Esercizio: Consolidamento dei dati
L'attività richiesta per questo esercizio consiste nel creare un nuovo progetto di mining dei processi da due set di dati.
In questo esercizio si procederà a esaminare i dati, verificare che i campi obbligatori siano inclusi nei set di dati, identificare le colonne corrispondenti tra i set di dati, caricare i set di dati e quindi unire i set di dati in base alle colonne corrispondenti.
Obiettivi
Gli obiettivi di questo esercizio sono:
Rivedere e preparare i dati.
Creare il processo e caricare i dati da più origini.
Unire i set di dati in base alle colonne corrispondenti.
Eseguire il mapping degli attributi.
Campi obbligatori
Per far sì che il mining dei processi possa analizzare i registri eventi, è necessario disporre dei campi seguenti: Case ID, Activity ed Event Start.
Preparazione dei dati e caricamento
Si ricevono due set di dati in formato xlsx. Si vogliono rivedere i dati per accertarsi che tutti i campi obbligatori siano inclusi nei set di dati, identificare le colonne corrispondenti e quindi procedere alla creazione del processo.
Procedura generale: Preparazione dei dati e caricamento
Per completare questo esercizio, provare a eseguire la seguente procedura generale. Se non si è in grado di procedere, andare alla sezione Procedura dettagliata e seguire le istruzioni fornite.
Aprire i file e controllare il set di dati.
Se necessario, convertire i dati in un formato facilmente leggibile.
Verificare che tutte le colonne richieste siano incluse nei set di dati.
Identificare le colonne corrispondenti tra i set di dati.
Salvare i set di dati come file CSV.
Creare il processo e quindi caricare i set di dati.
Procedura dettagliata: Preparazione dei dati e caricamento
Questa sezione fornisce indicazioni più approfondite per ila procedura generale precedente.
Attività: Esame del set di dati e identificazione delle colonne corrispondenti
La prima attività consiste nell'esaminare i set di dati e identificare le colonne corrispondenti seguendo questi passaggi:
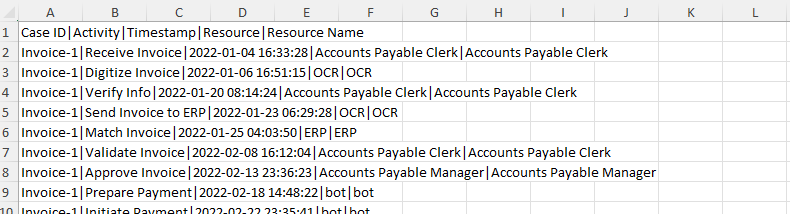
Individuare e aprire il file AP_EV_LAB_Combine_log.xlsx.
I dati nel file dovrebbero avere un aspetto simile all'immagine seguente.
Nota
Una barra verticale (|) separa i dati, rendendone complicata la lettura. Usare la funzionalità Testo in colonne di Excel per rendere i dati più facili da leggere.
Selezionare la scheda Dati.
Tutti i dati di ogni riga si trovano in una cella. Selezionare tutte le righe, inclusa l'intestazione, quindi selezionare il pulsante Testo in colonne.
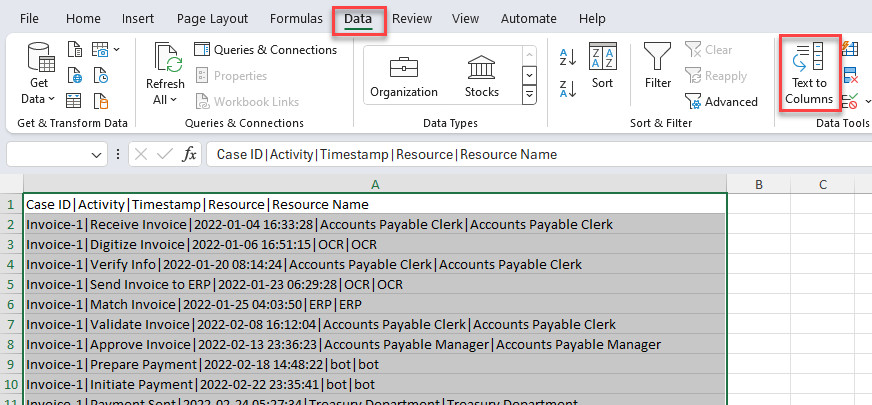
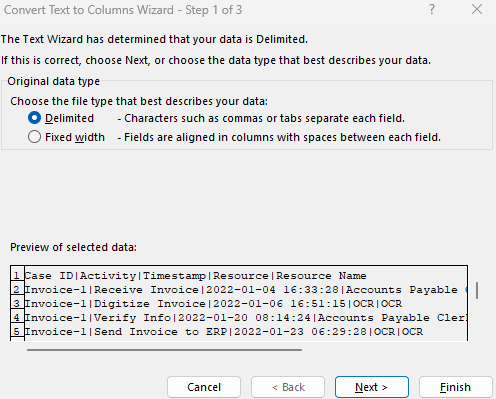
Selezionare Delimitato, quindi Avanti.
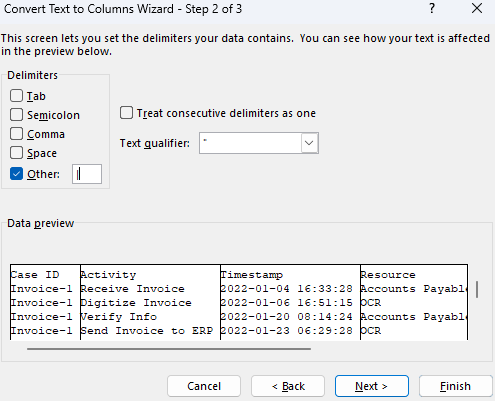
Selezionare Altro, immettere una barra verticale (|), quindi selezionare Avanti.
Selezionare Fine.
Ora i dati dovrebbero risultare più facili da leggere.
Verificare se i campi obbligatori sono presenti.
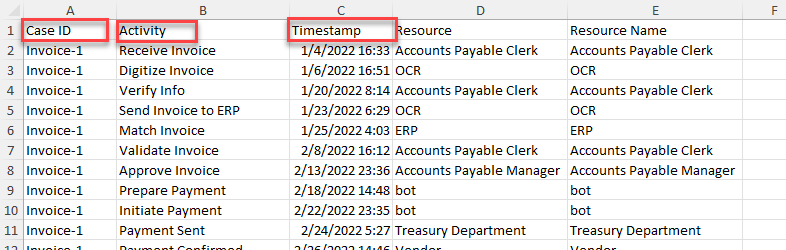
Identificare eventuali altri campi dei quali eseguire eventualmente il mapping per il mining dei processi. Selezionare Fine.
Facoltativamente, è possibile annotare i campi da usare. Dopo aver completato l'ispezione dei dati, selezionare File > Salva con nome.
Salvare il file in formato CSV standard e assegnare allo stesso un nome appropriato.

Chiudere il file.
Preparare il secondo set di dati individuando e aprendo il file AP_EV_LAB_Combine_attr.xlsx.
I dati nel file dovrebbero avere un aspetto simile all'immagine seguente.
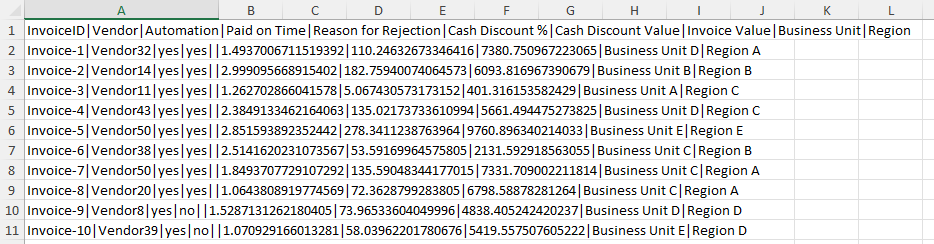
Nota
Una barra verticale (|) separa i dati, rendendone complicata la lettura. Usare la funzionalità Testo in colonne di Excel per rendere i dati più facili da leggere.
Selezionare la scheda Dati.
Tutti i dati di ogni riga si trovano in una cella. Selezionare tutte le righe, inclusa l'intestazione, quindi selezionare il pulsante Testo in colonne.
Selezionare Delimitato, quindi Avanti.
Selezionare Altro, immettere una barra verticale (|), quindi selezionare Avanti.
Selezionare Fine.
Ora i dati dovrebbero risultare più facili da leggere.
Tutti i campi obbligatori sono già presenti nel primo file. Individuare le colonne in comune tra i due set di dati.
Notare che InvoiceID e Case ID del primo set di dati corrispondono. Usare queste colonne come colonne corrispondenti.
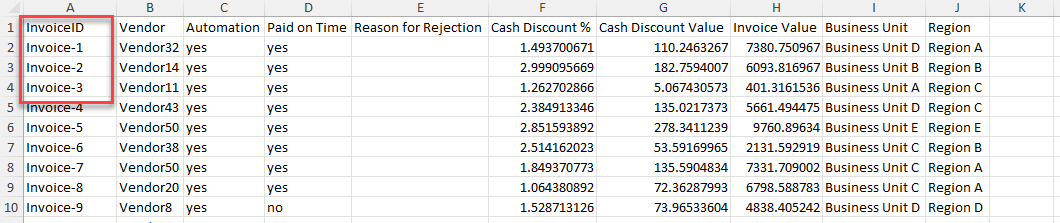
Identificare eventuali altri campi dei quali eseguire il mapping per il mining dei processi.
Facoltativamente, è possibile annotare i campi da usare. Dopo aver completato l'ispezione dei dati, selezionare File > Salva con nome.
Salvare il file come CSV e assegnare allo stesso un nome appropriato.

Chiudere il file.










Attività: Creazione del processo e caricamento dei dati
Per creare il processo e caricare i dati, attenersi alla seguente procedura:
Accedere a Microsoft Power Automate e selezionare l'ambiente corretto.
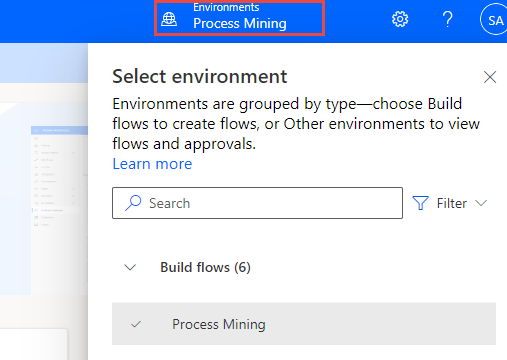
Selezionare Mining dei processi dal riquadro di sinistra, quindi + Inizia qui.
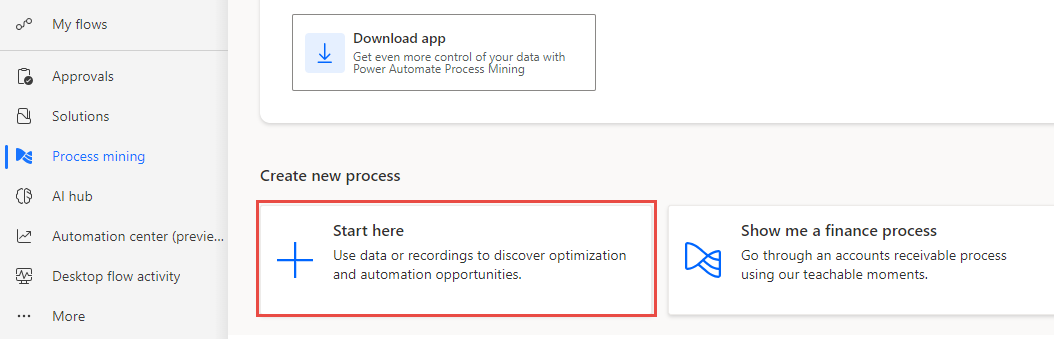
Immettere Merged datasets per Nome processo, selezionare Importa dati per Origine dati, selezionare Flusso di dati, quindi selezionare Continua.
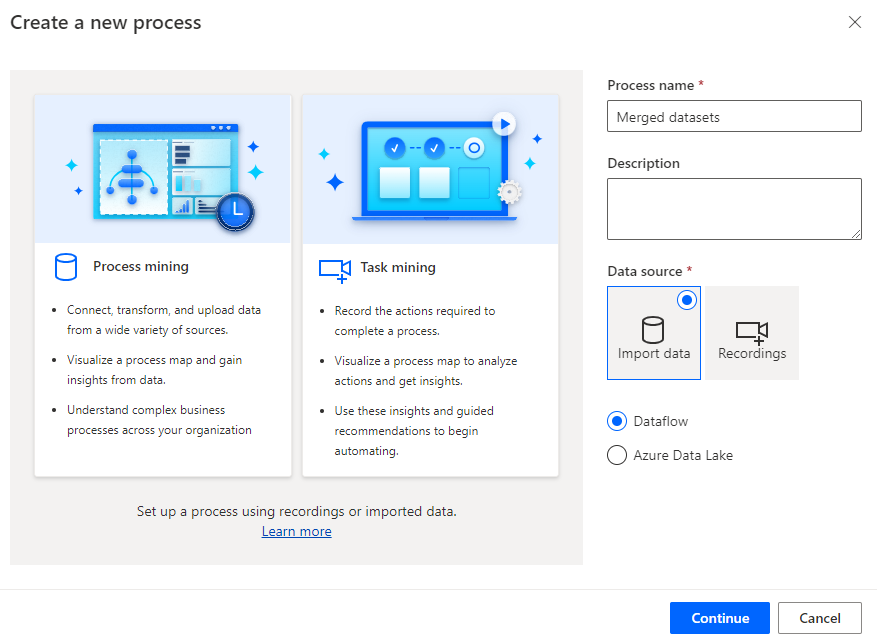
Selezionare Ignora se il sistema richiede di aggiungere l'area di lavoro Power BI.
Selezionare Testo/CSV come origine dati.
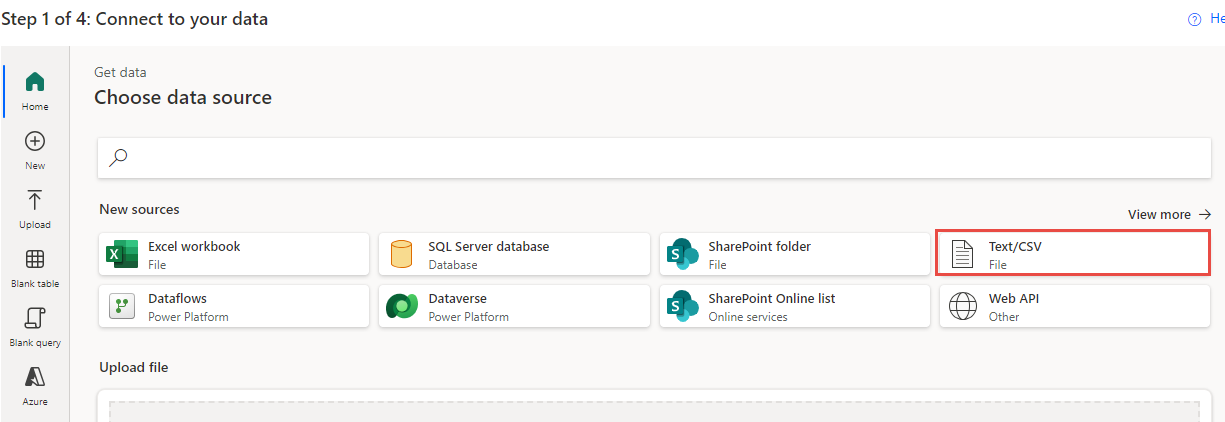
Selezionare Carica file, quindi fare clic sul pulsante Sfoglia.
Selezionare il primo file CSV creato, quindi Apri.
Se non è stato effettuato l'accesso, selezionare il pulsante Accedi e fornire le proprie credenziali.
Selezionare Avanti.
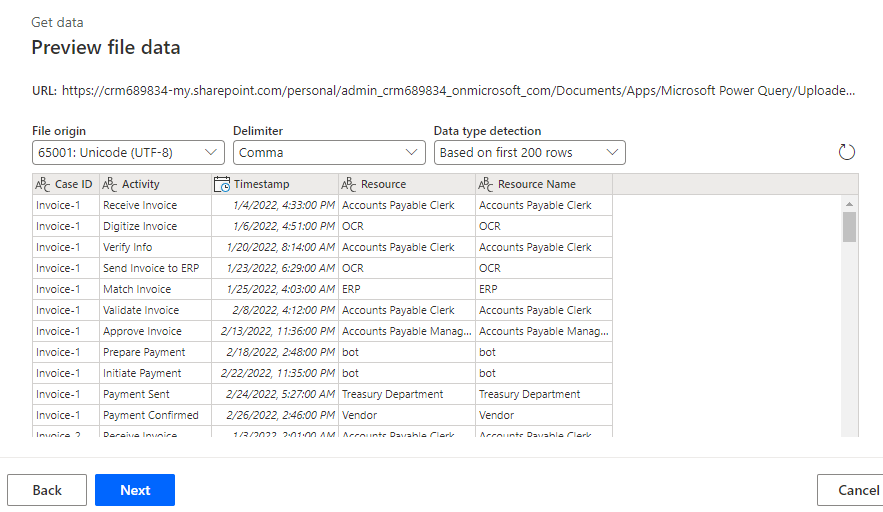
Dovrebbe essere visualizzata un'anteprima dei dati. Selezionare Avanti.
Il sistema dovrebbe ora passare alla fase di trasformazione.
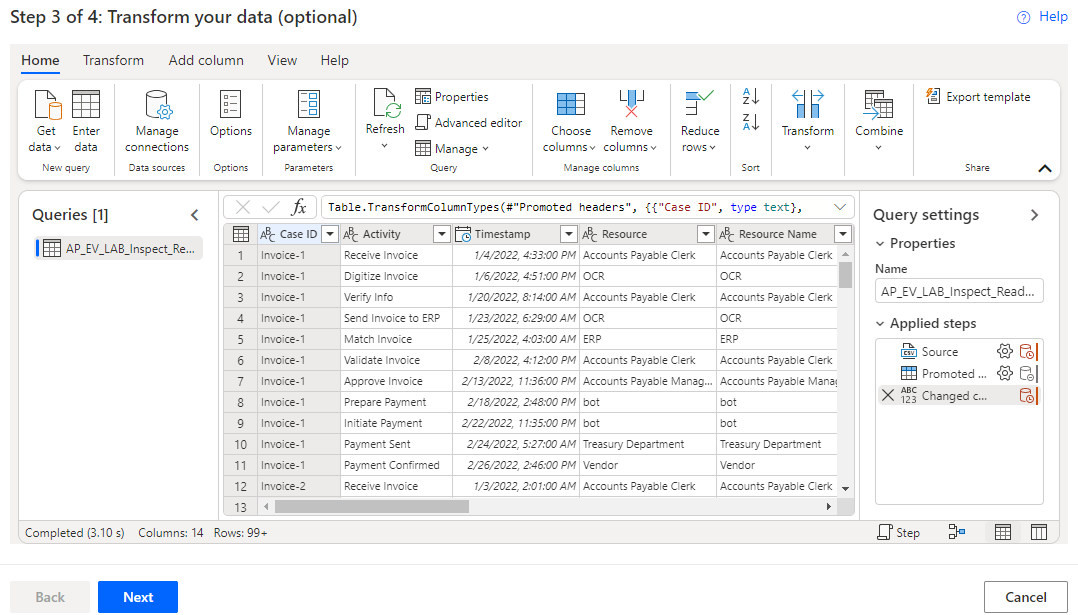
Per caricare il secondo set di dati, selezionare Recupera dati, quindi Testo/CSV.
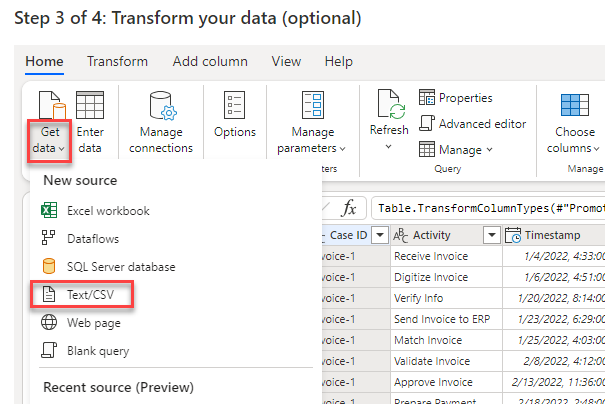
Selezionare Carica file, quindi fare clic sul pulsante Sfoglia.
Selezionare il secondo file CSV creato, quindi Apri.
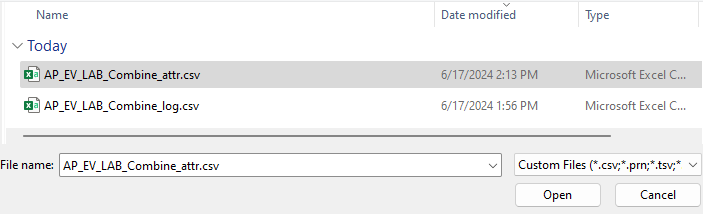
Selezionare Avanti.
Dovrebbe essere visualizzata un'anteprima dei dati. Selezionare Crea.











Ora le due tabelle dovrebbero essere state caricate.

Unione di set di dati
Dopo aver caricato correttamente tutti i set di dati, è possibile unirli in una nuova tabella consolidata. Questa nuova tabella integra i dati di entrambi i set di dati caricati.
Procedura generale: Unione di set di dati
Per completare questo esercizio, provare a eseguire la seguente procedura generale. Se non si è in grado di procedere, andare alla sezione Procedura dettagliata e seguire le istruzioni fornite.
Per unire i due set di dati in una nuova tabella, usare la funzionalità Esegui merge di query come nuova di Power Query.
Selezionare le tabelle di unione destra e sinistra.
Selezionare le colonne corrispondenti corrette tra le due tabelle.
Accertarsi di unire i dati usando un left outer join.
Espandere la tabella.
Escludere le colonne duplicate.
Rinominare la nuova tabella.
Attivare le funzionalità di caricamento per la tabella che si vuole caricare, quindi disattivarle per le altre due tabelle.
Eseguire il mapping dei dati.
Salvare il processo.
Procedura dettagliata: Unione di set di dati
Questa sezione fornisce indicazioni più approfondite per ila procedura generale precedente.
Attività: Unione del set di dati e mapping
Per unire set di dati e mapping, seguire questi passaggi:
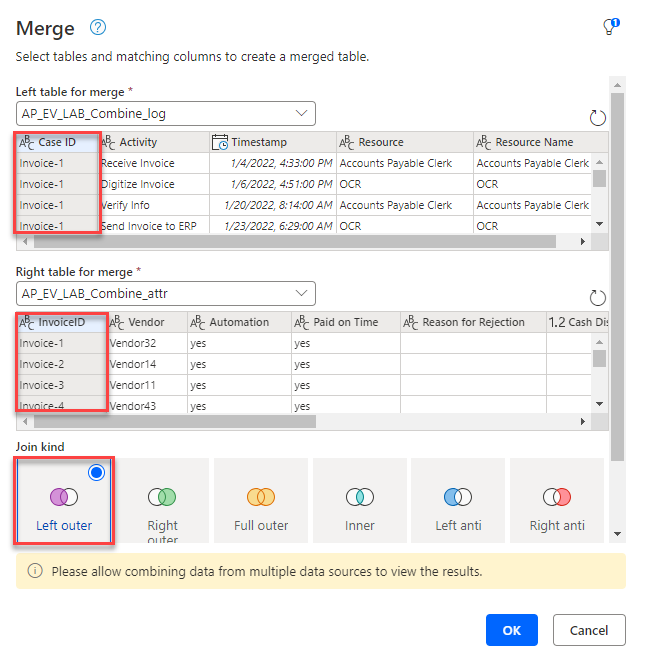
Selezionare il menu a discesa Esegui merge di query, quindi selezionare Esegui merge di query come nuova.
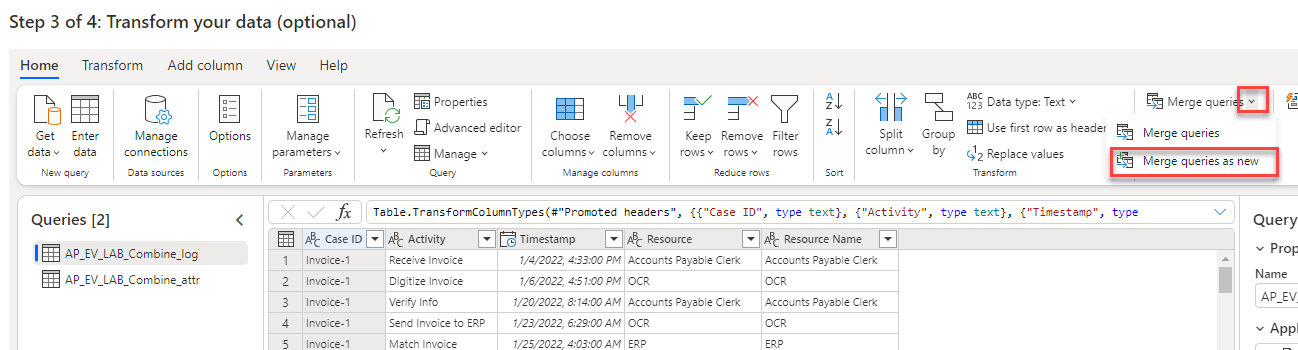
Selezionare la prima tabella creata per Tabella sinistra per l'unione, quindi selezionare Case ID come colonna corrispondente.
Selezionare la seconda tabella creata per Tabella destra per l'unione, quindi selezionare InvoiceID come colonna corrispondente.
Selezionare Left outer per Tipo di join, quindi selezionare OK.
Dovrebbe essere visualizzato un messaggio di errore simile al seguente: "La valutazione è stata annullata perché la combinazione di dati provenienti da più origini potrebbe rivelare dati da un'origine all'altra. Fare clic su Continua se la possibilità di rivelare i dati è accettabile." Selezionare Continua.

La seconda tabella dovrebbe ora essere visualizzata come una colonna. Espandere la tabella e selezionare le colonne da aggiungere. Individuare la seconda colonna della tabella, quindi selezionare l'icona espandi.
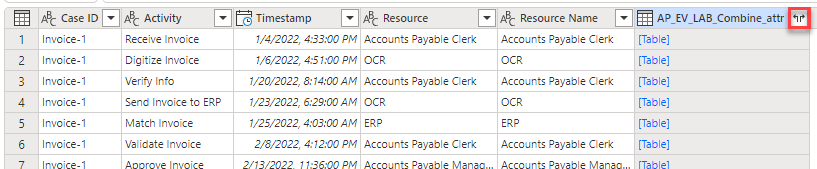
Nota
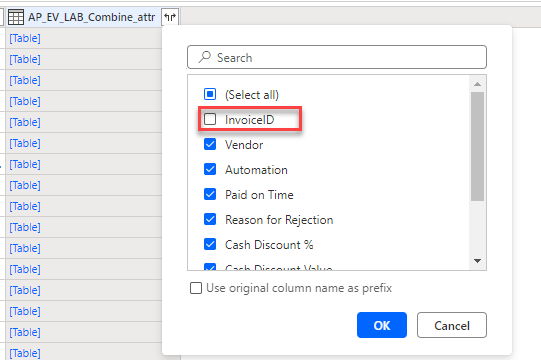
Ora si procederà a selezionare le colonne che si desidera includere. Poiché non si desidera che la tabella Merge includa più colonne contenenti valori, è necessario selezionare le colonne univoche per questa tabella.
Deselezionare la casella di controllo InvoiceID, quindi selezionare OK.
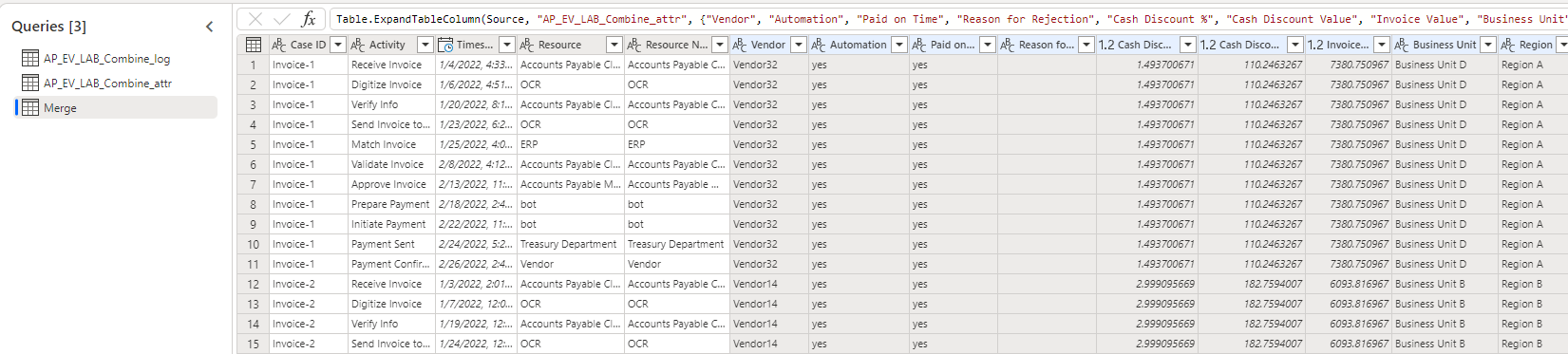
La tabella Merge dovrebbe ora essere simile all'immagine seguente.
Fare clic con il pulsante destro del mouse sulla tabella Merge, quindi selezionare Rinomina.
Rinominare la tabella in Merged_log_attr.
Per impostazione predefinita, la funzionalità di caricamento è attivata in tutte e tre le tabelle. Poiché si desidera caricare solo la tabella Merge, fare clic con il pulsante destro del mouse sulla prima tabella, quindi selezionare Abilita caricamento. Questa azione disattiva la funzionalità di caricamento per la prima tabella.
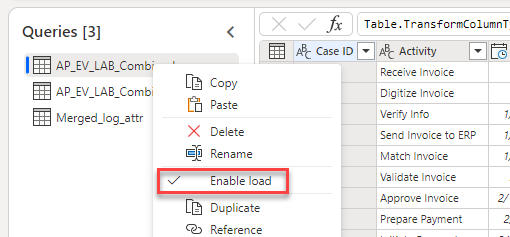
Fare clic con il pulsante destro del mouse sulla seconda tabella, quindi selezionare Abilita caricamento. Questa azione disattiva la funzionalità di caricamento per la seconda tabella.
Il nome delle tabelle in cui la funzionalità di caricamento è disattivata dovrebbe apparire in carattere corsivo.
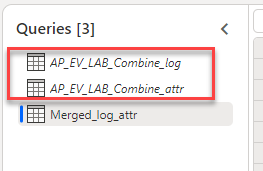
Selezionare Avanti.
Il sistema dovrebbe ora passare alla fase di mapping. Eseguire per prima cosa il mapping dei campi obbligatori, come mostrato nella tabella seguente.
Nome attributo Tipo di attributo Tipo di dati attributo Case ID Case ID Testo Activity Activity Testo Timestamp Event Start Data/ora 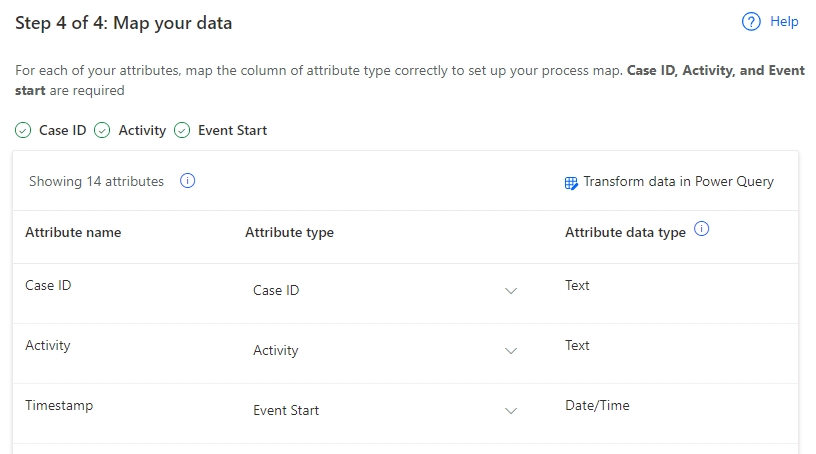
È possibile includere molti altri campi. Ai fini di questo esercizio, si esegue il mapping di tutti i campi.
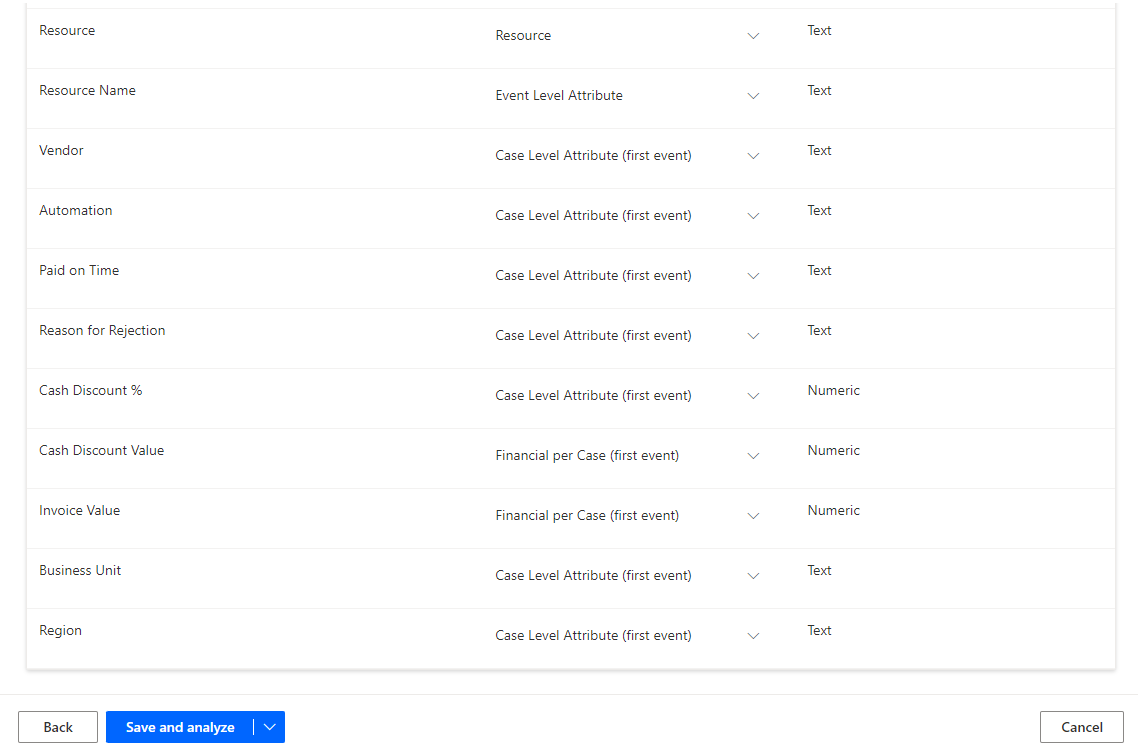
Eseguire il mapping del resto dei campi come mostrato nella tabella seguente.
Nome attributo Tipo di attributo Tipo di dati attributo Resource Resource Testo Resource Name Event Level Attribute Testo Vendor Case Level Attribute (first event) Testo Automation Case Level Attribute (first event) Testo Paid on Time Case Level Attribute (first event) Testo Reason for Rejection Case Level Attribute (first event) Testo Cash Discount % Case Level Attribute (first event) Numerico Cash Discount Value Financial per Case (first event) Numerico Invoice Value Financial per Case (first event) Numerico Business Unit Case Level Attribute (first event) Testo Region Case Level Attribute (first event) Testo Dopo aver eseguito il mapping dei campi, selezionare Salva e analizza.
Attendere il completamento dell'analisi. Il processo potrebbe richiedere alcuni minuti.









Una volta completata l'analisi, la panoramica del processo dovrebbe risultare simile all'immagine seguente.
