Esplorare la classificazione dei dati
I dati riservati archiviati all'interno di Microsoft SQL Server, database SQL di Azure o Istanza gestita di SQL di Azure devono essere classificati all'interno del database. Questa classificazione consente agli utenti e alle applicazioni di comprendere la riservatezza dei dati archiviati.
La classificazione dei dati viene eseguita su base colonna per colonna. Una singola tabella può avere colonne classificate come pubbliche, riservate o estremamente riservate.
Inizialmente, la classificazione dei dati è stata introdotta in SQL Server Management Studio, usando proprietà estese di oggetti per archiviare le informazioni di classificazione. A partire da SQL Server 2019, questi metadati vengono archiviati in una vista del catalogo denominata sys.sensitivity_classifications. Questa funzionalità è supportata anche dal database SQL di Azure e da Istanza gestita di SQL di Azure.
Il portale di Azure offre un riquadro di gestione per la classificazione dei dati del database SQL di Azure. È possibile accedere a questa funzionalità selezionando Individuazione dati e classificazione nella sezione Sicurezza del pannello principale per il database SQL di Azure.

Sia nel portale di Azure che in SQL Server Management Studio è possibile configurare la classificazione dei dati. Il motore di classificazione analizza il database per identificare le colonne con nomi che suggeriscono che potrebbero contenere informazioni riservate. Ad esempio, una colonna denominata email viene contrassegnata automaticamente come contenente informazioni personali riservate.

Nell'esempio sono disponibili cinque colonne consigliate per la classificazione. Le proprietà Information Type e Sensitivity label sembrano coerenti con il nome della colonna e lo scopo complessivo. Tuttavia, poiché le raccomandazioni sono basate sul nome della colonna, una colonna denominata column1 che contiene indirizzi di posta elettronica non sarebbe consigliata come informazioni personali riservate.
Le colonne possono anche essere classificate usando la procedura guidata per la sensibilità in SQL Server Management Studio o usando il comando T-SQL ADD SENSITIVITY CLASSFICATION come segue.
ADD SENSITIVITY CLASSIFICATION TO
[Application].[People].[EmailAddress]
WITH (LABEL='PII', INFORMATION_TYPE='Email')
GO
La classificazione dei dati consente di identificare facilmente la sensibilità dei dati nel database. Conoscere le colonne che contengono dati sensibili consente controlli più semplici e consente di identificare più facilmente quali colonne sono scelte valide per la crittografia dei dati. La classificazione consente ad altri dipendenti all'interno dell'azienda di prendere decisioni migliori su come gestire i dati disponibili all'interno del database.
Personalizzare la tassonomia di classificazione
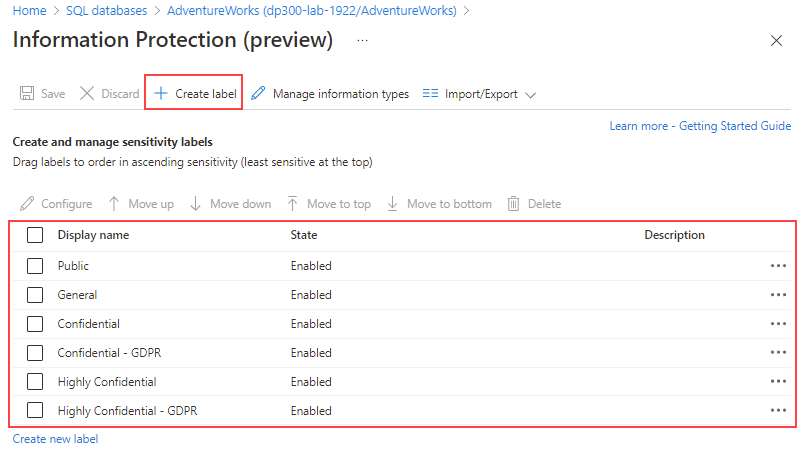
L'individuazione dei dati e la classificazione fanno parte di Microsoft Defender for Cloud. È possibile personalizzare la tassonomia delle etichette di riservatezza e definire un set di regole di classificazione specifiche per l'ambiente.
È possibile creare e gestire le etichette di riservatezza come parte della gestione dei criteri selezionando Individuazione dati e classificazione del pannello principale per il database SQL di Azure e quindi Configura.
Screenshot di come personalizzare la tassonomia di classificazione dal portale di Azure.
Nella pagina Information Protection è possibile definire etichette, classificarle e collegarle a un set di tipi di informazioni.
Dopo aver definito i modelli, questi vengono aggiunti automaticamente alla logica di individuazione per identificare questo tipo di dati nei database e sono immediatamente disponibili.
Annotazioni
Solo gli utenti con diritti amministrativi per il gruppo di gestione radice dell'organizzazione possono creare e gestire etichette di riservatezza.