Esplorare l'inserimento dati nelle pipeline
Ora che si ha maggiore familiarità con l'architettura di una soluzione di data warehousing su larga scala e con alcune delle tecnologie di elaborazione distribuite che possono essere usate per gestire grandi volumi di dati, è possibile analizzare la modalità di inserimento dei dati in un archivio dati analitico da una o più origini.
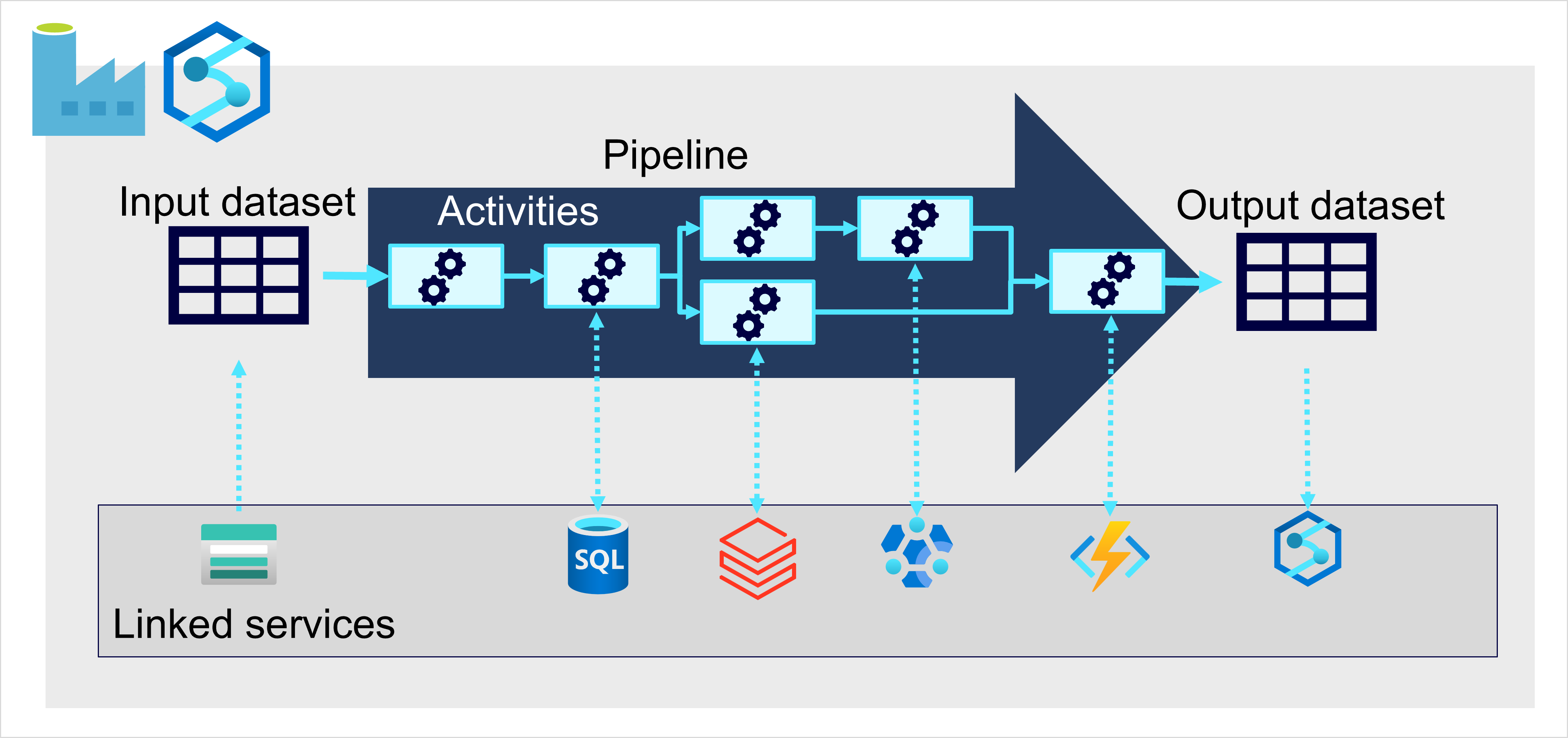
In Azure, l'inserimento di dati su larga scala è implementato meglio creando pipeline che orchestrano i processi ETL. È possibile creare ed eseguire pipeline con Azure Data Factory oppure usare la funzionalità della pipeline in Microsoft Fabric se si vogliono gestire tutti i componenti della soluzione di data warehousing in un'area di lavoro unificata.
In entrambi i casi, le pipeline sono costituite da una o più attività che operano sui dati. Un set di dati di input fornisce i dati di origine e le attività possono essere definite come flusso di dati che modifica in modo incrementale i dati finché non viene prodotto un set di dati di output. Le pipeline usano servizi collegati per caricare ed elaborare i dati, consentendo di usare la tecnologia appropriata per ogni passaggio del flusso di lavoro. Ad esempio, è possibile usare un servizio collegato archivio BLOB di Azure per inserire il set di dati di input e quindi usare servizi come database SQL di Azure per eseguire una stored procedure che cerca i valori di dati correlati, prima di eseguire un'attività di elaborazione dati in Azure Databricks o applicare logica personalizzata usando una funzione di Azure. Infine, è possibile salvare il set di dati di output in un servizio collegato, ad esempio Microsoft Fabric. Le pipeline possono anche includere alcune attività predefinite, che non richiedono un servizio collegato.