Informazioni sugli strumenti di spostamento dei dati disponibili
L'endpoint REST è una risorsa utile per importare dati nel database SQL di Azure. Tuttavia, altri strumenti per lo spostamento dei dati includono Azure Data Factory (ADF), Programma di copia bulk (BCP), Importazione/Esportazione guidata SQL Server e script nell'interfaccia della riga di comando di Azure e PowerShell. Questi strumenti offrono varie opzioni per lo spostamento dei dati, ognuno adatto a scenari diversi.
In questa unità verranno illustrati esempi dettagliati per alcuni di questi strumenti, mentre altri verranno illustrati in dettaglio.
Usare la sincronizzazione dati SQL per sincronizzare i dati
La sincronizzazione dati SQL è una funzionalità del database SQL di Azure che consente di sincronizzare i dati tra più database, sia nel cloud che in locale. Questa funzionalità è essenziale per mantenere la coerenza dei dati e abilitare scenari cloud ibridi. La sincronizzazione dati SQL è un servizio basato sul database SQL di Azure che consente di sincronizzare i dati selezionati in modo bidirezionale tra più database. Usa una topologia hub-spoke, in cui un database funge da hub e altri come membri. Il database hub deve essere un database SQL di Azure, mentre i database membri possono essere database SQL di Azure o database SQL Server.
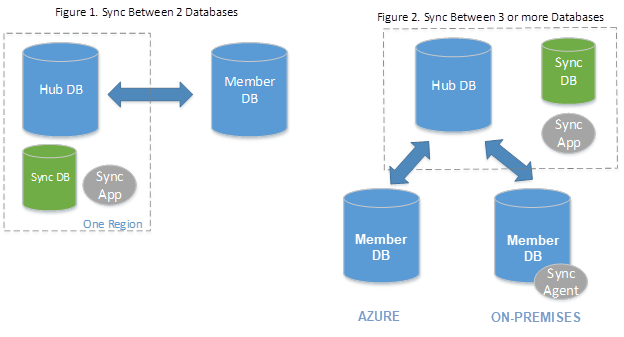
Configurazione della sincronizzazione dati SQL
Creare un gruppo di sincronizzazione: Per configurare la sincronizzazione dei dati, accedere al portale di Azure e passare al database SQL di Azure. Nella sezione Gestione dati selezionare Sincronizza con altri database. Selezionare quindi Nuovo gruppo di sincronizzazione e configurare le impostazioni del gruppo di sincronizzazione, inclusi il nome del gruppo di sincronizzazione e il database dei metadati di sincronizzazione.
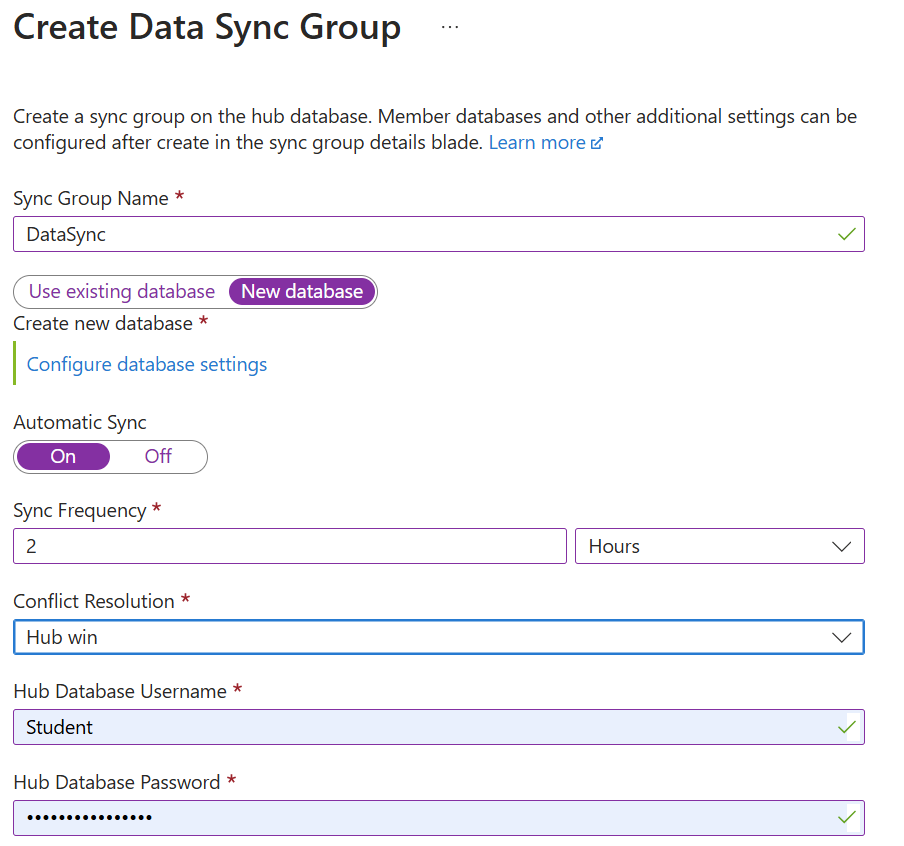
Aggiungi membri di sincronizzazione: Per aggiungere i database da sincronizzare, è possibile includere altri database SQL di Azure o database SQL Server locali. Per i database locali, è necessario installare e configurare un agente di sincronizzazione locale.
Configurare le impostazioni di sincronizzazione: Per definire lo schema di sincronizzazione, specificare le tabelle e le colonne da sincronizzare. Impostare la direzione di sincronizzazione (bidirezionale, da hub a membro o da membro a hub) e la frequenza di sincronizzazione. Infine, scegliere un criterio di risoluzione dei conflitti (vince l'hub o vince il membro) per gestire i conflitti di dati.
Monitorare e gestire la sincronizzazione: Per monitorare lo stato e i log di sincronizzazione, usare il portale di Azure. Verificare la presenza di eventuali errori di sincronizzazione e risolverli in base alle esigenze.
Usare Azure Data Factory per modificare i dati nel database SQL di Azure
Azure Data Factory (ADF) è un servizio di integrazione dei dati completamente gestito e basato sul cloud che consente di creare flussi di lavoro basati sui dati per orchestrare e automatizzare lo spostamento e la trasformazione dei dati. Supporta un'ampia gamma di origini dati e destinazioni e complessi processi ELT (Extract-Load-Transform), ETL (Extract-Transform-Load) ibridi, rendendolo uno strumento versatile per le attività di integrazione dei dati.
Con Azure Data Factory è possibile progettare un processo di orchestrazione e integrazione dei dati personalizzato.
Creare una risorsa di Data Factory: Si tratta della risorsa che incapsula tutte le attività di integrazione e trasformazione dei dati.
- Nel portale di Azure passare a Crea una risorsa e cercare "Data factory".
- Immettere i dettagli necessari, ad esempio la sottoscrizione, il gruppo di risorse e l'area, quindi selezionare Crea.
Creare servizi collegati: I servizi collegati vengono usati per definire le informazioni di connessione per origini dati e destinazioni.
- In Azure Data Factory selezionare Gestisci e quindi Servizi collegati.
- Creare un nuovo servizio collegato per il database SQL di Azure specificando i dettagli di connessione necessari.
Creare set di dati: I set di dati rappresentano le strutture di dati all'interno degli archivi dati usati dalle attività in una pipeline.
- In Azure Data Factory passare alla scheda Creazione.
- Selezionare + (plus) e selezionare Set di dati.
- Scegliere il tipo di archivio dati, ad esempio database SQL di Azure, Archiviazione BLOB di Azure. Specificare anche i dettagli di connessione e le proprietà del set di dati necessari.
Creare una pipeline: Le pipeline sono raggruppamenti logici di attività che eseguono un'unità di lavoro.
- In Azure Data Factory selezionare Autore e creare una nuova pipeline.
- Aggiungere un'attività Copia dati alla pipeline per copiare dati dal set di dati di origine al set di dati di destinazione.
Eseguire la pipeline: L'esecuzione della pipeline esegue la serie di attività configurate.
- Attivare la pipeline per avviare il processo di copia dei dati.
- Monitorare l'esecuzione della pipeline per assicurarsi che i dati vengano importati correttamente.
Usare BACPAC per importare ed esportare i dati
Un file BACPAC è essenzialmente un file ZIP con estensione bacpac, contenente lo schema e i dati del database. Viene usato a scopo di migrazione, backup e archiviazione del database. È possibile esportare un database in un file BACPAC e archiviarlo in Archiviazione BLOB di Azure o in locale e quindi importarlo nuovamente nel database SQL di Azure, nell'Istanza gestita di SQL di Azure o in SQL Server. Inoltre, è possibile usare i file BACPAC per importare solo un subset dei dati. Questa flessibilità consente un approccio più personalizzato allo spostamento dei dati.
È possibile importare ed esportare dati con file BACPAC usando il portale di Azure e SQL Server Management Studio (SSMS), ma è anche possibile usare l'utilità SQLPackage.
Eseguire il comando di esempio seguente per importare dati in un file BACPAC usando SQLPackage. Sostituire <ServerName>, <DatabaseName>, <UserName>, <Password> e <PathToBacpacFile> negli script seguenti con il nome effettivo del server, il nome del database, le credenziali utente e il percorso del file BACPAC.
sqlpackage.exe /Action:Import /tsn:<ServerName> /tdn:<DatabaseName> /tu:<UserName> /tp:<Password> /sf:<PathToBacpacFile>
Eseguire il comando di esempio seguente per esportare i dati in un file BACPAC usando SQLPackage.
sqlpackage.exe /Action:Export /ssn:<ServerName> /sdn:<DatabaseName> /su:<UserName> /sp:<Password> /tf:<PathToBacpacFile>
Usare il programma Bulk Copy (BCP)
L'utilità BCP è uno strumento da riga di comando che esporta tabelle in file in modo da poterle importare. Usare questo approccio per eseguire la migrazione da un singolo database SQL a Istanza gestita di SQL e viceversa.
Usare la procedura guidata di importazione ed esportazione di SQL Server
La procedura guidata di importazione ed esportazione di SQL Server è uno strumento grafico in SSMS per l'importazione e l'esportazione di dati tra SQL Server e numerose origini dati. Un vantaggio dell'Importazione/Esportazione guidata SQL Server è che usa SQL Server Integration Services (SSIS) per copiare i dati. SSIS è uno strumento altamente configurabile per la creazione di processi di estrazione, trasformazione e caricamento (ETL) che possono essere eseguiti in istanze di SQL Server e del database SQL di Azure.
Usare CLI di Azure e PowerShell
È possibile usare script sia nell'interfaccia della riga di comando di Azure che in PowerShell per automatizzare i processi di importazione ed esportazione. L'uso di script per l'importazione o l'esportazione è adatto per l'integrazione nelle pipeline CI/CD, ma ogni script richiede un elevato livello di personalizzazione rispetto ad altri metodi.
Per altre informazioni su altri strumenti disponibili per esportare e importare dati, vedere Importare ed esportare dati da SQL Server e dal database SQL di Azure.