Transizione dalle operazioni per l'apprendimento automatico (MLOps) tradizionali alle operazioni per modelli linguistici di grandi dimensioni (LLMOps)
MLOps (operazioni per l'apprendimento automatico) e LLMOps (operazioni per modelli linguistici di grandi dimensioni) rappresentano due paradigmi distinti nell'operazionismo di modelli di apprendimento automatico, ognuno con un proprio insieme di problematiche, strumenti e flussi di lavoro.
Mentre le operazioni per l'apprendimento automatico (MLOps) tradizionali sono incentrate sulla distribuzione e sulla gestione di un'ampia gamma di modelli di apprendimento automatico, le operazioni per modelli linguistici di grandi dimensioni (LLMOps) sono adattate in modo specifico per modelli linguistici di grandi dimensioni (LLMs) che hanno requisiti univoci in termini di scalabilità, gestione dei dati e ottimizzazione del modello.
Azure Databricks supporta sia operazioni per l'apprendimento automatico (MLOps) che operazioni per modelli linguistici di grandi dimensioni (LLMOps), ma i dettagli di implementazione variano in modo significativo. Verrà esaminata la differenza confrontando operazioni per l'apprendimento automatico (MLOps) e operazioni per modelli linguistici di grandi dimensioni (LLMOps).
Confrontare operazioni per l'apprendimento automatico (MLOps) e operazioni per modelli linguistici di grandi dimensioni (LLMOps)
L'apprendimento automatico tradizionale generalmente prevede il training di un modello, ad esempio un modello di regressione o una rete neurale più complessa.
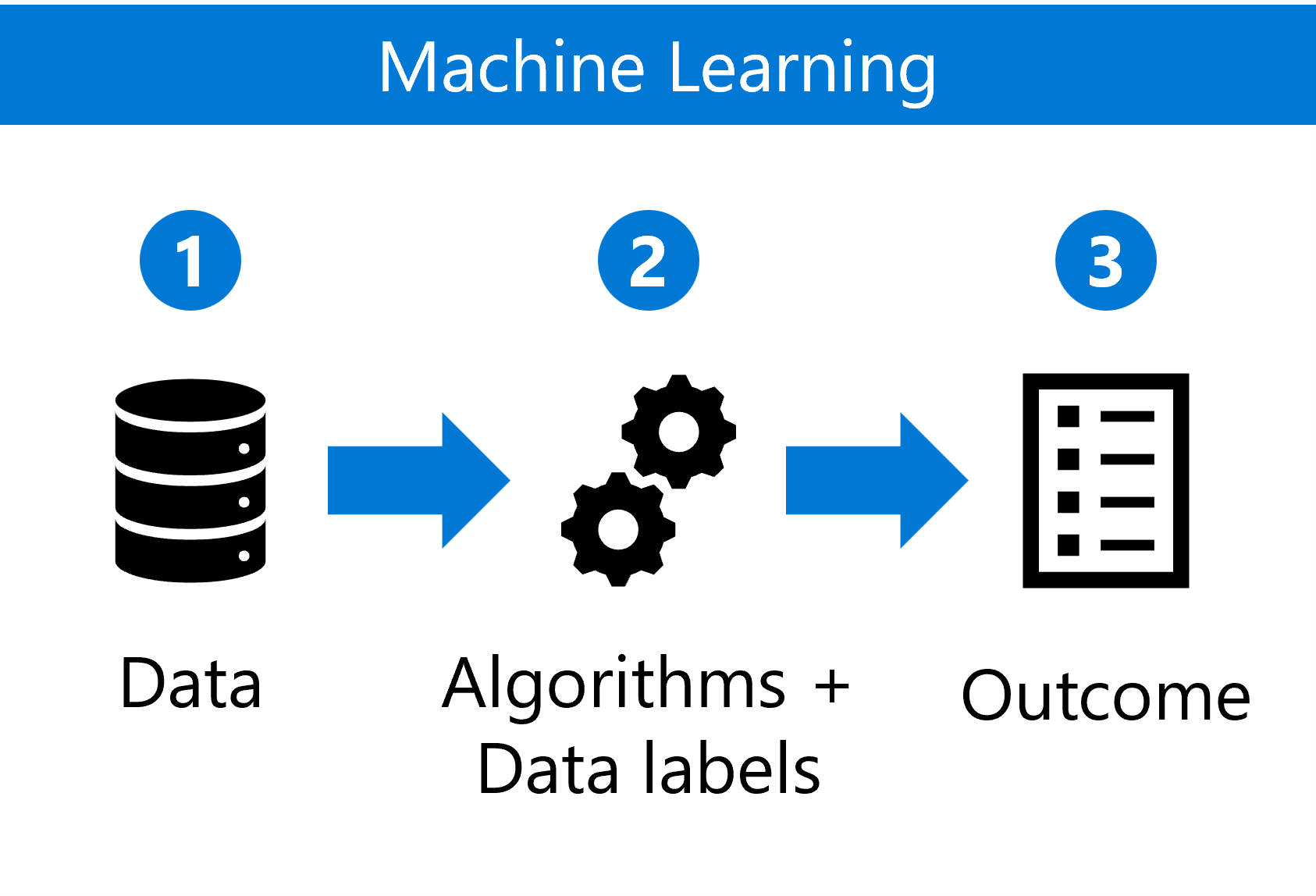
Il processo di apprendimento automatico include:
- Raccolta, esplorazione e preparazione di un set di dati appropriato.
- Scelta di un algoritmo e definizione di etichette dati.
- Uso del modello addestrato per la generazione di previsioni sui nuovi dati.
L'obiettivo operativo è garantire che questi modelli possano essere ridimensionati in modo efficiente in vari ambienti e volumi di dati.
Azure Databricks facilita le operazioni per l'apprendimento automatico (MLOps) fornendo risorse di calcolo scalabili, integrazione con Azure Machine Learning e strumenti come MLflow per il rilevamento e la distribuzione dei modelli.
Le operazioni per modelli linguistici di grandi dimensioni (LLMOps), invece, gestiscono modelli linguistici con training preliminare che funzionano con costrutti come input basati su testo, noti come prompt.
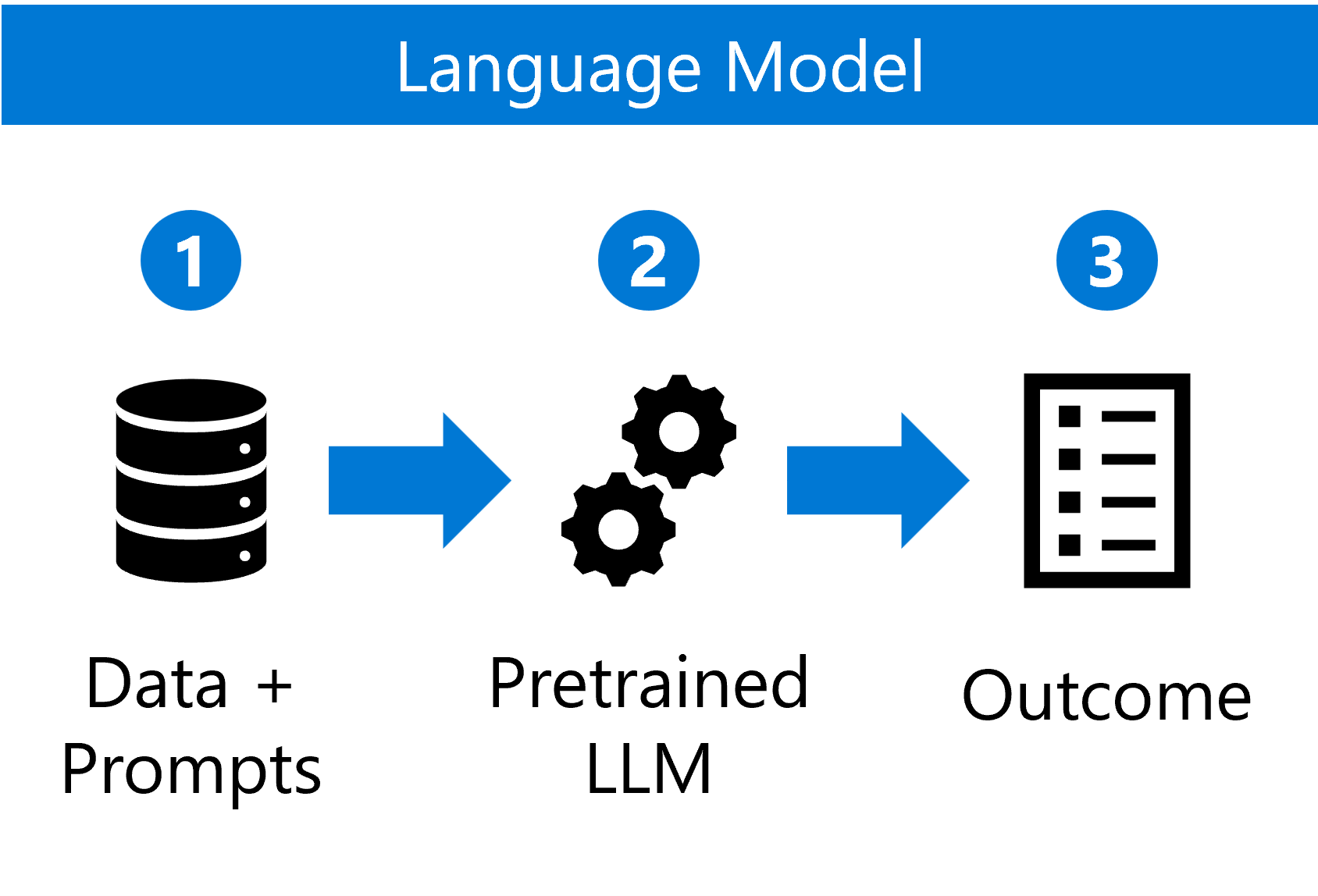
Il processo di utilizzo di un modello linguistico include:
- Combinazione di dati con prompt previsti.
- Scelta e configurazione di un modello linguistico preaddestrato.
- Utilizzo del modello configurato per generare risposte su nuovi prompt.
Le operazioni per modelli linguistici di grandi dimensioni (LLMOps) gestiscono modelli di ordini di grandezza maggiori, ad esempio GPT-3 o GPT-4. I modelli linguistici di grandi dimensioni (LLMs) richiedono non solo una maggiore potenza di calcolo, ma anche un'infrastruttura specializzata per gestirne la scalabilità.
Azure Databricks offre cluster ottimizzati, elaborazione distribuita e l'integrazione con Azure OpenAI, consentendo la distribuzione di modelli linguistici di grandi dimensioni (LLMs) su larga scala.
Quando si confrontano operazioni per l'apprendimento automatico (MLOps) e operazioni per modelli linguistici di grandi dimensioni (LLMOps), è necessario comprendere alcune differenze principali.
Gestire dati di testo non strutturati
Nelle operazioni per l'apprendimento automatico (MLOps) tradizionali, la gestione dei dati è incentrata su dati strutturati e semistrutturati. All'interno della gestione dei dati, l'attenzione è posta sulla pre-elaborazione dei dati, sull'ingegneria delle funzionalità e sull'automazione delle pipeline.
Le operazioni per modelli linguistici di grandi dimensioni (LLMOps), tuttavia, richiedono la gestione grandi quantità di dati di testo non strutturati, richiedendo pipeline di inserimento e pre-elaborazione dei dati più sofisticate.
Azure Databricks, combinato con Microsoft Fonderia, consente l'inserimento e l'elaborazione di corpus di testo di grandi dimensioni, permettendo il training efficiente e l'ottimizzazione di modelli linguistici di grandi dimensioni (LLM).
Ottimizzare invece di eseguire il training da zero
Le operazioni per l'apprendimento automatico (MLOps) tradizionali comportano spesso il training del modello iterativo e l'ottimizzazione degli iperparametri, con particolare attenzione all'ottimizzazione delle prestazioni del modello per attività specifiche. Strumenti come Hyperopt e AutoML (Machine Learning automatizzato) in Azure Databricks consentono di automatizzare questi processi.
Le operazioni per modelli linguistici di grandi dimensioni (LLMOps), tuttavia, pongono una maggiore enfasi sull'ottimizzazione dei modelli con training preliminare in attività o domini specifici.
Azure Databricks supporta l'ottimizzazione tramite l'integrazione con il servizio OpenAI di Azure, consentendo agli utenti di ottimizzare modelli linguistici di grandi dimensioni (LLMs) come GPT-4 con modifiche minime al codice, usando la potenza dell'elaborazione distribuita per tempi di training più rapidi.
Utilizzare il modello distribuito
Nelle operazioni per l'apprendimento automatico (MLOps) tradizionali, la distribuzione implica l'integrazione di modelli in sistemi di produzione tramite API REST, elaborazione batch o endpoint di inferenza in tempo reale.
Tuttavia, nelle operazioni per modelli linguistici di grandi dimensioni (LLMOps), la distribuzione avviene prima nel ciclo di vita perché si lavora con modelli con training preliminare e ci si concentra sulla configurazione della modalità con cui chiamare questi modelli distribuiti. Nelle operazioni per modelli linguistici di grandi dimensioni (LLMOps) le strategie di distribuzione differiscono dalle procedure di operazioni per l'apprendimento automatico (MLOps) tradizionali.
Azure Databricks offre endpoint gestiti per la distribuzione di modelli linguistici di grandi dimensioni (LLMs), con monitoraggio e registrazione predefiniti per garantire prestazioni e affidabilità del modello in ambienti di produzione. In alternativa, è possibile distribuire LLM con Azure OpenAI e Microsoft Foundry e poi utilizzarli e configurarli in Azure Databricks.
Proteggere il sistema e implementare l'intelligenza artificiale responsabile
La governance, la conformità e l'uso responsabile dell'IA sono critici nelle operazioni per l'apprendimento automatico (MLOps) tradizionali. Ciò vale in particolare nei settori come finanza e sanità, in cui i modelli devono rispettare rigidi requisiti normativi.
Le operazioni per modelli linguistici di grandi dimensioni (LLMOps) introducono altre problematiche in questa area:
- Sicurezza dei contenuti e moderazione sono necessari per impedire la diffusione di informazioni dannose.
- Jailbreak e misure di sicurezza proteggono da attacchi antagonisti.
- Garantire trasparenza e spiegabilità genera attendibilità con l'assunzione di decisioni comprensibili del modello.
- Monitoraggio continuo e cicli di feedback mantengono l'accuratezza, l'equità e la sicurezza del modello nel tempo.
Quando si affrontano queste problematiche, si garantisce che i modelli linguistici di grandi dimensioni (LLMs) vengano sviluppati e distribuiti in modo responsabile, rispettando i più elevati standard di governance, conformità e procedure di IA responsabili.