Definire l'architettura, i componenti e le funzionalità della deduplicazione dei dati
La maggior parte delle organizzazioni e delle aziende, incluso Contoso, deve gestire l'elaborazione e l'archiviazione di un volume crescente di dati. Benché siano disponibili soluzioni che consentono di eseguire l'offload e archiviare i dati sul cloud, in molti casi è necessario mantenerli nei data center locali. Una gestione efficiente dell'archiviazione di tali dati richiede strumenti appropriati. Quando si usa Windows Server, è possibile usare Deduplicazione dati per questa finalità.
Che cos’è la deduplicazione dei dati?
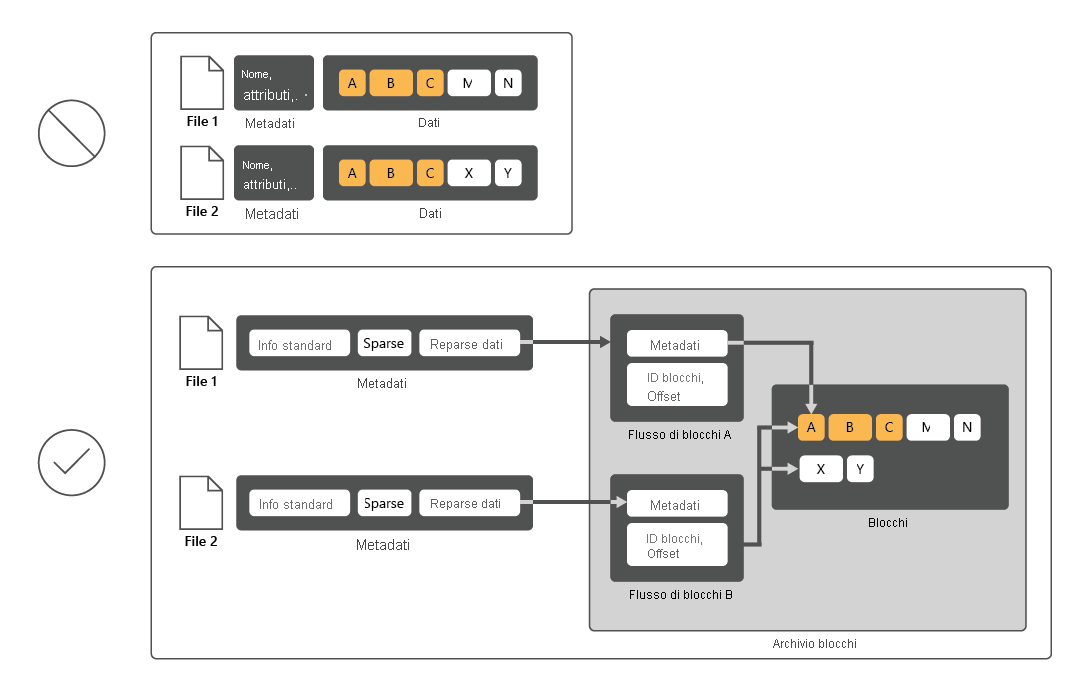
La deduplicazione dei dati è un ruolo di servizio di Windows Server che identifica e rimuove le duplicazioni nei dati senza compromettere l'integrità. consentendo di realizzare gli obiettivi di archiviazione di una quantità superiore di dati e di riduzione dell'uso dello spazio su disco fisico.
Per ridurre l'utilizzo del disco, la Deduplicazione dei dati analizza i file, quindi li divide in blocchi e conserva solo una copia di ogni blocco. Dopo la deduplicazione, i file non vengono più archiviati come flussi di dati indipendenti. Deduplicazione dati, invece, sostituisce i file con stub che puntano a blocchi di dati archiviati in un archivio blocchi comune. Il processo di accesso ai dati deduplicati è trasparente per utenti e app.
In molti casi la deduplicazione dei dati incrementa le prestazioni complessive del disco, perché più file possono condividere una porzione memorizzata nella cache. Grazie a questo approccio, potrebbe essere possibile recuperare dati da questi file eseguendo un numero inferiore di operazioni di lettura, in modo da compensare per un piccolo impatto sulle prestazioni durante la lettura dei file deduplicati. Deduplicazione dati non ha alcun impatto sulle prestazioni delle operazioni di scrittura su disco, perché è applicabile ai dati già presenti sul disco.
Quali sono i componenti della deduplicazione dei dati?
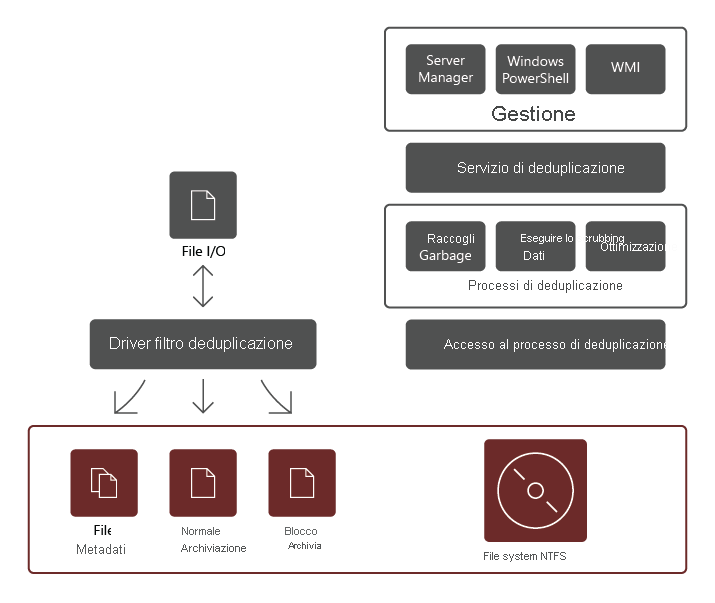
Il ruolo del servizio di deduplicazione dei dati è costituito dai componenti seguenti:
- Driver di filtro. Questo componente reindirizza le richieste di lettura ai blocchi che fanno parte del file richiesto. È presente un driver di filtro per ogni volume.
- Servizio di deduplicazione. Questo componente gestisce i processi seguenti:
- Deduplicazione e compressione. Queste attività elaborano i file in base al criterio di deduplicazione dei dati per il volume specifico. Dopo l'ottimizzazione iniziale di un file, se il file viene quindi modificato e soddisfa la soglia dei criteri di deduplicazione dati per l'ottimizzazione, il file verrà nuovamente ottimizzato.
- Raccolta dei rifiuti. Questo processo elabora i dati eliminati o modificati nel volume, in modo che i blocchi di dati a cui non viene più fatto riferimento vengano puliti, liberando spazio su disco. Per impostazione predefinita, l'operazione di Garbage Collection viene eseguita ogni settimana, ma è anche possibile richiamarla dopo l'eliminazione di molti file.
- Scrubbing. Questo processo si basa su funzionalità di resilienza come la convalida del checksum e la verifica della coerenza dei metadati per identificare e, se possibile, risolvere automaticamente i problemi di integrità dei dati.
Nota
Grazie alle funzionalità aggiuntive di convalida, la deduplicazione può rilevare e segnalare i primi segni di danneggiamento dei dati.
- Annullamento dell'ottimizzazione. Questo processo inverte la deduplicazione su tutti i file ottimizzati nel volume. Alcuni degli scenari comuni per l'uso di questo tipo di attività includono la risoluzione di problemi relativi ai dati deduplicati o alla migrazione di dati a un altro sistema che non supporta Deduplicazione dei Dati.
Nota
Prima di iniziare questo processo, è necessario usare il cmdlet Disable-DedupVolume di Windows PowerShell per disabilitare un'ulteriore attività di deduplicazione dei dati in uno o più volumi.
Nota
Dopo la disabilitazione di Deduplicazione dati, il volume rimane nello stato deduplicato e i dati deduplicati esistenti rimangono accessibili. Il server interrompe tuttavia l'esecuzione dei processi di ottimizzazione per il volume e non deduplica i nuovi dati. Successivamente, è possibile usare il processo di annullamento dell'ottimizzazione per annullare i dati deduplicati esistenti in un volume. Al termine di un processo di deottimizzazione con esito positivo, tutti i metadati della deduplicazione dati vengono eliminati dal volume.
Importante
Quando si utilizza l'attività di disottimizzazione, verificare che il volume che ospita questi dati abbia spazio libero sufficiente, perché tutti i file deduplicati tornano alle loro dimensioni originali.
Ambito di Deduplicazione dati
Il processo di deduplicazione dei dati elabora tutti i dati di un volume selezionato, con alcune eccezioni, tra cui:
- File che non soddisfano i criteri di deduplicazione configurati.
- File in cartelle escluse esplicitamente dall'ambito della deduplicazione.
- File di stato del sistema.
- Flussi di dati alternativi.
- File crittografati.
- File con attributi estesi.
- File di dimensioni inferiori a 32 KB.
Nota
A partire da Windows Server 2019, Resilient File System (ReFS) supporta la deduplicazione dei dati per volumi fino a 64 terabyte (TB) di dimensioni e file di dimensioni fino a 4 TB. Si basa inoltre su un archivio blocchi di dimensioni variabili che include la compressione facoltativa per ottenere il risparmio massimo possibile di spazio su disco, mentre l'architettura di post-elaborazione a thread multipli mantiene al minimo l'effetto sulle prestazioni.