Esplorare i classificatori sottoponibili a training
Le organizzazioni classificano ed etichettano i contenuti per poterli proteggere e gestire correttamente. La classificazione e l'etichettatura dei contenuti è il punto di partenza della disciplina della protezione delle informazioni. Microsoft 365 offre tre modi per classificare i contenuti:
Manualmente. La classificazione manuale richiede giudizio e azione umana. Gli utenti e gli amministratori li applicano ai contenuti man mano che li rilevano. È possibile utilizzare le etichette e i tipi di informazioni riservate preesistenti o crearne di personalizzati. È quindi possibile proteggere i contenuti e gestirne la disposizione.
Corrispondenza automatica dei modelli. Questa categoria di meccanismi di classificazione comprende la ricerca di contenuti in base a:
- Parole chiave o valori di metadati (keyword query language).
- Utilizzo di schemi precedentemente identificati di informazioni sensibili come numeri di previdenza sociale, carte di credito o conti bancari.
- Riconoscimento di un elemento perché è una variante di un modello (stampa digitale dei documenti, di cui tratta un'unità successiva di questo training).
- Utilizzando la presenza di stringhe esatte, si ottiene una corrispondenza esatta dei dati.
Classificatori sottoponibili a training Un classificatore sottoponibile a training di Microsoft 365 è uno strumento che un'organizzazione può "addestrare" a riconoscere vari tipi di contenuti. Microsoft 365 include un ampio elenco di classificatori predefiniti. Le organizzazioni possono anche creare classificatori personalizzati. È possibile eseguire il training dei classificatori fornendo loro esempi da esaminare. Dopo aver eseguito il training di un classificatore, l'organizzazione può usarlo per identificare gli elementi per l'applicazione di etichette di riservatezza di Office, criteri di conformità delle comunicazioni e criteri delle etichette di conservazione.
Questa unità esamina l'uso di classificatori sottoponibili a training.
Classificatori sottoponibili a training
Per iniziare a usare classificatori sottoponibili a training in Microsoft Purview, è innanzitutto possibile avviare un processo di analisi. Questo processo analizza i dati dell'azienda e identifica i modelli che il sistema può usare per eseguire il training del classificatore. Dopo l'analisi dei dati, il sistema identifica i temi e i modelli comuni. Il sistema può quindi creare regole per il classificatore sottoponibile a training usando queste informazioni. Questo processo consente di garantire che il classificatore sottoponibile a training sia accurato ed efficace nell'identificazione e nella categorizzazione dei dati. Al termine del processo di analisi, è possibile eseguire il training del classificatore sottoponibile a training usando i modelli e le regole identificati. Dopo aver completato il training del classificatore, è possibile applicarlo ai nuovi dati per classificarlo automaticamente.
Avviso
Il completamento dell'analisi può richiedere da 7 a 14 giorni. Se non si desidera eseguire il processo di scansione per creare un classificatore di training personalizzato per la propria organizzazione, è possibile utilizzare i classificatori integrati di Microsoft Purview.
La prima volta che si accede alla pagina Classificatori di training nel Portale di conformità di Microsoft Purview, viene visualizzato lo screenshot seguente.
La creazione di un classificatore sottoponibile a training personalizzato comporta innanzitutto la distribuzione di esempi selezionati manualmente e che corrispondono in modo positivo alla categoria. Quindi, dopo che lo strumento di classificazione sottoponibile al training elabora questi esempi, si testa la capacità dei classificatori di stimare fornendo una combinazione di campioni positivi e negativi. Questa unità esamina come creare ed eseguire il training di un classificatore personalizzato. Esamina anche come migliorare le prestazioni dei classificatori sottoponibili a training personalizzati e dei classificatori con training preliminare nel corso della loro durata attraverso la ripetizione del training.
Il metodo di classificazione funziona bene sul contenuto che i metodi di ricerca automatici o manuali non possono identificare facilmente. Questo metodo di classificazione consiste nell'utilizzare un classificatore per identificare un elemento in base a ciò che l'elemento è, non in base agli elementi presenti nell'elemento (pattern matching). Un classificatore apprende come identificare un tipo di contenuto esaminando centinaia di esempi di tale tipo di contenuto.
Nota
È possibile visualizzare i classificatori sottoponibili a training nello strumento Esplora contenuto espandendo i classificatori sottoponibili a training nel pannello dei filtri. I classificatori sottoponibili a training visualizzano automaticamente il numero di eventi imprevisti rilevati in SharePoint, Teams e OneDrive, senza richiedere alcuna etichettatura. Se non si vuole usare questa funzionalità, è necessario presentare una richiesta con Supporto tecnico Microsoft per disabilitare la classificazione predefinita. In questo modo viene disabilitata l'analisi del contenuto sensibile ed etichettato prima di creare criteri di etichettatura.
I classificatori sono disponibili per l'uso come condizione per:
- Etichettatura automatica di Office con etichette di riservatezza
- Applicazione automatica di un criterio di etichetta di conservazione in base a una condizione
- Conformità delle comunicazioni
Nota
I classificatori funzionano solo con elementi non crittografati.
Esistono due tipi di classificatori sottoponibili a training:
- Classificatori con training preliminare. Microsoft ha creato e eseguito il training preliminare di più classificatori che è possibile iniziare a usare senza eseguirne il training. Questi classificatori vengono visualizzati con lo stato Pronto per l'uso.
- Classificatori sottoponibili a training personalizzati. Se un'organizzazione ha esigenze di classificazione che vanno oltre la copertura dei classificatori con training preliminare, può creare ed eseguire il training dei propri classificatori.
Le sezioni seguenti esaminano questi tipi di classificatore.
Classificatori con training preliminare
Microsoft 365 include più classificatori con training preliminare:
Adulti, Racy e Gory. Rileva le immagini di questi tipi. Le immagini devono avere dimensioni comprese tra 50 kilobyte (KB) e 4 megabyte (MB). Devono anche essere maggiori di 50 x 50 pixel in dimensioni di altezza x larghezza. Il sistema supporta l'analisi e il rilevamento dei messaggi di posta elettronica di Exchange Online e dei canali e delle chat di Microsoft Teams.
Contratti. Questo classificatore rileva il contenuto correlato ai contratti legali. Ad esempio, dichiarazioni di lavoro, contratti di prestito e di locazione, accordi di lavoro e di non concorrenza.
Reclami dei clienti. Il classificatore di reclami dei clienti rileva i feedback e i reclami relativi ai prodotti o ai servizi dell'organizzazione. Questo classificatore può aiutarti a soddisfare i requisiti normativi per il rilevamento e il triage dei reclami, come quelli del Consumer Financial Protection Bureau e della Food and Drug Administration.
Discriminazione. Questo classificatore rileva un linguaggio esplicito discriminante ed è sensibile al linguaggio discriminante nei confronti delle comunità afro-statunitensi/nere rispetto ad altre community.
Contabilità. Questo classificatore rileva i contenuti delle categorie finanza aziendale, contabilità, economia, banche e investimenti.
Molestie. Questo classificatore rileva una categoria specifica di articoli di testo dal linguaggio offensivo. Questi elementi devono riguardare una condotta offensiva che prende di mira uno o più individui in base ai seguenti tratti: razza, etnia, religione, origine nazionale, sesso, orientamento sessuale, età, disabilità.
Settore sanitario. Questo classificatore rileva i contenuti relativi ad aspetti medici e di amministrazione sanitaria. Ad esempio, servizi medici, diagnosi, trattamenti, richieste di risarcimento e così via.
Risorse umane (HR). Questo classificatore rileva i contenuti delle categorie relative alle risorse umane. Ad esempio, reclutamento, colloqui, assunzione, formazione, valutazione, ammonimento e licenziamento.
Proprietà intellettuale (IP). Questo classificatore rileva i contenuti delle categorie legate alla proprietà intellettuale, come i segreti commerciali e altre informazioni riservate.
Information Technology (IT). Questo classificatore rileva i contenuti delle categorie Information Technology e Cybersecurity. Ad esempio, le impostazioni di rete, la sicurezza delle informazioni, l'hardware e il software.
Affari legali. Questo classificatore rileva i contenuti delle categorie legate agli affari legali. Ad esempio, contenzioso, processo legale, obbligo legale, terminologia legale, legge e legislazione.
Approvvigionamento. Questo classificatore rileva i contenuti nelle categorie di offerte, preventivi, acquisti e pagamenti per la fornitura di beni e servizi.
Profanità. Questo classificatore rileva una categoria specifica di elementi di testo dal linguaggio offensivo che contengono espressioni che mettono in imbarazzo la maggior parte delle persone.
Curriculum. Questo classificatore rileva gli elementi docx, .pdf, .rtf e .txt che sono resoconti testuali delle qualifiche personali, educative, professionali, dell'esperienza lavorativa e di altre informazioni di identificazione personale di un candidato.
Codice sorgente. Questo classificatore rileva gli elementi che contengono una serie di istruzioni e dichiarazioni scritte nei 25 linguaggi di programmazione informatica più utilizzati su GitHub: ActionScript, C, C#, C++, Clojure, CoffeeScript, Go, Haskell, Java, JavaScript, Lua, MATLAB, Objective-C, Perl, PHP, Python, R, Ruby, Scala, Shell, Swift, TeX, Vim Script.
Nota
Il classificatore Codice sorgente rileva quando la maggior parte del testo è costituita da codice sorgente. Non rileva il testo del codice sorgente intervallato da testo normale.
Imposte. Questo classificatore rileva i contenuti relativi alle imposte, come la pianificazione fiscale, i moduli fiscali, la compilazione delle imposte e le normative fiscali.
Minacce. Questo classificatore rileva una categoria specifica di testi in linguaggio offensivo relativi a minacce di commettere violenza o di arrecare danni fisici o materiali a una persona o a una proprietà.
Questi classificatori sottoponibili a training vengono visualizzati nel portale di conformità di Microsoft Purview. Nel riquadro di spostamento selezionare Classificazione dati. Nella pagina Classificazione dati selezionare la scheda Classificatori sottoponibili a training. Visualizzare i classificatori con lo stato Pronto per l'uso.
Classificatori personalizzati
Per alcune organizzazioni, i classificatori con training preliminare non soddisfano le proprie esigenze di classificazione dei dati. In questo caso, un'organizzazione può creare ed eseguire il training dei propri classificatori. La creazione di un classificatore personalizzato richiede più lavoro, ma un'organizzazione può adattarlo alle proprie esigenze. I passaggi generali necessari per la creazione di un classificatore personalizzato includono:
- Si inizia a creare un classificatore sottoponibile a training personalizzato fornendogli esempi che rientrano sicuramente nella categoria.
- Una volta che il classificatore elabora questi esempi, lo si testa fornendogli un mix di esempi corrispondenti e non corrispondenti.
- Il classificatore fa quindi delle previsioni per stabilire se un dato articolo rientra nella categoria che si sta compilando.
- Si confermano quindi i risultati, selezionando i veri positivi, i veri negativi, i falsi positivi e i falsi negativi per aumentare l'accuratezza delle previsioni.
- Una volta soddisfatti dei risultati del test, si distribuisce il classificatore pubblicandolo.
Quando si pubblica il classificatore, questo ordina gli elementi in posizioni come SharePoint Online, Exchange e OneDrive e classifica il contenuto. Dopo aver pubblicato il classificatore, è possibile continuare a eseguirne il training usando un processo di feedback simile al processo di training iniziale.
Ad esempio, è possibile creare classificatori sottoponibili a training per:
- Documenti legali. Ad esempio, il segreto professionale, le arringhe e le dichiarazioni di lavoro.
- Documenti aziendali strategici. Ad esempio, comunicati stampa, fusioni e acquisizioni, accordi, piani aziendali o di marketing, proprietà intellettuale, brevetti e documenti di design.
- Informazioni sui prezzi. Ad esempio, fatture, preventivi, ordini di lavoro e documenti di offerta.
- Informazioni finanziarie. Ad esempio, gli investimenti organizzativi e i risultati trimestrali o annuali.
Preparare un classificatore sottoponibile a training personalizzato
Prima di approfondire, è utile comprendere i componenti coinvolti nella creazione di un classificatore sottoponibile a training personalizzato. Le sezioni seguenti esaminano ognuno di questi componenti.
Sequenza temporale
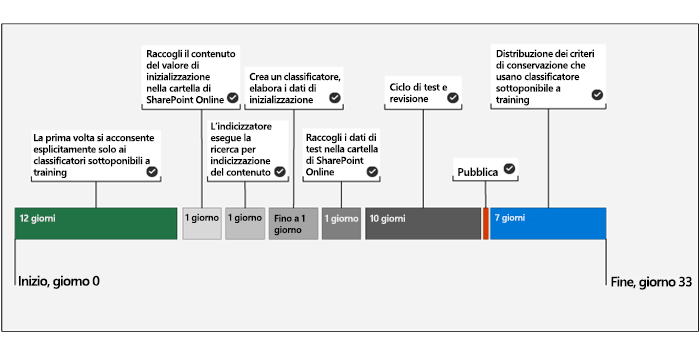
Il diagramma seguente mostra una sequenza temporale che riflette una distribuzione di esempio di classificatori sottoponibili a training.
Consiglio
Il sistema richiede un consenso esplicito per la prima volta per i classificatori sottoponibili a training. Sono necessari 12 giorni prima che Microsoft 365 completi una valutazione di base del contenuto di un'organizzazione. Un amministratore di Microsoft 365 Global deve avviare il processo di consenso esplicito.
Flusso di lavoro complessivo
Per altre informazioni sul flusso di lavoro complessivo della creazione di classificatori sottoponibili a training personalizzati, vedere Flusso di processo per la creazione di classificatori sottoponibili a training personalizzati.
Contenuto di inizializzazione
Microsoft Purview usa classificatori sottoponibili a training per identificare in modo indipendente e accurato un elemento come categoria specifica di contenuto. Per creare un classificatore sottoponibile a training, un'organizzazione deve prima presentargli molti esempi del tipo di contenuto incluso nella categoria. Il seeding è il processo di inserimento dei campioni nel classificatore sottoponibile a training. Un'organizzazione deve selezionare il contenuto campione che vuole usare per rappresentare la categoria di contenuto.
Consiglio
È necessario avere almeno 50 campioni positivi, con un massimo di 500. esempi. Il classificatore sottoponibile al training elabora fino ai 500 esempi creati più di recente (in base alla data/ora di creazione del file). Maggiore è il numero di esempi forniti, più accurate sono le stime che il classificatore esegue.
Test del contenuto
Dopo che il classificatore sottoponibile a training elabora campioni positivi sufficienti per compilare un modello di stima, l'organizzazione deve testare le stime del classificatore. È consigliabile eseguire il test con dati diversi rispetto ai dati di inizializzazione iniziali specificati per la prima volta. Il test deve verificare se il classificatore è in grado di distinguere correttamente tra gli elementi che corrispondono alla categoria e quelli che non lo fanno. I test devono iniziare selezionando un altro set di contenuto selezionato manualmente, probabilmente più grande, noto come esempio di test. Deve essere costituito da campioni che rientrano nella categoria e da esempi che non rientrano nella categoria.
Dopo che il classificatore ha elaborato questo esempio di test, è necessario esaminare manualmente i risultati. Quando si esegue questa operazione, è necessario verificare se ogni stima è corretta, non corretta o non si è certi. Il classificatore sottoponibile a training usa questo feedback per migliorare il modello di stima.
Consiglio
Per risultati ottimali, includere almeno 200 elementi nell'esempio di test. Deve includere una distribuzione uniforme di corrispondenze positive e negative.