Estrarre informazioni dai documenti
Tip
Per altri dettagli, vedi la scheda Testo e immagini .
I processi aziendali di oggi dipendono principalmente dai dati contenuti in documenti come moduli, ricevute e fatture. L'elaborazione manuale può introdurre ritardi ed errori, rendendo l'automazione dell'estrazione dei dati più importante che mai.
Comprensione di Informazioni sul contenuto di Azure
Azure Content Understanding segue un flusso di lavoro di estrazione basato su modello in cui il contenuto non strutturato viene inserito, analizzato e restituito come dati strutturati.
Inserire contenuto: si invia contenuto ad Azure Content Understanding.
Analisi basata sull'intelligenza artificiale: il servizio usa una combinazione di: Riconoscimento ottico dei caratteri (OCR), riconoscimento vocale, comprensione del linguaggio naturale e modelli di intelligenza artificiale bidirezionale per analizzare il contenuto.
Output strutturato: il servizio restituisce risultati strutturati ,ad esempio in JSON, che corrispondono al modello, semplificando l'archiviazione, la ricerca o l'integrazione dei dati nei sistemi downstream.
Annotazioni
JSON (JavaScript Object Notation) è un formato di dati basato su testo usato per archiviare e scambiare dati strutturati tra sistemi. È facile per gli esseri umani leggere e scrivere e per le macchine analizzare e generare.
Comprendere gli schemi
OCR (riconoscimento ottico dei caratteri) consente a un computer di "leggere" testo da immagini, ad esempio documenti digitalizzati, foto di ricevute o immagini di pagine stampate, e trasformare il testo in testo digitale modificabile e ricercabile. L'OCR di base consente di riconoscere il testo stampato, è incentrato sull'estrazione di testo e non comprende significato, contesto o relazioni tra parole.
Le funzionalità di analisi dei documenti di Azure Content Understanding vanno oltre la semplice estrazione di testo basata su OCR per includere l'estrazione basata su schema dei campi e i relativi valori. L'approccio basato su schema è ciò che differenzia Azure Content Understanding dai servizi di trascrizione o OCR di base.
Uno schema descrive le informazioni da estrarre e il modo in cui tali informazioni devono essere strutturate. Quando si definisce uno schema, si specificano i campi da estrarre. Uno schema elenca i campi o le entità specifiche di cui ti interessa.
Si supponga, ad esempio, di definire uno schema che includa i campi comuni in genere presenti in una fattura, ad esempio:
- Nome fornitore
- Numero fattura
- Data di fattura
- Nome cliente
- Indirizzo personalizzato
- Elementi: gli elementi ordinati, ognuno dei quali include:
- Descrizione articolo
- Prezzo unitario
- Quantità ordinata
- Totale voce
- Subtotale fattura
- Imposta
- Addebito di spedizione
- Totale fattura
Si supponga ora di dover estrarre queste informazioni dalla fattura seguente:
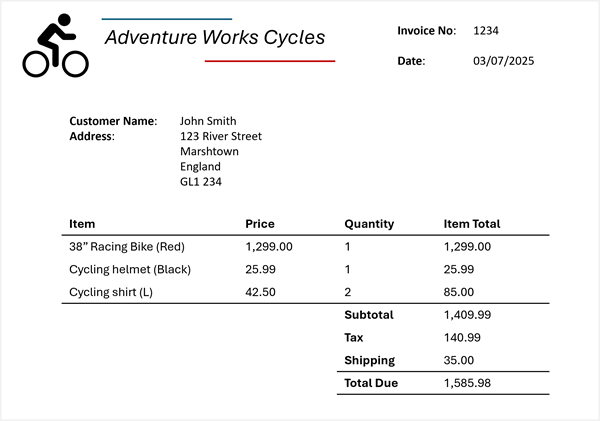
Azure Content Understanding può applicare lo schema della fattura alla fattura e identificare i campi corrispondenti, anche quando vengono etichettati con nomi diversi (o non etichettati affatto). L'analisi risultante produce un risultato simile al seguente:

Lo schema definisce anche la struttura dei campi. Gli schemi supportano campi strutturati e annidati, non solo testo flat. Per esempio:
-
Itemsè una raccolta - Ogni elemento ha
description,unit price,quantityeline total
L'identificazione di campi strutturati consente a Informazioni sul contenuto di Azure di comprendere le relazioni tra i valori, ma solo un OCR non può fare.
Nell'esempio di fattura, per ogni campo rilevato, è possibile estrarre i valori annidati:
- Nome fornitore: Adventure Works Cycles
- Numero fattura: 1234
- Data della fattura: 03/07/2025
- Nome cliente: John Smith
- Indirizzo personalizzato: 123 River Street, Marshtown, Inghilterra, GL1 234
-
Elementi:
- Elemento 1:
- Descrizione articolo: 38" Racing Bike (Rosso)
- Prezzo unitario: 1299,00
- Quantità ordinata: 1
- Totale voce: 1299,00
- Elemento 2:
- Descrizione dell'elemento: Casco ciclistico (nero)
- Prezzo unitario: 25,99
- Quantità ordinata: 1
- Totale voce: 25,99
- Elemento 3:
- Descrizione dell'elemento: Camicia ciclistica (L)
- Prezzo unitario: 42,50
- Quantità ordinata: 2
- Totale voce: 85.00
- Elemento 1:
- Subtotale fattura: 1409.99
- Imposta: 140,99
- Addebito di spedizione: 35.00
- Totale fattura: 1585,98
Azure Content Understanding estrae il significato previsto, non solo le etichette. Gli schemi vengono applicati semanticamente, ovvero:
- I campi possono essere estratti anche se le etichette differiscono
- I campi possono essere estratti anche se mancano etichette
Ad esempio, Invoice No., Invoice #o un numero senza etichetta può essere mappato a InvoiceNumber se l'analizzatore determina che rappresentano lo stesso concetto.
Comprendere gli analizzatori
Un analizzatore è un'unità di Informazioni sul contenuto di Azure che accetta input, applica l'analisi di intelligenza artificiale e produce risultati strutturati. Gli analizzatori applicano in modo coerente la stessa logica di estrazione a tutto il contenuto in ingresso. Dopo la configurazione, un analizzatore garantisce che uno schema venga riutilizzato in modo coerente per ogni richiesta di analisi. Gli analizzatori producono anche risultati JSON prevedibili. I risultati strutturati semplificano l'elaborazione downstream (archiviazione, ricerca, automazione).
Azure Content Understanding offre analizzatori predefiniti per scenari comuni e supporta analizzatori personalizzati in base alle proprie esigenze. In generale:
- Si sceglie o si crea un analizzatore.
- L'analizzatore include uno schema che definisce campi e struttura.
- Inviare contenuto per l'analisi
- Il servizio applica lo schema
- Si ricevono risultati JSON strutturati corrispondenti allo schema
Uso della comprensione dei contenuti di Azure nel portale Foundry
Annotazioni
Il portale foundry ha un'interfaccia utente classica e una nuova interfaccia utente.
Dopo aver creato una risorsa Microsoft Foundry, è possibile usare l'interfaccia new foundry portal per testare Azure Content Understanding. Il portale foundry fornisce esempi di contenuto e consente di caricare materiale personalizzato per l'analisi.
È possibile usare l'interfaccia visiva per selezionare un documento di origine ed estrarre i campi predefiniti delle informazioni. Ad esempio, quando si prova Azure Content Understanding su un'immagine di un documento, il servizio restituisce il testo del documento e le informazioni sul layout del testo.

Gli analizzatori di Azure Content Understanding identificano i valori di testo nei documenti ed eseguono il mapping a campi specifici. Ad esempio, data una fattura, il servizio restituisce i campi (ad esempio indirizzo fornitore) e i dati nei campi (ad esempio 123 456th Street).

Nel portale di Foundry è anche possibile visualizzare i risultati JSON dell'elaborazione.

Compilazione di un'applicazione client con Azure Content Understanding
È possibile usare l'API Content Understanding per compilare un'applicazione client leggera che estrae i dati a livello di codice.
Annotazioni
Un'applicazione client è un programma software che viene eseguito sul dispositivo di un utente e richiede servizi o dati da un altro sistema, in genere un server, su una rete. Il client fa parte di un'applicazione con cui gli utenti interagiscono, mentre il server esegue il lavoro pesante dietro le quinte. Le applicazioni possono richiedere dati o azioni da un servizio e ricevere una risposta strutturata usando un'API.
Quando si usa l'API Content Understanding, è possibile scegliere un analizzatore predefinito o creare un analizzatore personalizzato. Gli analizzatori predefiniti includono: prebuilt-invoice, prebuilt-imageSearch, prebuilt-audioSearche prebuilt-videoSearch. Quando si invia contenuto per l'analisi all'analizzatore, l'analisi è asincrona, il che significa che si ottiene il risultato in un secondo momento quando è pronto. Poiché l'analisi è asincrona, è necessario eseguire il polling dell'URL Operation-Location (o analyzerResults) fino a quando l'operazione non viene completata con successo.
Uso di Azure Content Understanding Python SDK
Si esaminerà ora il processo di uso di Python SDK per analizzare una fattura da un URL.
- Installare Azure Content Understanding Python SDK.
python -m pip install azure-ai-contentunderstanding
Identificare l'endpoint della risorsa Foundry e la chiave API o Microsoft Entra ID. L'endpoint è in genere simile al seguente:
https://<your-resource-name>.services.ai.azure.com/Creare ed eseguire il codice dell'applicazione client.
analzyer_idè l'ID dell'analizzatore predefinito. È possibile trovare un elenco di valori di ID di analizzatore predefiniti qui.
import os
from azure.ai.contentunderstanding import ContentUnderstandingClient
from azure.core.credentials import AzureKeyCredential
endpoint = os.environ["FOUNDRY_ENDPOINT"]
key = os.environ["FOUNDRY_KEY"]
client = ContentUnderstandingClient(endpoint=endpoint, credential=AzureKeyCredential(key))
# 1) start analysis with analyzer id + inputs
analyzer_id = "prebuilt-invoice"
inputs = [
{"url": "https://github.com/Azure-Samples/azure-ai-content-understanding-python/raw/refs/heads/main/data/invoice.pdf"}
]
# 2) wait for the Long Running Operation (LRO) to complete
poller = client.begin_analyze(analyzer_id=analyzer_id, inputs=inputs) # starts LRO
result = poller.result() # waits for completion (polling handled by SDK)
# 3) read structured fields + markdown
# The result typically includes extracted "fields" and "markdown" per input content item.
for content in result.contents:
print(content.markdown)
print(content.fields)
L'output risultante è JSON che mostra il markdown estratto, i campi, i dati nei campi e il punteggio di attendibilità. Per esempio:
{
"status": "Succeeded",
"result": {
"analyzerId": "prebuilt-invoice",
"apiVersion": "2025-05-01-preview",
"contents": [
{
"markdown": "# INVOICE\n\nCONTOSO LTD.\n\nContoso Headquarters\n123 456th St\nNew York, NY, 10001\n\nINVOICE: INV-100\n\nINVOICE DATE: 11/15/2019\n\nDUE DATE: 12/15/2019\n\nCUSTOMER NAME: MICROSOFT CORPORATION\n",
"fields": {
"CustomerName": {
"type": "string",
"valueString": "MICROSOFT CORPORATION",
"confidence": 0.95,
},
"InvoiceDate": {
"type": "date",
"valueDate": "2019-11-15",
"confidence": 0.994,
}
}
}
]
}
}
Informazioni su come usare gli analizzatori di Azure Content Understanding per estrarre dati strutturati dall'audio e dal video.