimento univoco alle righe nella tabella. In Dataverse la chiave primaria è un identificatore univoco globale (GUID) generato automaticamente da Dataverse quando viene creata una riga. Le relazioni vengono create mediante l'aggiunta di un riferimento alla chiave primaria, nota come chiave esterna. In Dataverse le relazioni vengono create usando una colonna in una tabella in cui includere il valore della chiave esterna. Questa chiave esterna è un puntatore alla chiave primaria nell'altra tabella.
Dataverse supporta due tipi di relazioni:
- Uno-a-molti (1:N)
- Molti-a-molti (N:N)
Relazione uno-a-molti
La seguente nota spese è un esempio di relazione uno-a-molti (1:N).
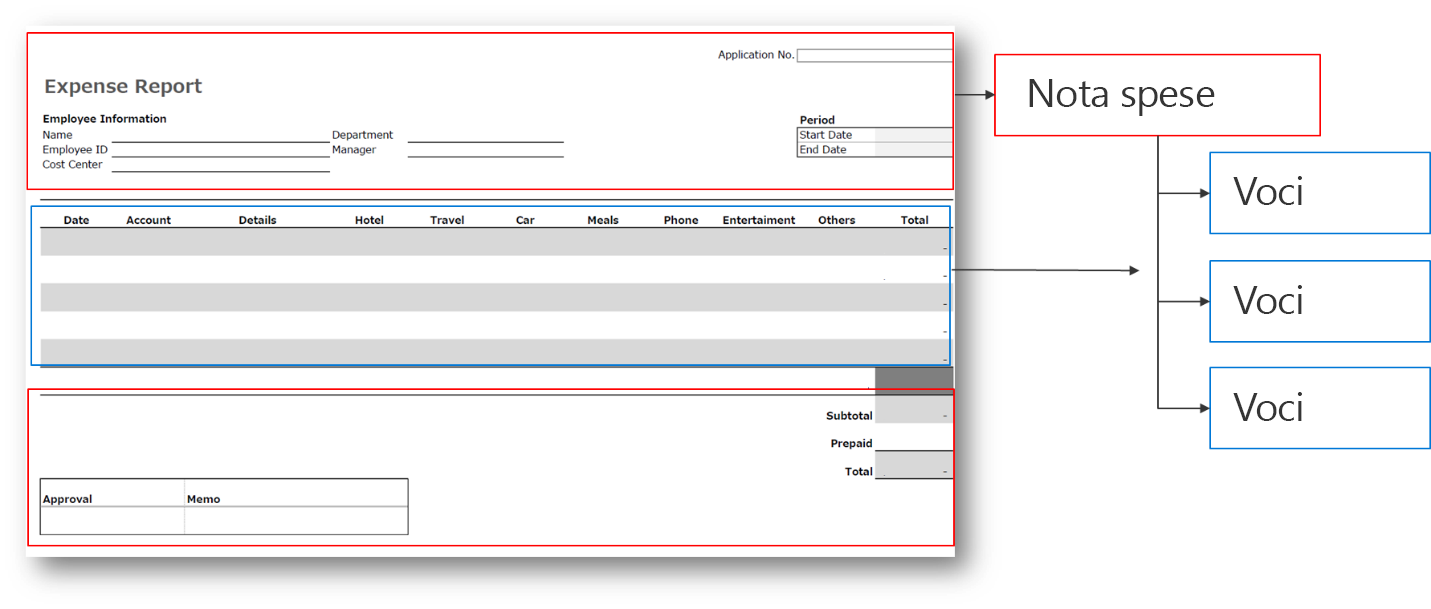
Lo screenshot sopra riportato mostra la parte principale della nota spese, che contiene il nome del dipendente e i dettagli del reparto. Sotto la parte principale ci sono più righe di descrizioni per ogni articolo acquistato. In questo esempio, le descrizioni vengono denominate voci. Ogni voce ha una struttura diversa rispetto alla parte principale della nota spese. Pertanto, ogni nota spese avrà più voci.
La relazione tra nota spese e voce è un esempio di relazione uno-a-molti (1:N). La parte principale della nota spese è collegata a più voci. È inoltre possibile visualizzare la relazione dal punto di vista delle voci, ovvero ogni voce può essere collegata solo a una nota spese e in questo caso si tratta di una relazione molti-a-uno (N: 1).
Relazione molti-a-molti
Una struttura di dati con relazioni molti-a-molti è di tipo speciale e viene usata quando è possibile associare più record a più set di altri record. Un ottimo esempio di struttura di dati con relazioni molti-a-molti è dato dalla rete di partner commerciali. Un utente lavora con più partner commerciali (clienti e fornitori) e tali partner a loro volta lavorano con più colleghi dell'utente.
Le sezioni seguenti forniscono esempi dei diversi tipi di strutture di dati con relazioni molti-a-molti.
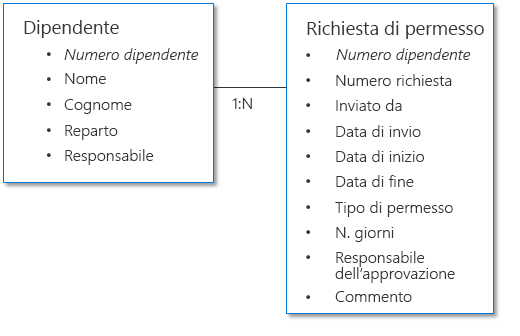
Esempio 1: richiesta di approvazione del permesso
L'esempio seguente mostra due set di dati: uno che rappresenta il dipendente e l'altro che rappresenta la richiesta di permesso. Poiché ogni dipendente invia più richieste, la relazione in questo scenario sarà di tipo uno-a-molti, dove "uno" è il dipendente e "molti" fa riferimento alle richieste. I dati dei dipendenti e quelli delle richieste di permesso sono correlati tra loro mediante il numero di dipendente, che corrisponde alla colonna comune (nota anche come chiave).
Esempio 2: approvazione dell'acquisto
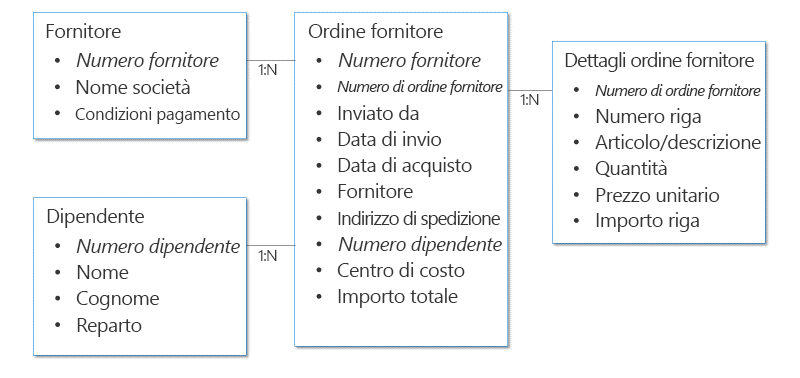
In questo esempio, la struttura dei dati sembra complessa, ma è simile all'esempio di nota spese analizzato all'inizio di questo articolo. Ogni venditore o fornitore è associato a più ordini fornitore. Ogni dipendente è responsabile di più ordini fornitore. Pertanto entrambi i set di dati hanno una struttura di dati con relazioni di tipo uno-a-molti.
Poiché i dipendenti potrebbero non usare sempre lo stesso venditore o fornitore, i fornitori vengono usati da più dipendenti e ogni dipendente lavora con più fornitori. Pertanto, la relazione tra dipendenti e fornitori è di tipo molti-a-molti.
Esempio 3: reporting delle spese
L'esempio seguente mostra un diagramma delle relazioni tra entità contenente più tabelle per una soluzione di reporting delle spese.

Esempio 4: gestione dei benefit scelti dai VIP
In questo esempio sono presenti due VIP, ovvero John e Mary. Come benefit John ha scelto WiFi e il servizio di lavanderia, mentre Mary ha scelto WiFi e il servizio minibar. È possibile definirei l modello di questo scenario in diversi modi. Il primo modo prevede l'uso di una relazione 1:N.
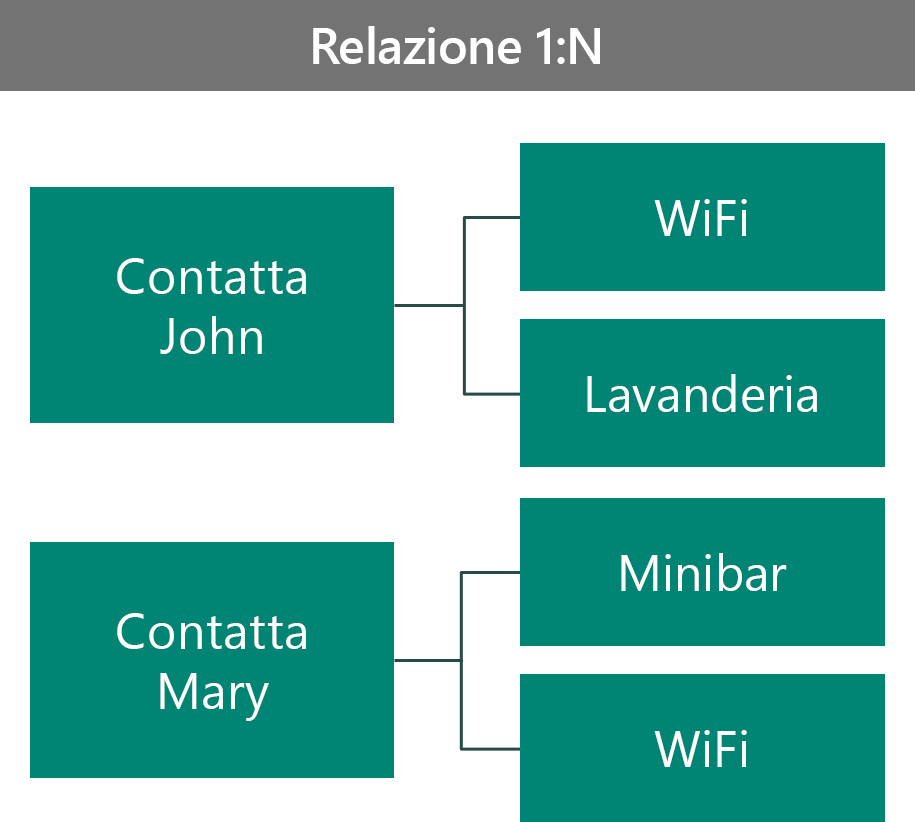
In questa configurazione:
- Il record del benefit è univoco e specifico per il contatto.
- Non è possibile visualizzare tutti i contatti che scelgono un benefit specifico.
- È possibile definire la sicurezza del record del benefit in base al proprietario del contatto.
- È possibile archiviare una maggiore quantità di dati nel record del benefit specifico del contatto.
- La relazione con il benefit è di tipo padre-figlio. In caso contrario, i record dei benefit risulterebbero orfani.
Il secondo modo prevede l'uso di una relazione N:N.
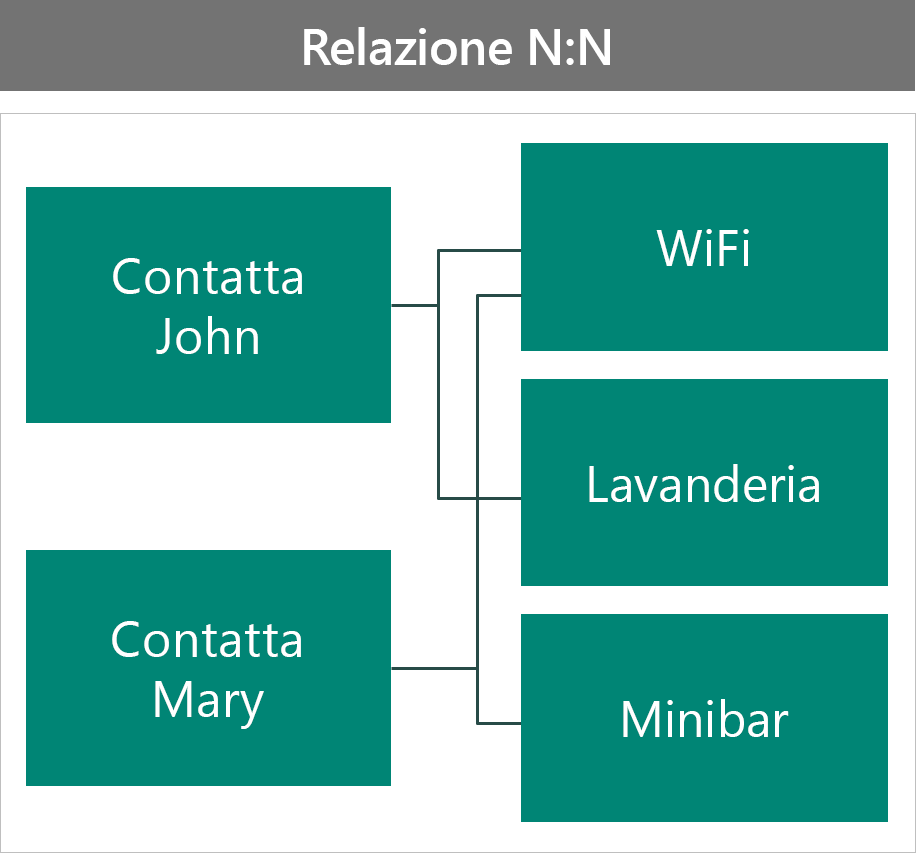
In questa configurazione:
- I record associati relativi al benefit mostrano tutti i contatti che hanno scelto il benefit specifico.
- La sicurezza del benefit è condivisa a livello di tutti i contatti. Non è pertanto possibile personalizzare i singoli contatti.
- Tutti gli attributi del benefit sono condivisi tra tutti i contatti. Non sono pertanto presenti dati specifici del contatto.
- È necessario usare una relazione di riferimento. In caso contrario, il benefit verrebbe rimosso dagli altri contatti.
Nessuna delle due configurazioni rappresenta una soluzione ideale.
Il prossimo esempio fa riferimento alla creazione di una tabella personalizzata (intersezione) per contenere i benefit destinati ai VIP.
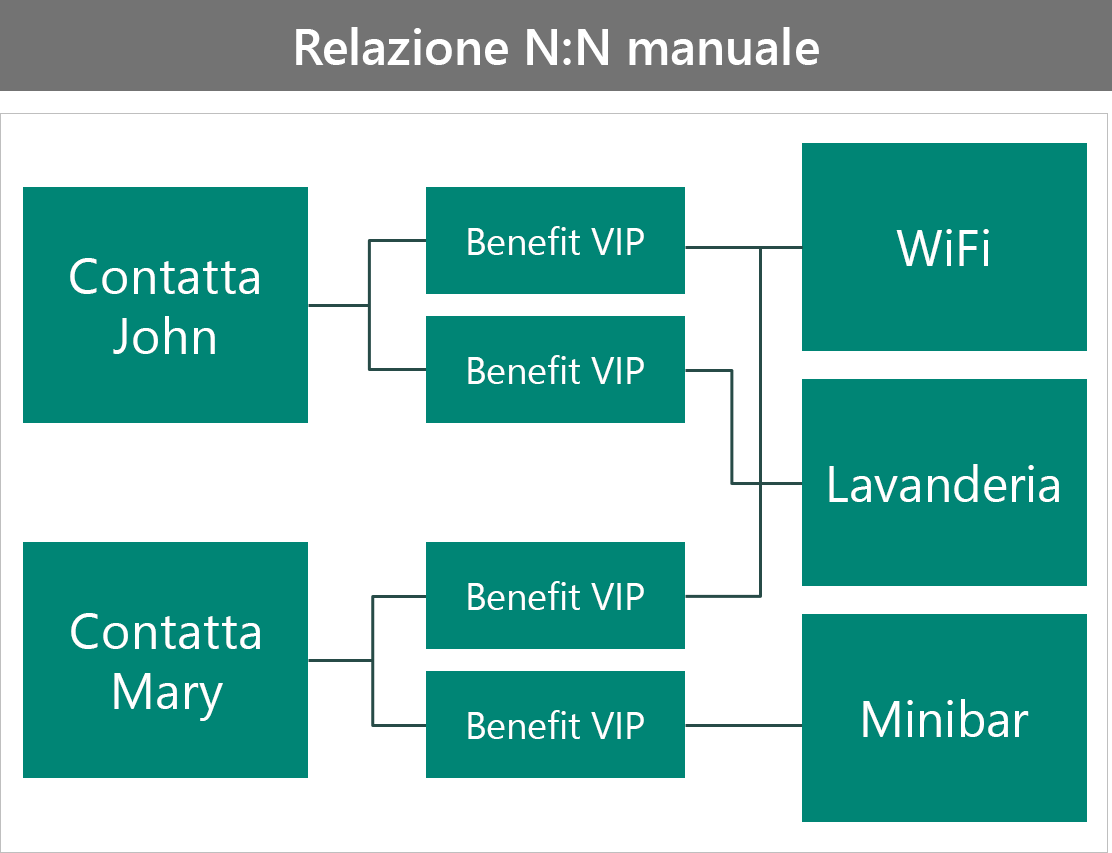
In questa configurazione:
- Viene aggiunta la possibilità di archiviare una quantità maggiore di dati nella tabella dei benefit specifica di un contatto.
- È richiesto un maggiore intervento dell'utente per collegare i record. Sarà infatti necessario creare la riga di intersezione manualmente.
- I benefit risultano protetti individualmente.
- L'esecuzione di query risulta più complessa in quanto non è possibile accedere direttamente agli attributi nella tabella dei benefit.
L'esempio seguente mostra l'uso delle colonne nella tabella dei contatti.

Questa configurazione:
- È idonea per benefit principali e secondari, ma non per il rilevamento e la gestione di un numero elevato di benefit.
- Semplifica l'esecuzione di query e l'uso da parte degli utenti di Power BI in modalità self-service.
- È caratterizzata dalla stessa sicurezza del record di contatto.
- Richiede la creazione di una query che analizzi i benefit principali e secondari se si intende eseguire una query su tutti gli utenti hanno scelto un benefit principale.
Questa configurazione è un buon esempio di quando il benefit deve essere registrato a fini di conformità/statistici senza avere alcun impatto sull'attività o sull'elaborazione.
Comportamenti delle relazioni
I comportamenti delle relazioni controllano il modo in cui determinate azioni interessano le righe associate alla riga della tabella principale mediante la relazione 1:N. I comportamenti consentono di mantenere l'integrità referenziale e di impedire che i record orfani non vengano gestiti correttamente.
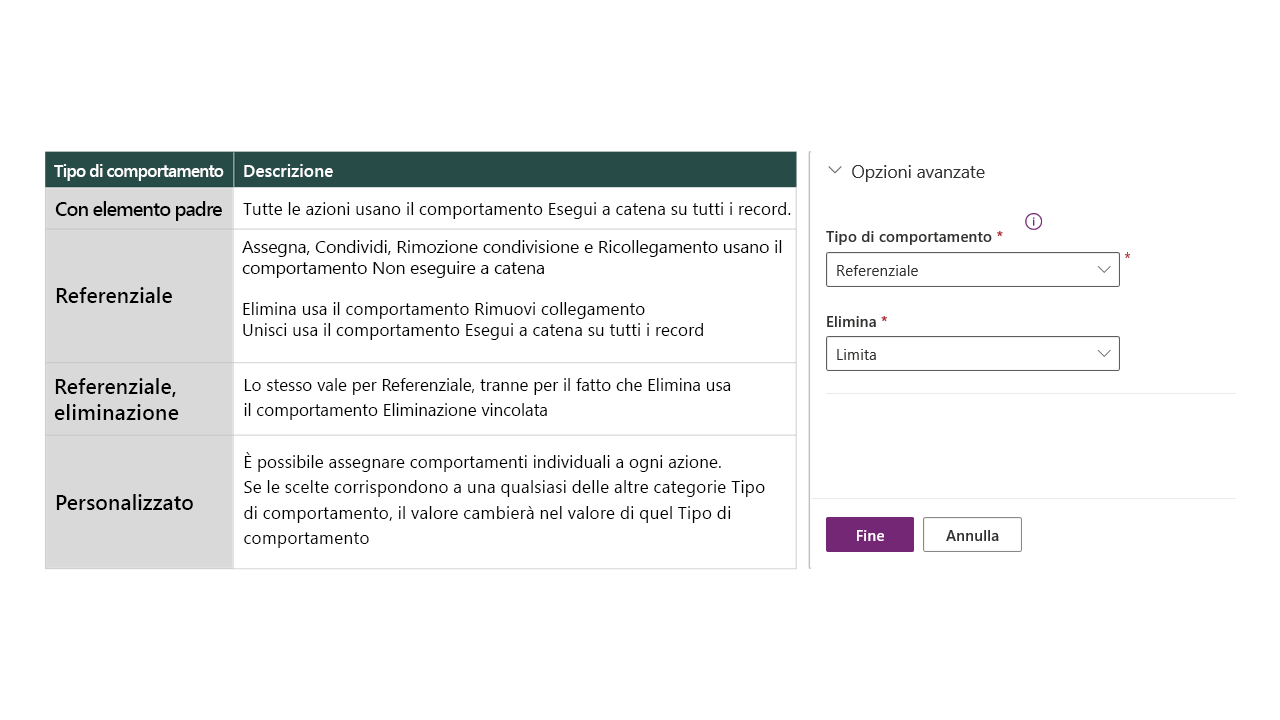
Importante
La definizione dei comportamenti delle relazioni è importante perché la sovrapposizione a cascata dei record assegnati può comportare l'assegnazione di record correlati. In caso di dubbio, impostare il comportamento su Referenziale e Limita.
Chiavi alternative
Le chiavi alternative vengono usate nelle integrazioni per ridurre la necessità di eseguire una query per cercare un record. L'uso di una chiave alternativa consente di aggiornare una riga senza conoscerne il GUID.
Le chiavi alternative:
- Se ne consiglia l'uso nelle operazioni di recupero e aggiornamento.
- Possono contenere valori decimali, numeri interi, campi di testo, date e campi di ricerca.
- Possono essere presenti fino a cinque chiavi alternative per ogni tabella.
- Consentono di creare in background un indice univoco di tipo nullable per applicare l'univocità della chiave.
Quando viene creata una chiave, il sistema convalida che tale chiave può essere supportata dalla piattaforma.
Procedure consigliate relative ai diagrammi
Durante la creazione di diagrammi delle relazioni tra entità in Dataverse, è consigliabile:
- Evitare la duplicazione dei dati. Ogni dato specifico deve avere solo una posizione. Anziché duplicare gli stessi dati tra più tabelle, è consigliabile usare funzionalità quali, ad esempio, i moduli di visualizzazione rapida e le viste per la visualizzazione dei dati di tabelle correlate.
- Usare le relazioni dei diagrammi delle relazioni tra entità per esaminare e individuare potenziali comportamenti a catena che potrebbero influire sulla logica di business. Ad esempio, nelle relazioni di tipo padre-figlio, ai record correlati verranno automaticamente applicate autorizzazioni quali, ad esempio, Assegnazione, Condivisione, Rimozione condivisione, Ricollegamento, Eliminazione e Unione quando viene aggiornato un record padre.