Definire il problema
A partire dal primo passaggio, si vuole definire il problema che il modello deve risolvere, comprendendo:
- Quale deve essere l'output del modello.
- Quale tipo di attività di Machine Learning si usa.
- Quali criteri rendono un modello riuscito.
A seconda dei dati disponibili e dell'output del modello previsto, è possibile identificare l'attività di Machine Learning. L'attività determina i tipi di algoritmi che è possibile usare per eseguire il training del modello.
Alcune attività comuni di Machine Learning sono:
- Classificazione: stimare un valore categorico.
- Regressione: stimare un valore numerico.
- Previsione di serie temporali: stimare i valori numerici futuri in base ai dati delle serie temporali.
- Visione artificiale: classificare le immagini o rilevare oggetti nelle immagini.
- Elaborazione del linguaggio naturale (NLP): estrarre informazioni dettagliate dal testo.
Per eseguire il training di un modello, è disponibile un set di algoritmi che è possibile usare, a seconda dell'attività da eseguire. Per valutare il modello, è possibile calcolare le metriche delle prestazioni, ad esempio l'accuratezza o la precisione. Le metriche disponibili dipendono anche dall'attività che il modello deve eseguire e consentono di decidere se un modello ha esito positivo nell'attività.
Esplorare un esempio
Si consideri uno scenario in cui si vuole determinare se i pazienti hanno il diabete. Il problema che si sta tentando di risolvere e il tipo di dati disponibili determinano l'attività di Machine Learning scelta. In questo caso, i dati disponibili sono altri punti dati sanitari dei pazienti. Possiamo rappresentare l'output che vogliamo come informazioni categoriche che indicano se il paziente ha o meno il diabete. Di conseguenza, l'attività di Machine Learning è la classificazione.
Comprendere l'intero processo prima di iniziare offre l'opportunità di eseguire il mapping delle decisioni necessarie per progettare una soluzione di Machine Learning efficace. Di seguito è riportato un diagramma che illustra un modo per affrontare il problema di identificare il diabete in un paziente. Nel diagramma i dati vengono preparati, suddivisi ed sottoposti a training usando algoritmi specifici. Successivamente, il modello viene valutato riguardo la qualità.
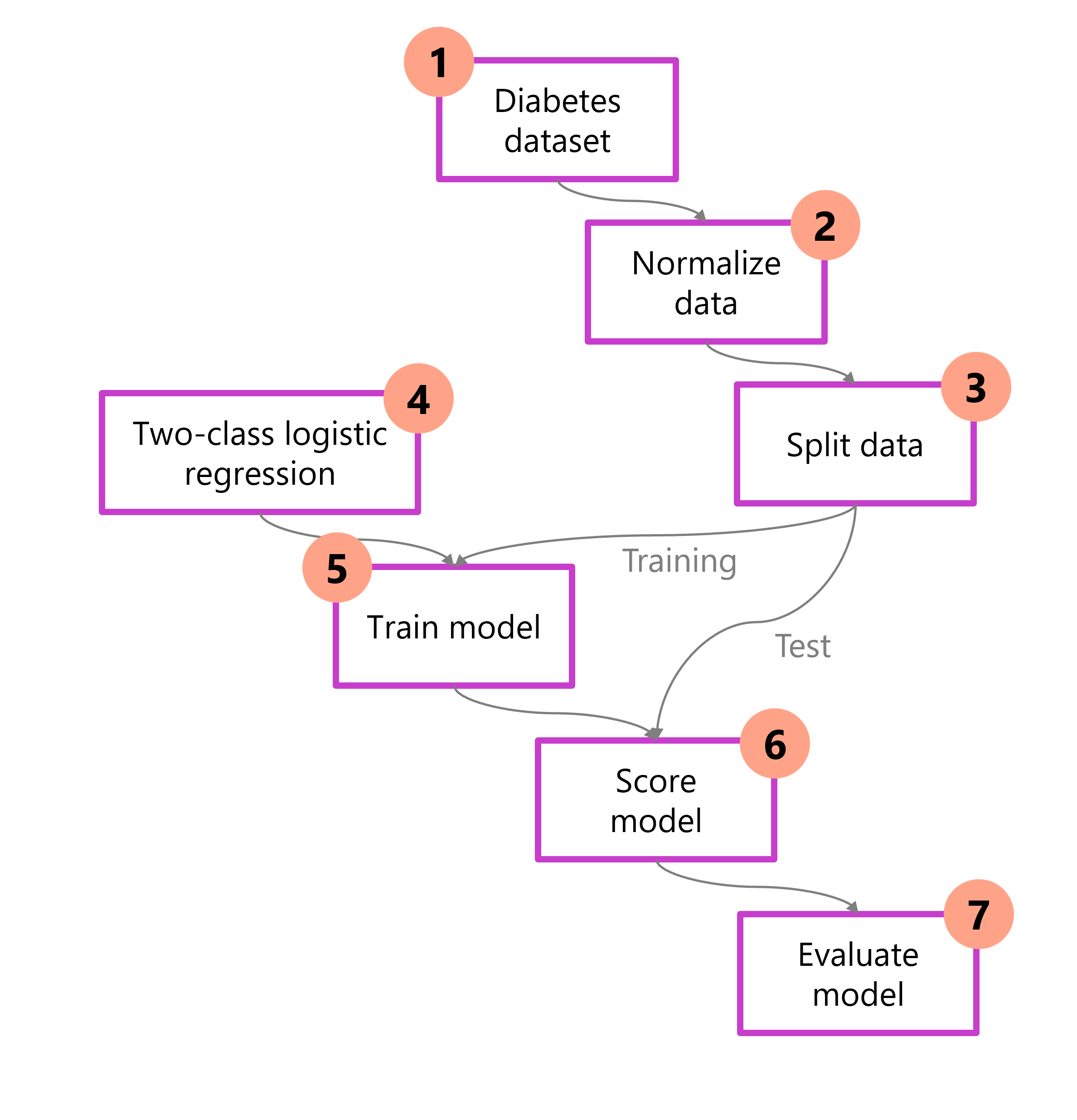
- Caricare i dati: importare ed esaminare il set di dati.
- Pre-elaborare i dati: normalizzare e pulire per coerenza.
- Dividere i dati: separare in insiemi di addestramento e di prova.
- Scegliere il modello: selezionare e configurare un algoritmo.
- Eseguire il training del modello: Apprendere criteri dai dati di training.
- Modello di punteggio: generare stime sui dati di test.
- Valutare: calcolare le metriche delle prestazioni.
Il training di un modello di Machine Learning è spesso un processo iterativo, in cui ognuno di questi passaggi viene eseguito più volte per trovare il modello dalle prestazioni migliori. Si esaminerà quindi il processo di preparazione dei dati per lo sviluppo di una soluzione di Machine Learning.