Informazioni sulla distribuzione dei dati
Comprendere la distribuzione dei dati è essenziale per un'efficace analisi dei dati, visualizzazione e compilazione di modelli.
Se un set di dati ha una distribuzione asimmetrica, significa che i punti dati non vengono distribuiti uniformemente e tendono a allinearsi più verso destra o sinistra. Ciò può causare una stima imprecisa di punti dati da gruppi sottorappresentati o ottimizzati in base a una metrica inappropriata.
Importanza della distribuzione dei dati
Di seguito sono riportate le aree chiave in cui la comprensione della distribuzione dei dati può migliorare l'accuratezza dei modelli di Machine Learning.
| Passo | Descrizione |
|---|---|
| Analisi esplorativa dei dati (EDA) | Comprendere la distribuzione dei dati semplifica l'esplorazione di un nuovo set di dati e la ricerca di modelli. |
| Pre-elaborazione dei dati | Alcune tecniche di pre-elaborazione, come la normalizzazione o la standardizzazione, vengono usate per rendere i dati più normalmente distribuiti, che è un presupposto comune in molti modelli. |
| Selezione del modello | I diversi modelli fanno presupposti diversi sulla distribuzione dei dati. Ad esempio, alcuni modelli presuppongono che i dati vengano normalmente distribuiti e che non funzionino correttamente se questo presupposto viene violato. |
| Migliorare le prestazioni del modello | La trasformazione della variabile di destinazione per ridurre l'asimmetria può linearizzare la destinazione, utile per molti modelli. Ciò può ridurre l'intervallo di errori e potenzialmente migliorare le prestazioni del modello. |
| Pertinenza del modello | Una volta distribuito un modello nell'ambiente di produzione, è importante che rimanga rilevante nel contesto dei dati più recenti. Se si verifica un'asimmetria dei dati, ovvero la distribuzione dei dati cambia nell'ambiente di produzione rispetto a quello usato durante il training, il modello potrebbe uscire dal contesto. |
Comprendere la distribuzione dei dati può migliorare il processo di compilazione del modello. Consente di stabilire presupposti più accurati identificando la media, la diffusione e l'intervallo di una variabile casuale nelle funzionalità e nella destinazione.
Verranno ora esaminati alcuni dei tipi di distribuzione dei dati più comuni, ad esempio le distribuzioni normali, binomiali e uniformi.
Distribuzione normale
Una distribuzione normale è rappresentata da due parametri: la media e la deviazione standard. La media indica dove la curva a campana è centrata e la deviazione standard indica la distribuzione della distribuzione.
Di seguito è riportato un esempio di una normale funzionalità distribuita. Il codice seguente genera i dati per la var funzionalità a scopo dimostrativo.
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# Set the mean and standard deviation
mu, sigma = 0, 0.1
# Generate a normally distributed variable
var = np.random.normal(mu, sigma, 1000)
# Create a histogram of the variable using seaborn's histplot
sns.histplot(var, bins=30, kde=True)
# Add title and labels
plt.title('Histogram of Normally Distributed Variable')
plt.xlabel('Value')
plt.ylabel('Frequency')
# Show the plot
plt.show()
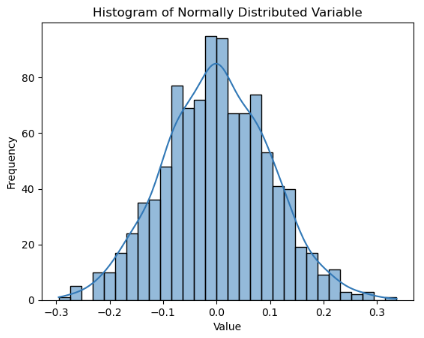
Si noti che la var caratteristica è distribuita normalmente, in cui la media e la mediana (50% percentile) devono essere più o meno uguali. Per le distribuzioni asimmetriche, la media tende a sporgersi verso la coda più pesante.
Tuttavia, questi sono controlli euristici e la determinazione effettiva vengono eseguiti usando test statistici specifici come il test Shapiro-Wilk o kolmogorov-Smirnov test per la normalità.
Distribuzione binomiale
Supponiamo di voler comprendere quanto bene venga osservata una particolare caratteristica in un gruppo di pinguini.
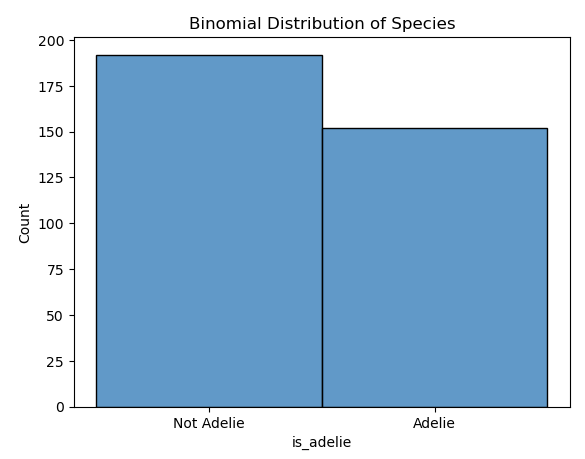
Si decide di esaminare un set di dati di 200 pinguini per verificare se sono della specie Adelie . Si tratta di un problema di distribuzione binomiale perché esistono due possibili risultati (Adelie o non Adelie), un numero fisso di prove (200 pinguini) e ogni prova è indipendente da altri.
Dopo aver analizzato il set di dati, si scopre che 150 pinguini sono della specie Adelie .
Sapendo che i dati seguono una distribuzione binomiale, è possibile eseguire stime su set di dati o gruppi futuri di pinguini. Ad esempio, se si studia un altro gruppo di 200 pinguini, ci si può aspettare circa 150 essere della specie Adelie.
Il codice Python seguente traccia un istogramma della is_adelie variabile binomiale. L'argomento discrete=True in sns.histplot garantisce che i bin vengano trattati come intervalli discreti. Ciò significa che ogni barra nell'istogramma corrisponde esattamente a una categoria o valore booleano, rendendo il tracciato più facile da interpretare.
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# Load the Penguins dataset from seaborn
penguins = sns.load_dataset('penguins')
# Create a binomial variable for 'species'
penguins['is_adelie'] = np.where(penguins['species'] == 'Adelie', 1, 0)
# Plot the distribution of 'is_adelie'
sns.histplot(data=penguins, x='is_adelie', bins=2, discrete=True)
plt.title('Binomial Distribution of Species')
plt.xticks([0, 1], ['Not Adelie', 'Adelie'])
plt.show()
Distribuzione uniforme
Una distribuzione uniforme, nota anche come distribuzione rettangolare, è un tipo di distribuzione di probabilità in cui tutti i risultati sono ugualmente probabili. Ogni intervallo della stessa lunghezza sul supporto della distribuzione ha la stessa probabilità.
import numpy as np
import matplotlib.pyplot as plt
# Generate a uniform distribution
uniform_data = np.random.uniform(-1, 1, 1000)
# Plot the distribution
plt.hist(uniform_data, bins=20, density=True)
plt.title('Uniform Distribution')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.show()
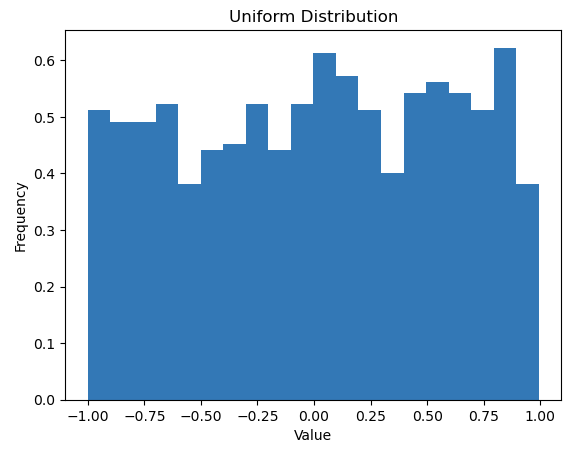
In questo codice, la np.random.uniform funzione genera 1000 numeri casuali distribuiti in modo uniforme tra -1 e 1. L'argomento bins=30 specifica che i dati devono essere divisi in 30 bin e density=True garantisce che l'istogramma sia normalizzato per formare una densità di probabilità. Ciò significa che l'area sotto l'istogramma si integra con 1, utile quando si confrontano le distribuzioni.
Annotazioni
È probabile che si ottengano risultati diversi se si esegue il codice più volte. L'idea di base della casualità è che è imprevedibile e ogni volta che si esegue l'esempio, è possibile ottenere risultati diversi.
È possibile controllare questo processo impostando un valore seed con np.random.seed. Ciò è molto utile per il test e il debug nella fase di compilazione del modello, in quanto consente di riprodurre gli stessi risultati.