Informazioni sui data warehouse
Un data warehouse è un archivio strutturato centralizzato progettato per query analitiche e report. A differenza dei database operativi che gestiscono transazioni aziendali quotidiane, un data warehouse consolida i dati da più origini in un formato ottimizzato per l'analisi.
La creazione di un data warehouse moderno comporta in genere:
- Inserimento dati : spostamento dei dati dai sistemi di origine al warehouse.
- Data storage: archiviazione dei dati in un formato ottimizzato per l'analisi.
- Elaborazione dati : trasformazione dei dati in un formato pronto per l'utilizzo da parte degli strumenti analitici.
- Analisi e recapito dei dati : analisi dei dati per ottenere informazioni dettagliate e distribuirle all'azienda.
Progettare un data warehouse
I data warehouse contengono tabelle organizzate in uno schema ottimizzato per la modellazione multidimensionale. In questo approccio si raggruppano i dati numerici correlati agli eventi in base a attributi diversi. Ad esempio, è possibile analizzare l'importo totale pagato per gli ordini di vendita che si sono verificati in una data specifica o in un determinato negozio.
Tabelle in un magazzino dati
Organizzi le tabelle del data warehouse per supportare un'analisi efficiente di grandi quantità di dati. Questa organizzazione, nota come modellazione dimensionale, prevede la strutturazione delle tabelle in tabelle dei fatti e tabelle delle dimensioni.
Le tabelle dei fatti contengono i dati numerici da analizzare. Le tabelle dei fatti in genere hanno un numero elevato di righe e sono l'origine principale dei dati per l'analisi. Ad esempio, una tabella dei fatti può contenere l'importo totale pagato per gli ordini di vendita che si sono verificati in una data specifica o in un determinato negozio.
Le tabelle delle dimensioni contengono informazioni descrittive sui dati nelle tabelle dei fatti. Le tabelle delle dimensioni in genere hanno alcune righe e forniscono il contesto per i dati nelle tabelle dei fatti. Ad esempio, una tabella delle dimensioni può contenere informazioni sui clienti che hanno effettuato ordini di vendita.
Oltre alle colonne di attributo, una tabella delle dimensioni contiene una colonna chiave che identifica in modo univoco ogni riga nella tabella. Di fatto, una tabella delle dimensioni include comunemente due colonne chiave:
- Una chiave surrogata è un identificatore univoco per ogni riga nella tabella delle dimensioni. Spesso si tratta di un valore intero generato automaticamente dal sistema di gestione del database quando si inserisce una nuova riga.
- Una chiave alternativa è spesso una chiave naturale o aziendale che identifica un'istanza specifica di un'entità nel sistema di origine transazionale, ad esempio un codice prodotto o un ID cliente.
Sono necessarie chiavi surrogate e alternative in un data warehouse, perché servono scopi diversi. Le chiavi surrogate sono specifiche del data warehouse e consentono di mantenere la coerenza e l'accuratezza. Le chiavi alternative sono specifiche del sistema di origine e consentono di mantenere la tracciabilità tra il data warehouse e il sistema di origine.
Tipi speciali di tabelle delle dimensioni
I tipi speciali di dimensioni forniscono contesto aggiuntivo e consentono un'analisi dei dati più completa.
Le dimensioni temporali forniscono informazioni sul periodo di tempo in cui si è verificato un evento. Questa tabella consente agli analisti dei dati di aggregare i dati in base a intervalli di tempo. Ad esempio, una dimensione temporale può includere colonne per l'anno, il trimestre, il mese e il giorno di un ordine di vendita.
Le dimensioni a modifica lenta tengono traccia delle modifiche apportate agli attributi della dimensione nel tempo, ad esempio le modifiche apportate all'indirizzo di un cliente o al prezzo di un prodotto. Sono significativi in un data warehouse perché consentono di analizzare e comprendere le modifiche ai dati nel tempo. Le dimensioni a modifica lenta assicurano che i dati rimangano up-to-date e accurati, che è importante per prendere decisioni aziendali corrette.
progettazione degli schemi del data warehouse
Nella maggior parte dei database transazionali usati nelle applicazioni aziendali, i dati vengono normalizzati per ridurre la duplicazione. In un data warehouse, tuttavia, i dati della dimensione vengono denormalizzati* per ridurre il numero di join necessari per eseguire query sui dati.
Spesso un data warehouse usa uno schema star, in cui una tabella dei fatti è correlata direttamente alle tabelle delle dimensioni, come illustrato in questo esempio:
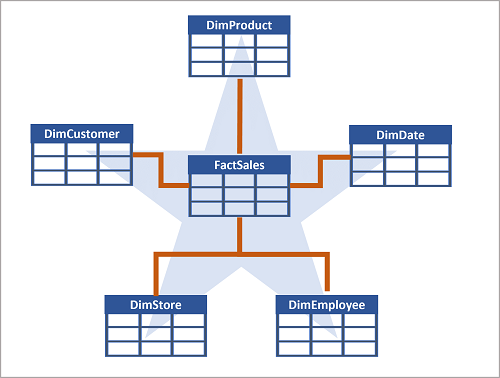
È possibile usare gli attributi della dimensione per raggruppare i numeri di tabella dei fatti a livelli diversi. Ad esempio, è possibile trovare i ricavi totali delle vendite per un'intera area o solo per un cliente. È possibile archiviare le informazioni per ogni livello nella stessa tabella delle dimensioni.
Suggerimento
Per altre informazioni sulla progettazione di schemi star per Fabric, vedere Che cos'è uno schema star .
Se sono presenti molti livelli o attributi condivisi da elementi diversi, potrebbe essere opportuno usare invece uno schema snowflake . Ecco un esempio:
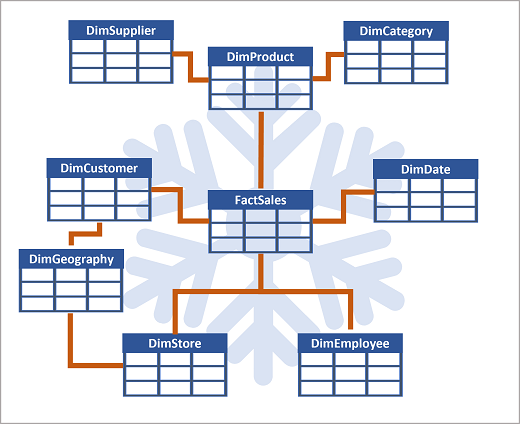
In questo caso, la tabella DimProduct suddivide (normalizza) in tabelle di dimensioni separate per categorie di prodotti e fornitori.
- Ogni riga della tabella DimProduct contiene i valori chiave per le righe corrispondenti nelle tabelle DimCategory e DimSupplier.
Una tabella DimGeography contiene informazioni sulla posizione di clienti e negozi.
- Ogni riga nelle tabelle DimCustomer e DimStore contiene un valore chiave per la riga corrispondente nella tabella DimGeography .