Esplorare l'hub Monitoraggio
Usare l'hub Monitoraggio per visualizzare le esecuzioni di pipeline e trigger, lo stato dei diversi runtime di integrazione in esecuzione, i processi Apache Spark, le richieste SQL e le attività di debug del flusso di dati.
Selezionare l'hub Monitoraggio.
L'hub Monitoraggio è la prima risorsa da considerare per eseguire il debug dei problemi e per ottenere informazioni dettagliate sull'utilizzo delle risorse. È possibile visualizzare una cronologia di tutte le attività che si verificano nell'area di lavoro e quelle attualmente attive.
Mostra tutte le categorie di monitoraggio raggruppate in Integrazione e Attività.
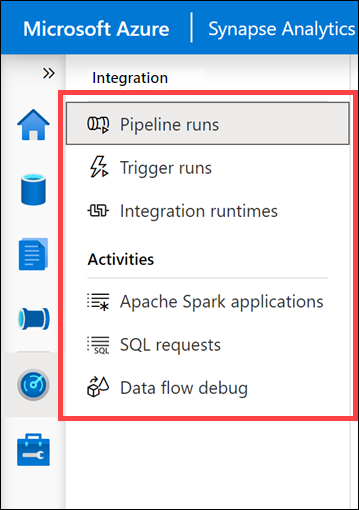
- Pipeline runs (Esecuzioni delle pipeline) mostra tutte le attività di esecuzione della pipeline. È possibile visualizzare i dettagli dell'esecuzione, inclusi gli input e gli output per le attività ed eventuali messaggi di errore. Da qui è anche possibile arrestare una pipeline, se necessario.
- Trigger runs (Esecuzioni dei trigger) mostra tutte le esecuzioni delle pipeline causate da trigger automatici. È possibile creare trigger che vengono eseguiti in base a una pianificazione ricorrente o a una finestra a cascata. È anche possibile creare trigger basati su eventi che eseguono una pipeline ogni volta che viene creato o eliminato un BLOB in un contenitore di archiviazione.
- Integration runtimes (Runtime di integrazione) mostra lo stato di tutti i runtime di integrazione testati internamente e di quelli di Azure.
- Apache Spark applications (Applicazioni Apache Spark) mostra tutte le applicazioni Spark in esecuzione o eseguite nell'area di lavoro.
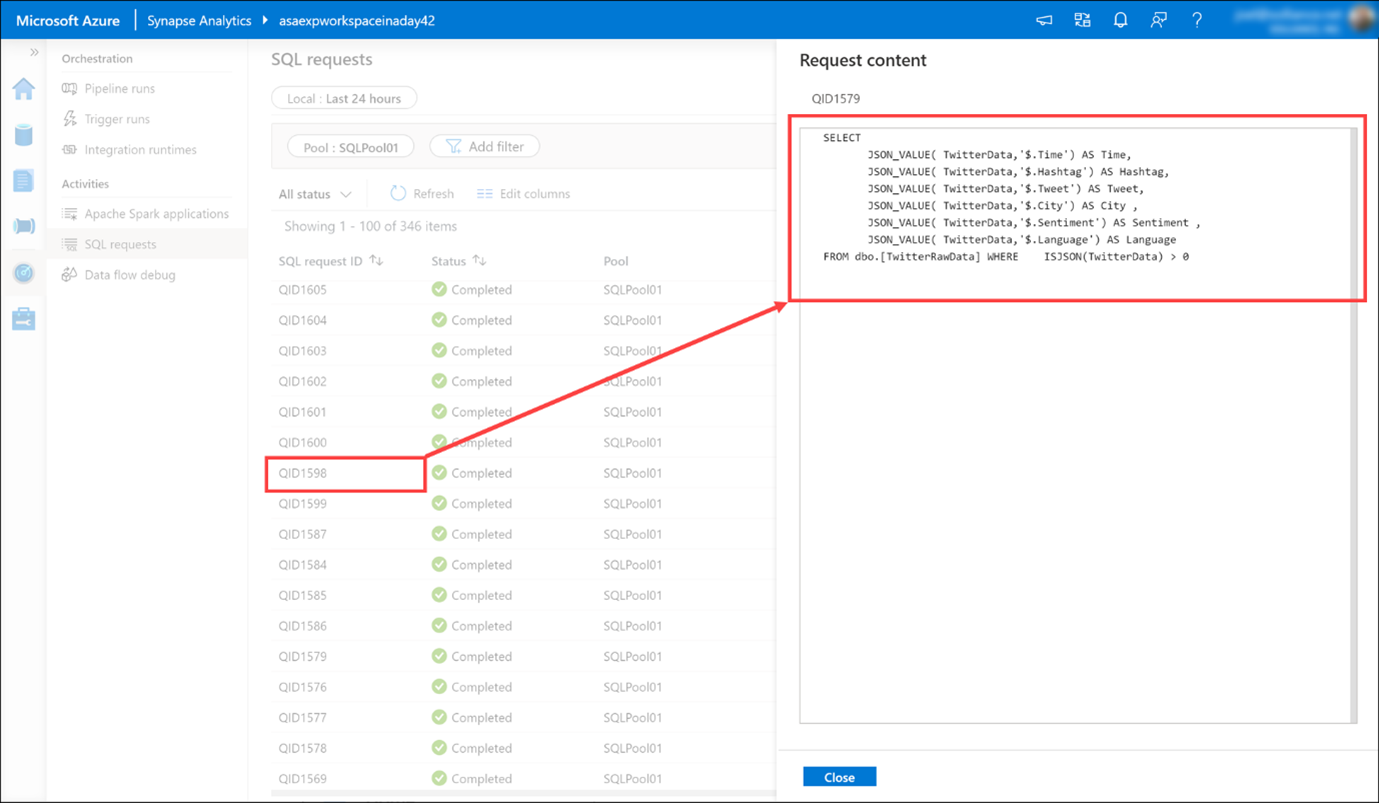
- SQL requests (Richieste SQL) mostra tutti gli script SQL eseguiti direttamente dall'utente o da un altro utente oppure eseguiti in altri modi, ad esempio da un'esecuzione della pipeline.
- Data flow debug (Debug del flusso di dati) mostra le sessioni di debug attive e precedenti. Durante la creazione di un flusso di dati, è possibile abilitare il debugger ed eseguire il flusso di dati senza dover aggiungerlo a una pipeline e attivare un'istruzione execute. L'uso del debugger accelera e semplifica il processo di sviluppo. Poiché il debugger richiede un cluster Spark attivo, possono essere necessari alcuni minuti prima di poterlo usare dopo averlo abilitato.
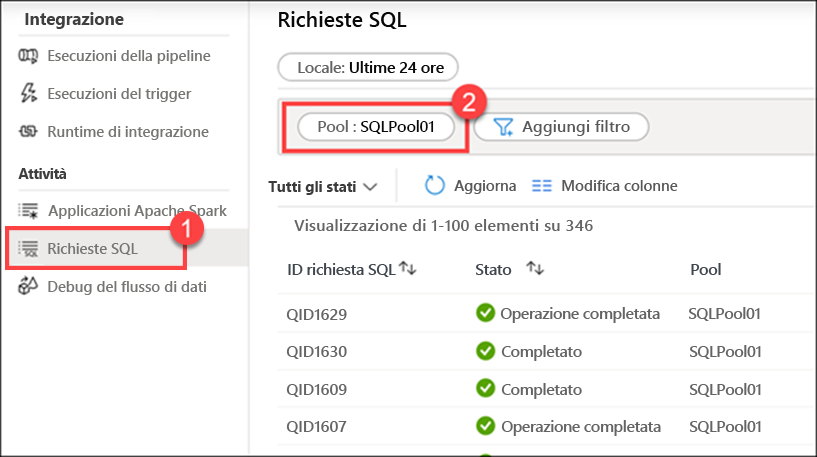
Selezionare SQL requests (1) (Richieste SQL) e quindi passare al pool SQLPool01 (2) per visualizzare l'elenco delle richieste SQL.
Passare il puntatore del mouse su una richiesta SQL, quindi selezionare l'icona Request content (Contenuto della richiesta) per visualizzare la richiesta SQL inviata al pool SQL. Potrebbe essere necessario provarne alcune prima di trovarne una con contenuto interessante.
È possibile visualizzare altri dettagli.