Spiegare le opzioni PaaS per la distribuzione di SQL Server in Azure
Platform as a Service (PaaS) offre un ambiente di sviluppo e distribuzione completo nel cloud, che può essere usato per semplici applicazioni basate sul cloud e per applicazioni aziendali avanzate.
Il database SQL di Azure e l'istanza gestita di SQL di Azure fanno parte dell'offerta PaaS per Azure SQL.
Database SQL di Azure : Parte di una famiglia di prodotti basati sul motore di SQL Server, nel cloud. Offre agli sviluppatori una grande flessibilità nella creazione di nuovi servizi dell'applicazione e opzioni di distribuzione granulari su larga scala. Il database SQL rappresenta una soluzione di manutenzione ridotta che può essere un'ottima opzione per determinati carichi di lavoro.
Istanza gestita di SQL di Azure: È consigliabile per la maggior parte degli scenari di migrazione nel cloud perché offre servizi e funzionalità completamente gestiti.
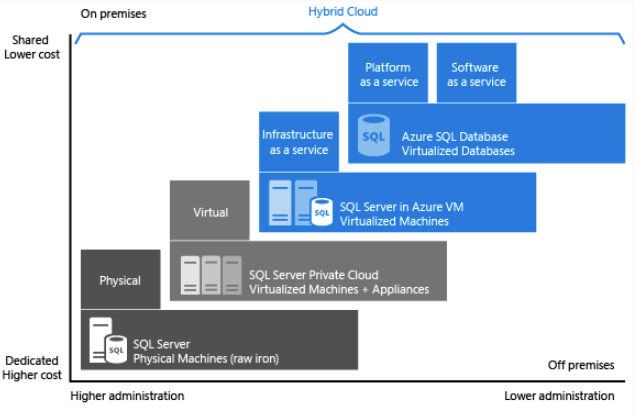
Ogni offerta offre un certo livello di amministrazione rispetto all'infrastruttura, in base al grado di efficienza dei costi.
Modelli di distribuzione
Il database SQL di Azure è disponibile in due diversi modelli di distribuzione:
Database singolo : Un database singolo che viene fatturato e gestito a livello di database. Ogni database viene gestito singolarmente dal punto di vista della scalabilità e della dimensione dei dati. Tutti i database presenti in questo modello hanno risorse dedicate, anche se distribuite nello stesso server logico.
Pool elastici: Un gruppo di database gestiti insieme e che condividono un set comune di risorse. I pool elastici offrono una soluzione conveniente per il modello di applicazione software as a service, perché le risorse vengono condivise tra tutti i database. È possibile configurare le risorse in base al modello di acquisto basato su DTU o al modello di acquisto basato su vCore.
Modello di acquisto
In Azure tutti i servizi supportano l'hardware fisico ed è possibile scegliere tra due diversi modelli di acquisto:
Unità di transazione di database (DTU)
Il modello di acquisto basato su DTU viene calcolato in base a una formula che combina risorse di calcolo, archiviazione e I/O. È una buona scelta per i clienti che vogliono opzioni di risorse semplici e preconfigurate.
Il modello di acquisto DTU è disponibile in diversi livelli di servizio, ad esempio Basic, Standard e Premium. Ogni livello ha diverse funzionalità, offrendo un'ampia gamma di opzioni quando si sceglie questa piattaforma.
In termini di prestazioni, il livello Basic viene usato per carichi di lavoro meno impegnativi, mentre il livello Premium viene usato per i requisiti di carico di lavoro intensivi.
Le risorse di calcolo e di archiviazione dipendono dal livello di DTU e offrono una gamma di funzionalità per le prestazioni in base a un limite di archiviazione fisso, all'intervallo di conservazione dei backup e al costo.
Per altre informazioni sul modello di acquisto DTU, vedere Panoramica del modello di acquisto basato su DTU.
vCore
Il modello di acquisto basato su vCore consente di acquistare un numero specificato di vCore in base ai carichi di lavoro specificati. vCore è il modello di acquisto predefinito quando si acquistano risorse del database SQL di Azure. I database vCore hanno una relazione specifica tra il numero di core e la quantità di memoria e archiviazione fornita al database. Il modello di acquisto vCore è supportato sia dal database SQL di Azure che da Istanza gestita di SQL di Azure.
È possibile acquistare database vCore anche in tre livelli di servizio diversi:
| Livello di servizio | Ideale per | Tipo di archiviazione | Latenza | Livelli di elaborazione | Funzionalità di resilienza | Dimensioni massime del database |
|---|---|---|---|---|---|---|
| Utilizzo generico | Carichi di lavoro per utilizzo generico | Archiviazione Premium di Azure | Maggiore di BC | Con provisioning, serverless | Non disponibile | 4 TB |
| Essenziale per l'azienda | Carichi di lavoro ad alte prestazioni | UNITÀ SSD locali | Minimo | Sottoposto a provisioning | Replica di sola lettura integrata, massima resilienza agli errori | 4 TB |
| Scalabilità estrema | Database su larga scala | Archiviazione Premium di Azure | Varia | Sottoposto a provisioning | Architettura univoca per il ridimensionamento | 100 TB |
Il livello di servizio Utilizzo Generico offre due opzioni di calcolo: Provisionato e Serverless. Le risorse con provisioning sono preallocate e vengono fatturate su base oraria in base ai vCore configurati, risultando ideali per carichi di lavoro costanti. Le risorse serverless si adattano automaticamente alla domanda e sono fatturate al secondo, rendendole convenienti per carichi di lavoro variabili.
Senza server
Il termine "Serverless" può essere fuorviante perché il database SQL di Azure viene comunque distribuito in un server logico per la connessione. Serverless è un livello di calcolo che aumenta o riduce automaticamente le risorse in base alla richiesta del carico di lavoro. Quando il carico di lavoro non richiede più risorse di calcolo, il database viene sospeso e viene fatturata solo l'archiviazione durante il periodo di inattività. Dopo un tentativo di connessione, il database riprende e diventa disponibile.
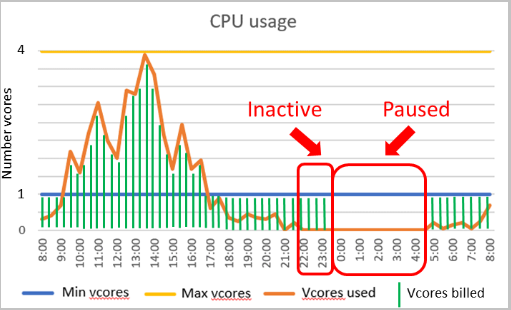
L'impostazione per controllare la sospensione è detta ritardo di sospensione automatica, con un valore minimo di 60 minuti e un valore massimo di sette giorni. Se il database rimane inattivo per tale periodo, viene sospeso.
Una volta che il database è inattivo per l'ora specificata, viene sospeso fino a quando non viene eseguito un tentativo di connessione successivo. La configurazione di un intervallo di scalabilità automatica di calcolo e un ritardo di sospensione automatica influiscono sulle prestazioni e sui costi di calcolo del database.
Le applicazioni che usano serverless devono essere configurate per gestire gli errori di connessione e includere la logica di ripetizione dei tentativi, perché la connessione a un database sospeso genera un errore di connessione.
Un'altra differenza tra serverless e il modello vCore standard del database SQL di Azure è che con serverless è possibile specificare un numero minimo e massimo di vCore. I limiti di memoria e I/O sono proporzionali all'intervallo specificato.
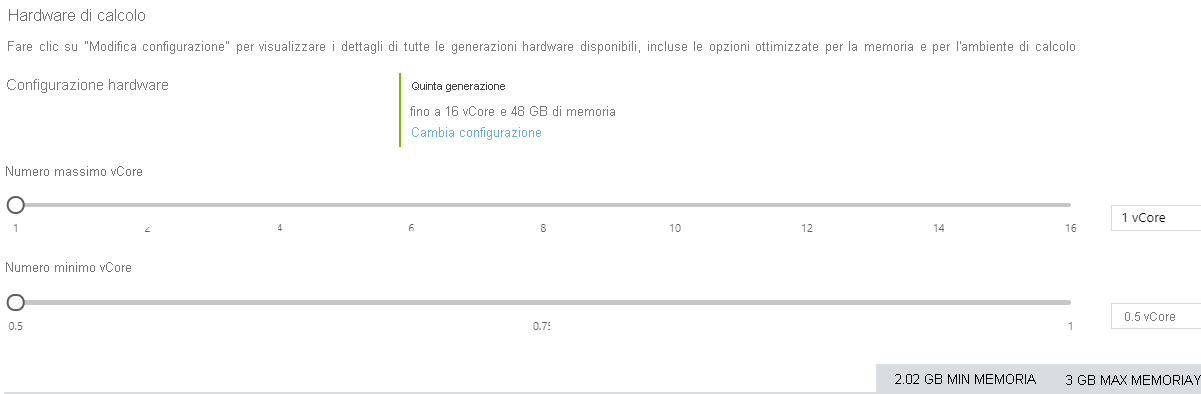
L'immagine mostra la schermata di configurazione per un database serverless nel portale di Azure. È possibile selezionare almeno la metà di un vCore e un massimo di 16 vCore.
Serverless non è completamente compatibile con tutte le funzionalità del database SQL di Azure perché alcuni di essi richiedono l'esecuzione costante di processi in background, ad esempio:
- Replica geografica
- Conservazione del backup a lungo termine
- Un database dei processi in processi elastici
- Database di sincronizzazione in Sincronizzazione dati SQL (sincronizzazione dati è un servizio che replica i dati tra un gruppo di database)
Annotazioni
Serverless è attualmente supportato solo nel livello Utilizzo generico nel modello di acquisto vCore.
Copie di sicurezza
Una delle funzionalità più importanti della piattaforma distribuita come servizio è costituita dai backup. In questo caso, il sistema esegue automaticamente i backup senza alcun intervento da parte dell'utente. L'archiviazione con ridondanza geografica dei BLOB di Azure archivia questi backup e, per impostazione predefinita, li mantiene per un periodo compreso tra 7 e 35 giorni, a seconda del livello di servizio del database. I database Basic e vCore per impostazione predefinita sono sette giorni di conservazione e gli amministratori possono modificare questo valore per i database vCore. È possibile estendere il tempo di conservazione configurando la conservazione a lungo termine (LTR), consentendo di conservare i backup per un massimo di 10 anni.
Per garantire la ridondanza, è anche possibile usare l'archiviazione BLOB con ridondanza geografica e accesso in lettura. Questa risorsa di archiviazione replica i backup del database in un'area secondaria di propria preferenza. Consente anche di leggere da tale area secondaria, se necessario. I backup manuali dei database non sono supportati e la piattaforma negherà qualsiasi richiesta.
I backup del database vengono eseguiti in base a una pianificazione specifica:
- Completo: una volta alla settimana
- Differenziale: ogni 12 ore
- Log: ogni 5-10 minuti a seconda dell'uso del log delle transazioni
Questa pianificazione di backup deve soddisfare le esigenze della maggior parte degli obiettivi del punto di ripristino/ora (RPO/RTO), ma ogni cliente deve valutare se soddisfa i requisiti aziendali.
Sono disponibili diverse opzioni per il ripristino di un database. A causa della natura di Platform as a Service, non è possibile ripristinare manualmente un database usando metodi convenzionali, ad esempio l'emissione del comando RESTORE DATABASET-SQL .
Indipendentemente dal metodo di ripristino implementato, non è possibile eseguire il ripristino in un database esistente. Se è necessario ripristinare un database, è necessario eliminare o rinominare il database esistente prima di avviare il processo di ripristino. Tenere inoltre presente che, a seconda del livello di servizio della piattaforma, i tempi di ripristino non sono garantiti e potrebbero variare. È consigliabile testare il processo di ripristino per ottenere una metrica di base per quanto tempo potrebbe richiedere un ripristino.
Eseguire il ripristino con il portale di Azure: Usando il portale di Azure è possibile ripristinare un database nello stesso server logico per il database SQL di Azure oppure è possibile usare il ripristino per creare un nuovo database in un nuovo server in qualsiasi area di Azure.
Eseguire il ripristino con i linguaggi di scripting: Sia PowerShell che l'interfaccia della riga di comando di Azure possono essere usate per ripristinare un database.
Annotazioni
Il backup di sola copia in Archiviazione BLOB di Azure è disponibile per Istanza gestita di SQL. Il database SQL non supporta questa funzionalità.
Per altre informazioni sui backup automatizzati, vedere Backup automatizzati - Database SQL di Azure e Istanza gestita di SQL di Azure.
Replica geografica attiva
La replica geografica è una funzionalità di continuità aziendale che replica in modo asincrono un database fino a quattro repliche secondarie. Quando si esegue il commit delle transazioni nel database primario (e nelle relative repliche all'interno della stessa area), le transazioni vengono inviate ai database secondari per la riproduzione. Poiché questa comunicazione viene eseguita in modo asincrono, l'applicazione chiamante non deve attendere che la replica secondaria esemetta il commit della transazione prima che SQL Server restituisca il controllo al chiamante.
I database secondari sono leggibili e possono essere usati per eseguire l'offload dei carichi di lavoro di sola lettura, liberando così le risorse per i carichi di lavoro transazionali nel database primario o posizionando i dati più vicini agli utenti finali. Inoltre, i database secondari possono trovarsi nella stessa area del database primario o in un'altra area di Azure
È possibile avviare un failover manualmente dall'utente o a livello di codice dall'applicazione. Se si verifica un failover, è possibile aggiornare le stringhe di connessione dell'applicazione in modo da riflettere il nuovo endpoint di quello che è ora il database primario.
Gruppi di failover
I gruppi di failover si basano sulla tecnologia usata nella replica geografica, ma forniscono un singolo endpoint per la connessione. Il motivo principale per cui si usano i gruppi di failover è che forniscono endpoint che possono essere utilizzati per instradare il traffico alla replica appropriata. L'applicazione può quindi connettersi dopo un failover senza modifiche alla stringa di connessione.