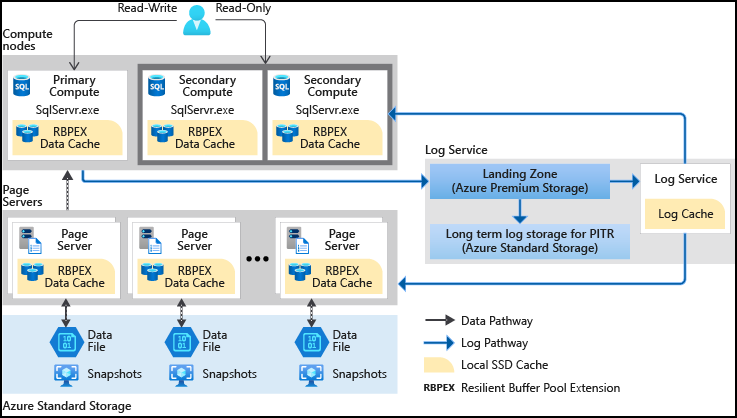
Informazioni sull'iperscalabilità per i database SQL
Il database SQL di Azure era storicamente limitato a 4 TB di spazio di archiviazione per ogni database a causa di vincoli di infrastruttura fisica. Tuttavia, il livello di servizio Hyperscale rivoluziona questa situazione consentendo ai database di superare i 100 TB. Hyperscale usa tecniche di ridimensionamento orizzontale per aggiungere nodi di calcolo man mano che aumentano le dimensioni dei dati. Anche se il costo di Hyperscale è simile al database SQL di Azure, è previsto un costo aggiuntivo per terabyte di archiviazione. È importante notare che una volta convertito un database in Hyperscale, non può essere ripristinato in un database SQL di Azure standard.
Hyperscale è ideale per la maggior parte dei carichi di lavoro aziendali, offrendo flessibilità e prestazioni elevate con risorse di calcolo e archiviazione scalabili in modo indipendente. Separa il motore di elaborazione delle query dai componenti che forniscono archiviazione e durabilità a lungo termine, consentendo la scalabilità uniforme della capacità di archiviazione in base alle esigenze.
Il livello di servizio Hyperscale, parte del modello di acquisto basato su vCore, è l'opzione più recente e scalabile, superando significativamente i limiti dei livelli Utilizzo generico e Business Critical.
Vantaggi
Il livello di servizio Hyperscale elimina molte delle limitazioni pratiche tradizionalmente associate ai database cloud. Le risorse di un singolo nodo vincolano la maggior parte dei database, ma i database Hyperscale non hanno tali restrizioni. Con l'architettura di archiviazione flessibile, l'archiviazione si espande in base alle esigenze e non esiste alcuna dimensione massima predefinita. La fatturazione viene addebitata solo per la capacità usata. Per i carichi di lavoro a elevato utilizzo di lettura, Hyperscale offre scalabilità orizzontale rapida effettuando il provisioning di più repliche per gestire le operazioni di lettura.
Inoltre, il tempo necessario per i backup o le operazioni di ridimensionamento del database non dipende più dal volume di dati. È possibile eseguire immediatamente il backup dei database Hyperscale ed è possibile ridimensionare un database con decine di terabyte in pochi minuti. Questa flessibilità garantisce che le scelte di configurazione iniziali non vincolano l'utente. Hyperscale offre inoltre ripristini rapidi del database, completando in minuti anziché ore o giorni.
Hyperscale offre scalabilità rapida in base alle esigenze dei carichi di lavoro.
Aumento/riduzione delle prestazioni: È possibile aumentare o ridurre le risorse di calcolo primarie, ad esempio CPU e memoria, in modo rapido ed efficiente. Poiché l'archiviazione è condivisa, queste operazioni di ridimensionamento non dipendono dal volume di dati del database.
Aumento/riduzione delle prestazioni: È possibile creare più repliche di calcolo per gestire le richieste di lettura, offload efficace del carico di lavoro di lettura dal calcolo primario. Queste repliche fungono anche da hot standby, pronte per assumere il controllo in caso di errore di calcolo primario.
Il provisioning di più repliche di calcolo è un'operazione rapida online. Per connettersi a queste repliche di sola lettura, impostare l'argomento ApplicationIntent nella stringa di connessione su ReadOnly. Le connessioni con la finalità dell'applicazione ReadOnly vengono indirizzate automaticamente a una delle repliche di calcolo di sola lettura.
Considerazioni sulla sicurezza
La sicurezza per il livello di servizio Hyperscale offre le stesse funzionalità affidabili di altri livelli di database SQL di Azure. Usa un approccio di difesa a più livelli, fornendo una protezione completa dai livelli più esterni verso l'interno.
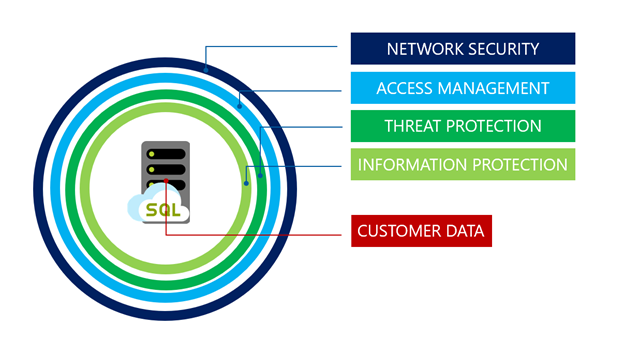
Sicurezza di rete è il primo livello di difesa, utilizzando regole del firewall IP per controllare l'accesso in base all'indirizzo IP di origine. Inoltre, le regole del firewall di rete virtuale consentono la comunicazione da subnet selezionate all'interno di una rete virtuale.
Gestione degli accessi viene fornito tramite i metodi di autenticazione seguenti per verificare l'identità utente:
- Autenticazione SQL
- Autenticazione Microsoft Entra
- Autenticazione di Windows per le entità di Microsoft Entra
Hyperscale del database SQL di Azure supporta anche Row-Level Security (RLS), consentendo ai clienti di controllare l'accesso a righe specifiche in una tabella di database in base alle caratteristiche utente, ad esempio l'appartenenza al gruppo o il contesto di esecuzione.
Threat Protection include solide funzionalità di controllo e rilevamento delle minacce. Il controllo del database SQL e dell'istanza gestita di SQL tiene traccia delle attività del database e consente di mantenere la conformità agli standard di sicurezza registrando gli eventi in un log di controllo in un account di archiviazione di Azure di proprietà del cliente. Advanced Threat Protection analizza i log per rilevare comportamenti insoliti e potenziali minacce ai database. Genera avvisi per attività sospette, ad esempio SQL injection, potenziali infiltrazioni di dati, attacchi di forza bruta e anomalie nei modelli di accesso che possono indicare escalation dei privilegi o l'uso di credenziali violate.
Information Protection viene fornito nei modi seguenti:
- Transport Layer Security (crittografia in transito)
- Transparent Data Encryption (TDE - crittografia inattiva)
- Gestione delle chiavi con Azure Key Vault
- Always Encrypted (crittografia in uso)
- Maschera dati dinamica
Considerazioni sulle prestazioni
Il livello di servizio Hyperscale è progettato per i clienti con database SQL Server locali di grandi dimensioni che vogliono modernizzare passando al cloud e per coloro che usano già il database SQL di Azure che devono espandere notevolmente la capacità del database. È anche ideale per i clienti che cercano prestazioni e scalabilità elevate.
Le principali funzionalità di prestazioni di Hyperscale includono:
- Backup di database quasi istantanei usando snapshot di file archiviati nell'archiviazione BLOB di Azure, senza influire sulle risorse di calcolo.
- Ripristini rapidi del database in base agli snapshot dei file, completando in minuti anziché ore o giorni, indipendentemente dalle dimensioni dei dati.
- Prestazioni complessive migliorate a causa di una maggiore velocità effettiva del log delle transazioni e tempi di commit delle transazioni più veloci, indipendentemente dai volumi di dati.
- Scalabilità orizzontale rapida effettuando il provisioning di una o più repliche di sola lettura per eseguire l'offload dei carichi di lavoro di lettura e fungere da hot standby.
- Aumento rapido delle prestazioni, che consente di aumentare rapidamente le risorse di calcolo per gestire carichi di lavoro pesanti e di ridimensionarli quando non è necessario.
Distribuzione di Hyperscale per il database SQL di Azure
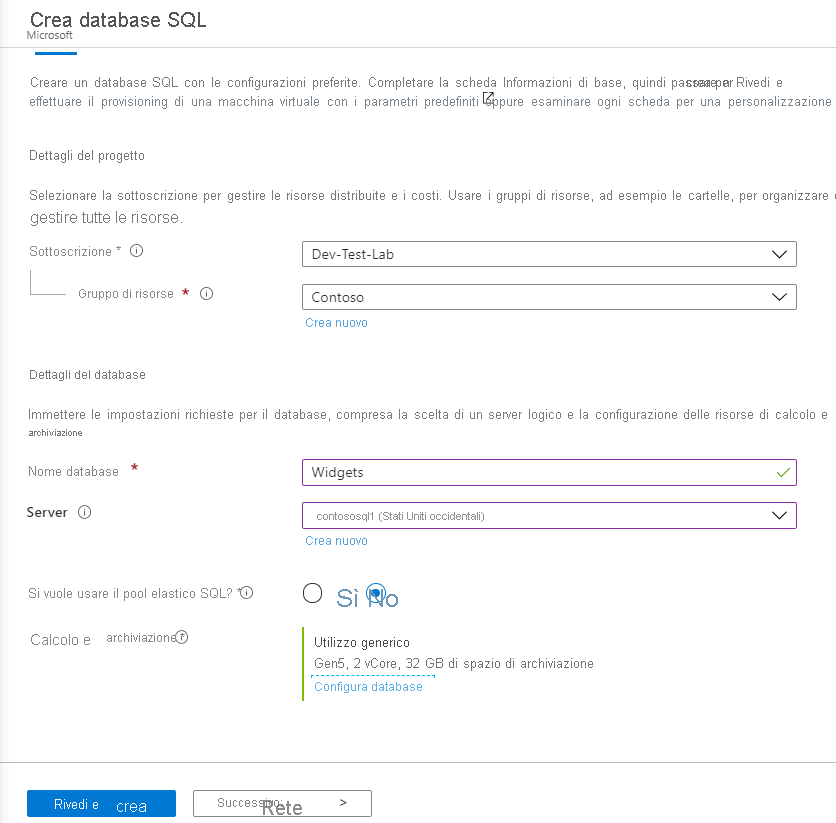
Per distribuire un database SQL di Azure con il livello Hyperscale, seguire lo stesso processo di distribuzione di un normale database SQL, con le differenze seguenti:
In Calcolo e archiviazione selezionare il collegamento Configura database.
Per il campo Livello di servizio, selezionare Hyperscale.
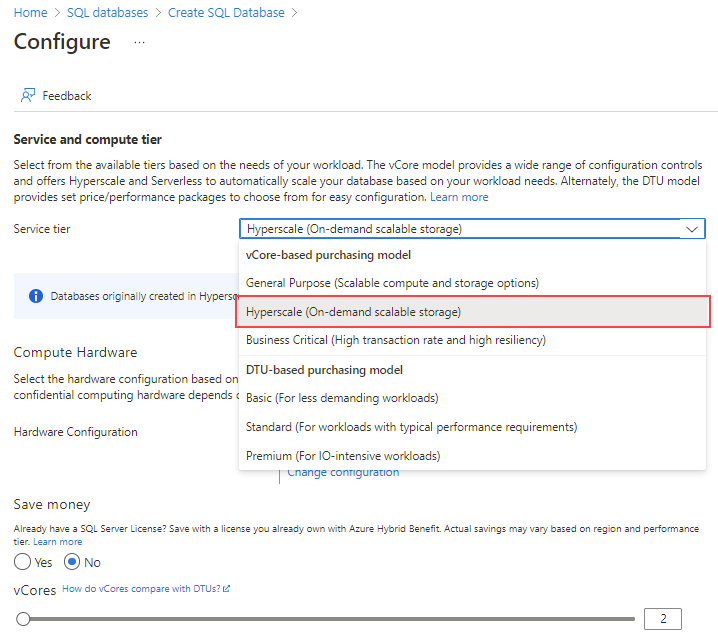
Esaminare le configurazioni hardware disponibili e selezionare la configurazione più appropriata per il database.
Facoltativamente, esaminare le altre schede per apportare modifiche, se necessario.
Nella scheda Rivedi e crea selezionare Crea.

