Comprendere la normalizzazione
La normalizzazione è un termine usato dai professionisti del database per un processo di progettazione dello schema che riduce al minimo la duplicazione dei dati e impone l'integrità dei dati.
Anche se esistono molte regole complesse che definiscono il processo di refactoring dei dati in vari livelli (o forme) di normalizzazione, una definizione semplice per scopi pratici è:
- Separare ogni entità nella propria tabella.
- Separare ogni attributo discreto nella propria colonna.
- Identificare in modo univoco ogni istanza di entità (riga) usando una chiave primaria.
- Usare le colonne chiave esterna per collegare entità correlate.
Per comprendere i principi di base della normalizzazione, si supponga che la tabella seguente rappresenti un foglio di calcolo usato da un'azienda per tenere traccia delle vendite.
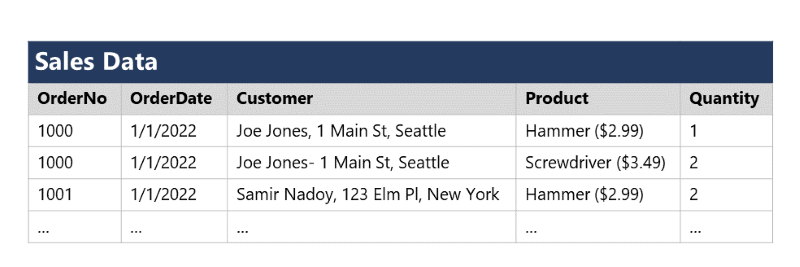
Si noti che i dettagli del cliente e del prodotto vengono duplicati per ogni singolo articolo venduto; e che il nome del cliente e l'indirizzo postale, e il nome e il prezzo del prodotto vengono combinati nelle stesse celle del foglio di calcolo.
Si esaminerà ora il modo in cui la normalizzazione cambia il modo in cui vengono archiviati i dati.

Ogni entità rappresentata nei dati (customer, product, sales order e line item) viene archiviata nella propria tabella e ogni attributo discreto di tali entità si trova nella propria colonna.
La registrazione di ogni istanza di un'entità come riga in una tabella specifica dell'entità rimuove la duplicazione dei dati. Ad esempio, per modificare l'indirizzo di un cliente, è necessario modificare solo il valore in una singola riga.
La scomposizione degli attributi in singole colonne garantisce che ogni valore sia vincolato a un tipo di dati appropriato, ad esempio i prezzi dei prodotti devono essere valori decimali, mentre le quantità di elementi riga devono essere numeri interi. Inoltre, la creazione di singole colonne offre un livello utile di granularità nei dati per l'esecuzione di query, ad esempio è possibile filtrare facilmente i clienti per coloro che risiedono in una città specifica.
Le istanze di ogni entità vengono identificate in modo univoco da un ID o da un altro valore di chiave, noto come chiave primaria; e quando un'entità fa riferimento a un'altra (ad esempio, un ordine ha un cliente associato), la chiave primaria dell'entità correlata viene archiviata come chiave esterna. È possibile cercare l'indirizzo del cliente (archiviato una sola volta) per ogni record nella tabella Order facendo riferimento al record corrispondente nella tabella Customer . In genere, un sistema di gestione di database relazionale (RDBMS) può applicare l'integrità referenziale per garantire che un valore immesso in un campo di chiave esterna disponga di una chiave primaria corrispondente nella tabella correlata, ad esempio impedendo gli ordini per i clienti inesistenti.
In alcuni casi, una chiave (primaria o esterna) può essere definita come chiave composta in base a una combinazione univoca di più colonne. Ad esempio, la tabella LineItem nell'esempio precedente usa una combinazione univoca di OrderNo e ItemNo per identificare un elemento di riga da un singolo ordine.