Esplorare l'hub Gestione
L'hub Gestione consente di eseguire alcune delle stesse azioni viste nel portale di Azure, ad esempio la gestione dei pool SQL e Spark. Tuttavia, in questo hub è possibile eseguire molte altre azioni che non è possibile eseguire altrove, ad esempio la gestione di servizi collegati e dei runtime di integrazione e la creazione di trigger di pipeline.
Selezionare l'hub Gestione.
Vengono visualizzate tutte le categorie di gestione raggruppate in Analytics pools (Pool di analisi), External connections (Connessioni esterne), Integration (Integrazione) e Security (Sicurezza).
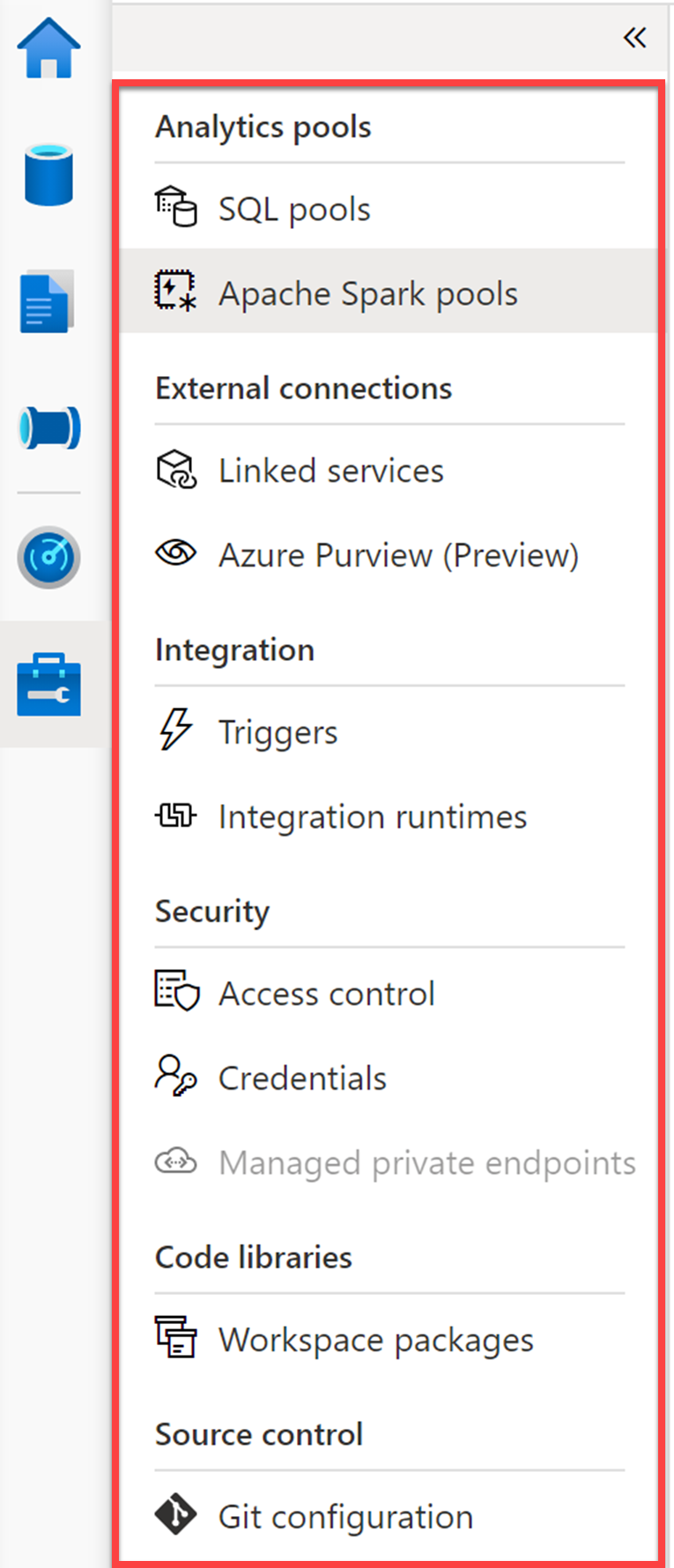
- SQL pools (Pool SQL). Elenca i pool SQL di cui è stato effettuato il provisioning e i pool serverless SQL su richiesta per l'area di lavoro. È possibile aggiungere nuovi pool o passare il puntatore del mouse su un pool SQL per sospendere o ridimensionare il pool. È consigliabile sospendere un pool SQL per ridurre i costi quando non è in uso.
- Apache Spark pools (Pool di Apache Spark). Consente di gestire i pool di Spark configurando le impostazioni di sospensione automatica e scalabilità automatica. Da questo riquadro è possibile effettuare il provisioning di un nuovo pool di Apache Spark.
- Linked services (Servizi collegati). Consente di gestire le connessioni alle risorse esterne. Qui è possibile visualizzare i servizi collegati per l'account di archiviazione del data lake, Azure Key Vault, Power BI e Synapse Analytics. Attività: selezionare + New (Nuovo) per visualizzare quanti tipi di servizi collegati si possono aggiungere.
- Azure Purview (Preview) (Azure Purview - Anteprima). Fornisce l'integrazione con Azure Purview per offrire governance e derivazione dei dati all'interno di Azure Synapse Analytics.
- Triggers (Trigger). Fornisce una posizione centrale per la creazione o la rimozione di trigger della pipeline. In alternativa, è possibile aggiungere trigger dalla pipeline.
- Integration runtimes (Runtime di integrazione). Elenca il runtime di integrazione per l'area di lavoro, che funge da infrastruttura di calcolo per le funzionalità di integrazione dei dati, ad esempio quelle fornite dalle pipeline. Attività: passare il puntatore del mouse sui runtime di integrazione per visualizzare i collegamenti per il monitoraggio, la scrittura di codice e l'eliminazione (se applicabile). Fare clic su un collegamento al codice per mostrare come è possibile modificare i parametri in formato JSON, inclusa l'impostazione TTL (Durata) per il runtime di integrazione.
- Controllo dell'accesso. Qui è possibile aggiungere e rimuovere utenti per uno dei tre gruppi di sicurezza: amministratore dell'area di lavoro, amministratore SQL e amministratore Apache Spark per Azure Synapse Analytics.
- Credenziali. Contiene oggetti con informazioni di autenticazione utilizzabili da Azure Synapse Analytics.
- Managed private endpoints (Endpoint privati gestiti). Qui vengono gestiti gli endpoint privati che usano un indirizzo IP privato dall'interno di una rete virtuale per connettersi a un servizio di Azure o al proprio servizio di collegamento privato. Le connessioni che usano endpoint privati elencati qui forniscono l'accesso agli endpoint dell'area di lavoro di Synapse (SQL, SqlOndemand e Dev).
- Workspace packages (Pacchetti dell'area di lavoro). I pacchetti dell'area di lavoro possono essere codice personalizzato o una versione specifica di una libreria open source che si vuole usare nei pool di Apache Spark contenuti nell'area di lavoro di Azure Synapse Analytics.
- Git Configuration (Configurazione GIT). Consente di connettere l'area di lavoro usata a un repository Git per abilitare il controllo del codice sorgente.