Esplorare l'hub Dati
L'hub Dati offre la possibilità di esplorare e interagire con i dati di origine e i servizi collegati, come illustrato nei passaggi seguenti.
Sul lato sinistro di Azure Synapse Studio fare clic sull'hub Dati.
L'hub Dati è l'hub da cui è possibile accedere ai database serverless SQL e ai database del pool SQL di cui è stato effettuato il provisioning che si trovano nell'area di lavoro, nonché alle origini dati esterne, ad esempio agli account di archiviazione e ad altri servizi collegati.
Nella scheda Workspace (2) (Area di lavoro) dell'hub Dati (1)espandere il pool SQL SQLPool01 (3) sotto Databases (Database).
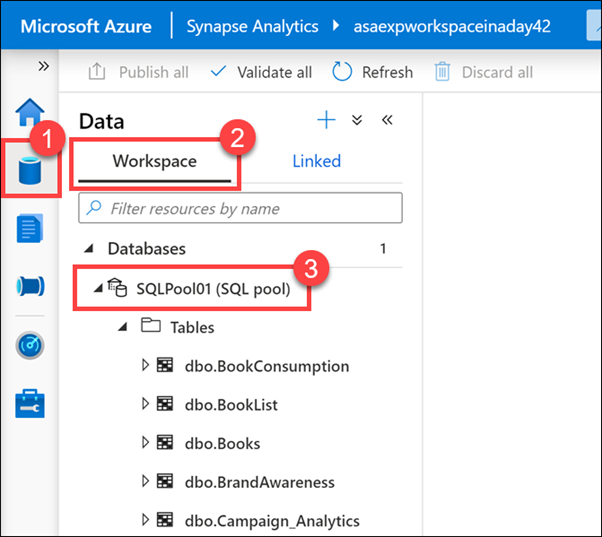
Espandere Tables (Tabelle) e Programmability/Stored procedures (Programmabilità/stored procedure).
Le tabelle elencate nel pool SQL archiviano i dati provenienti da più origini, ad esempio SAP Hana, X, il database SQL di Azure e i file esterni copiati da una pipeline di orchestrazione. Synapse Analytics offre la possibilità di combinare queste origini dati per l'analisi e la creazione di report, il tutto in un'unica posizione.
Vengono inoltre visualizzati i componenti di database comuni, ad esempio le Stored procedure. È possibile eseguire le stored procedure usando gli script T-SQL o come parte di una pipeline di orchestrazione.
Selezionare la scheda Linked (Collegati), espandere il gruppo Azure Data Lake storage Gen2 e quindi l'archivio primario per l'area di lavoro.
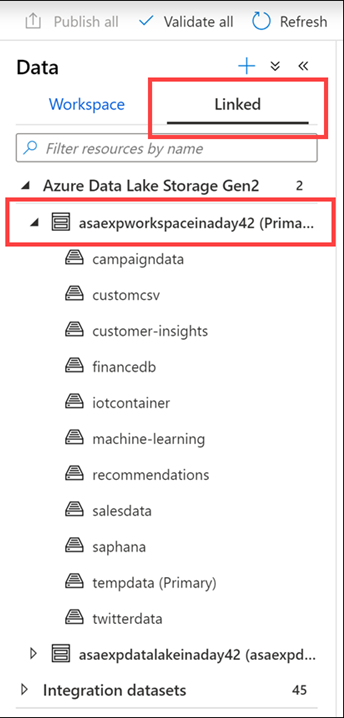
A ogni area di lavoro Synapse è associato un account di ADLS Gen2 primario. Questo funge da data lake, che è un'ottima posizione per archiviare file flat, ad esempio file copiati da archivi dati locali, dati esportati o dati copiati direttamente da servizi e applicazioni esterni, dati di telemetria e così via. Tutto si trova in un'unica posizione.
In questo esempio sono disponibili diversi contenitori con file e cartelle che è possibile esplorare e usare dall'interno dell'area di lavoro. Qui è possibile visualizzare dati delle campagne di marketing, file CSV, informazioni finanziarie importate da un database esterno, risorse di Machine Learning, dati di telemetria di dispositivi IoT, dati di SAP HANA e tweet, solo per citarne alcuni.
Ora che tutti questi dati si trovano in una sola posizione, è possibile iniziare a visualizzarne l'anteprima proprio da qui.
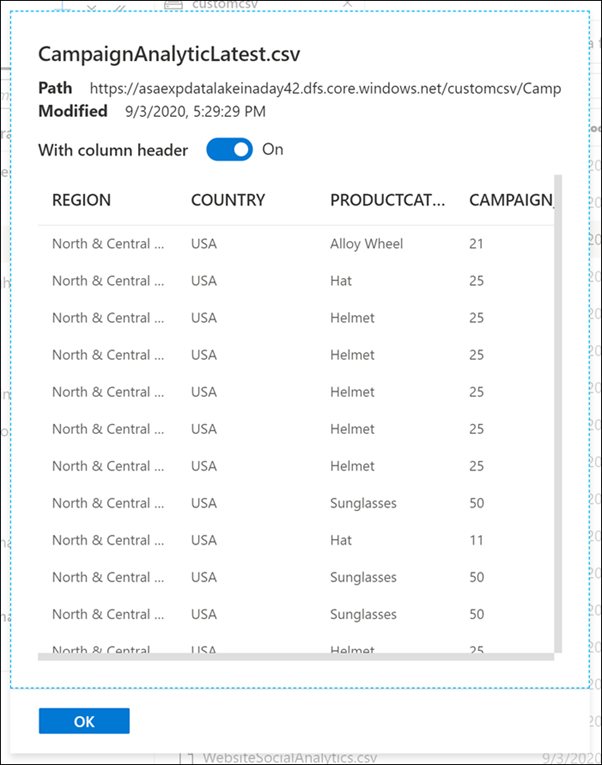
Si prendano ad esempio i dati delle campagne di marketing.
Selezionare il contenitore di archiviazione customcsv.
È possibile visualizzare in anteprima i dati delle campagne per comprendere i nuovi nomi delle campagne.
Fare clic con il pulsante destro del mouse sul file CampaignAnalyticsLatest.csv(1) e quindi selezionare Preview (2) (Anteprima).
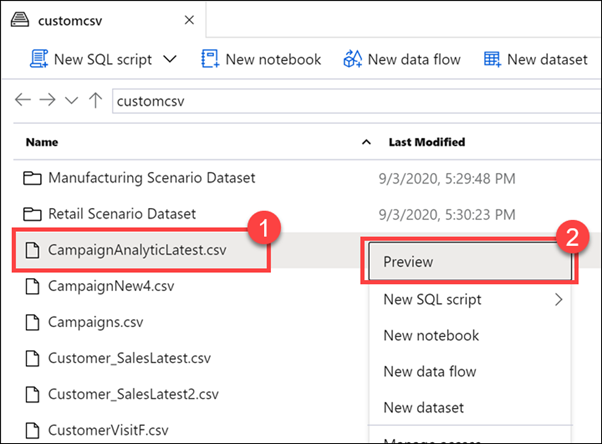
Le funzionalità di Esplora file consentono di trovare rapidamente i file ed eseguire azioni su di essi, ad esempio visualizzare in anteprima il contenuto dei file, generare nuovi notebook o script SQL per accedere al file, creare un nuovo flusso di dati o un nuovo set di dati e gestire il file.