Abilitare la resilienza delle applicazioni con il database SQL di Azure
La replica geografica e i gruppi di failover automatico sono entrambi meccanismi usati nel database SQL di Azure per migliorare la disponibilità e il ripristino di emergenza, ma presentano alcune differenze principali.
Informazioni sulla replica geografica attiva
Un metodo per aumentare la disponibilità di un database SQL di Azure consiste nell'usare la replica geografica attiva. La replica geografica attiva è progettata come soluzione di continuità aziendale che consente di creare database secondari leggibili di singoli database in un server nella stessa area o in un'area diversa. Supporta fino a quattro repliche secondarie ed è configurato per ogni database.
Dietro le quinte, Azure usa i gruppi di disponibilità per fornire questa funzionalità. Con la replica geografica attiva, i clienti possono eseguire il failover a livello di codice o manuale dei database primari nelle aree secondarie durante un'emergenza grave.
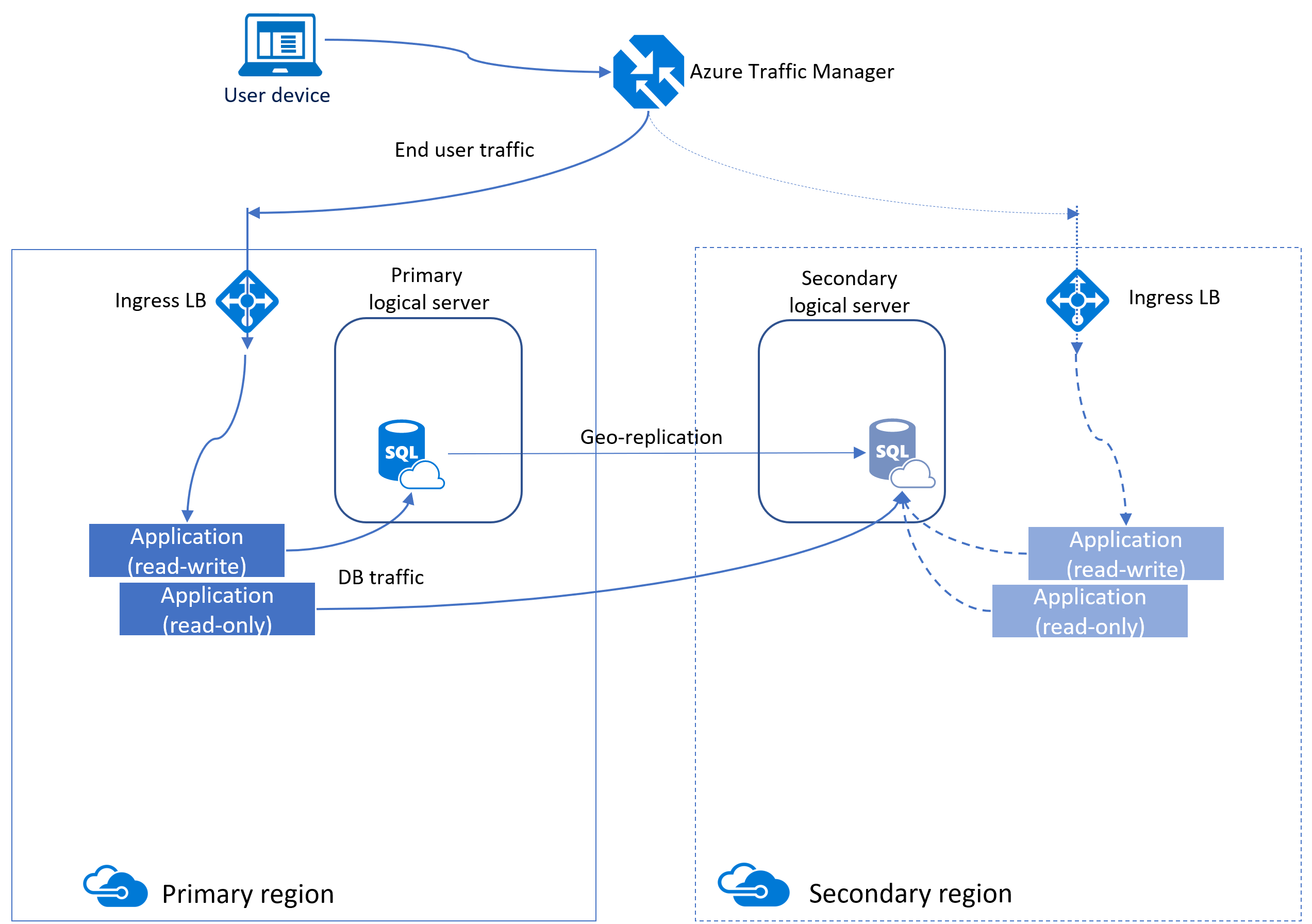
Per evitare un sovraccarico di replica da un carico di lavoro di scrittura di grandi dimensioni che può influire sulle prestazioni di replica, è consigliabile configurare la replica secondaria con lo stesso livello di servizio e le stesse dimensioni di calcolo del database primario.
È possibile configurare manualmente la replica geografica per il database SQL di Azure accedendo alla pagina del database e selezionando Repliche nella sezione Gestione dati .

Dopo aver creato la replica secondaria, è possibile avviare manualmente un failover. Ciò inverte i ruoli, rendendo ciò che è secondario il nuovo primario e il precedente primario il nuovo secondario.

La replica geografica è asincrona, ovvero potrebbe verificarsi un ritardo di dati tra i database primari e secondari. Inoltre, la stringa di connessione dell'applicazione deve essere aggiornata dopo un failover.
Configurare la replica geografica tra sottoscrizioni
In determinati scenari, è necessario configurare una replica secondaria in una sottoscrizione diversa rispetto al database primario. È qui che entra in gioco la replica geografica tra sottoscrizioni. Questa funzionalità consente di configurare una replica secondaria in una sottoscrizione diversa, offrendo maggiore flessibilità e opzioni avanzate di ripristino di emergenza. Usando la replica geografica tra sottoscrizioni, è possibile assicurarsi che i dati siano protetti e accessibili anche se si verificano problemi con una sottoscrizione. Questa configurazione è utile per le organizzazioni con più sottoscrizioni o per coloro che cercano di implementare un piano di continuità aziendale solido.
Per altre informazioni sui passaggi necessari per configurare una replica geografica tra sottoscrizioni, vedere Replica geografica tra sottoscrizioni.
Abilitare i gruppi di failover automatico
Un gruppo di failover automatico è una funzionalità di disponibilità che può essere usata sia con il database SQL di Azure sia con Istanza gestita di SQL di Azure. I gruppi di failover automatico consentono di gestire le modalità di replica dei database in un'altra area e le modalità in cui potrebbe verificarsi il failover. Il nome assegnato al gruppo di failover automatico deve essere univoco all'interno del dominio *.database.windows.net .
I gruppi di failover automatico offrono funzionalità simili ad AG tramite un listener, abilitando sia le attività di lettura/scrittura che di sola lettura. Questa funzionalità è leggermente diversa dalla replica geografica attiva. Esistono due tipi di listener: uno per il traffico di lettura/scrittura e un altro per il traffico di sola lettura. Durante un failover, gli aggiornamenti DNS consentono ai client di connettersi al nome del listener senza che siano necessarie informazioni aggiuntive. Il server di database con le copie di lettura/scrittura è il database primario, mentre il server che riceve le transazioni dal database primario è quello secondario.
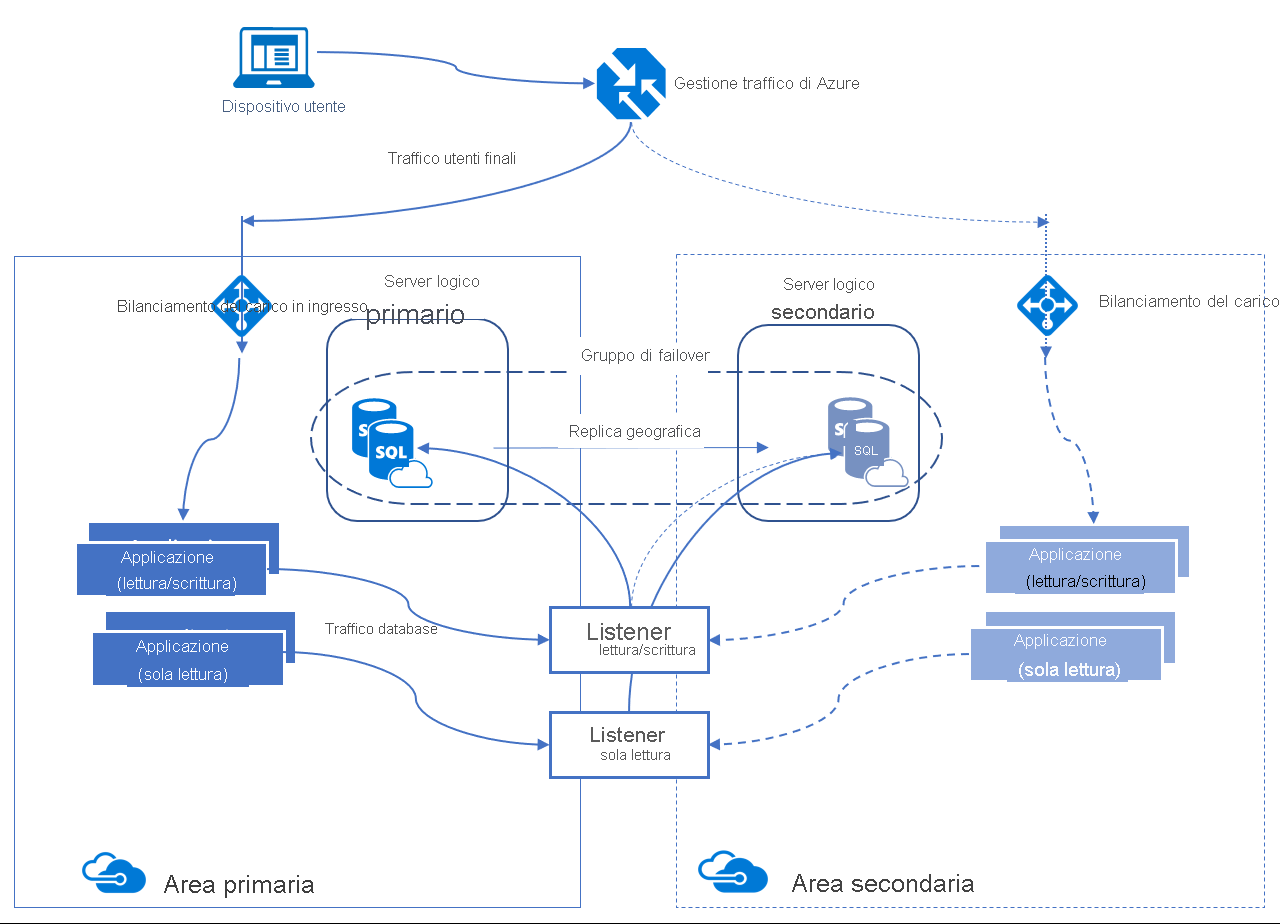
I gruppi di failover automatico hanno due criteri diversi che possono essere configurati.
- Gestito dal cliente (scelta consigliata): i clienti possono avviare manualmente un failover quando rilevano un'interruzione imprevista che interessa uno o più database nel gruppo di failover. Questo failover manuale può essere eseguito usando strumenti da riga di comando come PowerShell, l'interfaccia della riga di comando di Azure o l'API REST.
- Gestito da Microsoft : vengono avviati automaticamente da Microsoft durante un'interruzione diffusa che influisce su un'area primaria. Questo failover automatico si applica a tutti i gruppi di failover interessati con i criteri di failover impostati su Gestione di Microsoft.
Il failover non pianificato può comportare la perdita di dati se forzato e se il database secondario non è perfettamente sincronizzato con il primario. La configurazione GracePeriodWithDataLossHours controlla il tempo di attesa di Azure prima del failover. Il valore predefinito è un'ora. Se l'obiettivo del punto di ripristino è ristretto e non si desidera che si verifichi una notevole perdita di dati, impostare un valore più alto. Anche se Azure attende più a lungo prima del failover, questo approccio potrebbe causare una perdita di dati minore perché il database secondario ha più tempo per eseguire la sincronizzazione completa con il primario.
Inoltre, un gruppo di failover automatico può includere uno o più database, con le stesse dimensioni ed edizioni nei server primari e secondari. Il database nel server secondario viene creato automaticamente tramite un processo denominato seeding, che può richiedere del tempo a seconda delle dimensioni del database. È importante effettuare la pianificazione di conseguenza e prendere in considerazione fattori come la velocità di rete.
Come scegliere
La replica geografica è adatta agli scenari in cui sono necessarie più repliche leggibili e il failover manuale è accettabile, mentre i gruppi di failover automatico sono ideali per scenari che richiedono il failover automatico e la replica sincrona per un gruppo di database.
La tabella seguente confronta le funzionalità della replica geografica e dei gruppi di failover automatico, insieme ad altri dettagli pertinenti.
| Funzionalità | Replica geografica | Gruppi di failover automatico |
|---|---|---|
| Numero di repliche | Supporta fino a quattro repliche secondarie. | Supporta una sola replica secondaria |
| Livello di configurazione | Configurato per ogni database. | Configurato per un gruppo di database |
| Tipo di replica | Asincrona, ovvero potrebbe verificarsi un ritardo di dati tra i database primari e secondari | Sincrona, assicurandosi che il database secondario sia sempre sincronizzato con il database primario. |
| Failover | Richiede il failover manuale. La stringa di connessione dell'applicazione deve essere aggiornata dopo un failover | Supporta il failover automatico e manuale, senza la necessità di modificare le stringhe di connessione dopo un failover |
| Leggibilità | Fornisce database secondari leggibili. | Fornisce database secondari leggibili e funge da hot standby per il failover |
| Caso d'uso | Adatto per scenari in cui sono necessarie più repliche leggibili e failover manuale | Ideale per scenari che richiedono il failover automatico e la replica sincrona per un gruppo di database |