Definire i casi d'uso e l'interoperabilità di Deduplicazione dati
Le ottimizzazioni offerte da Deduplicazione dati dipendono da tipo di dati, combinazione di dati, dimensioni dei volumi e file inclusi in tali volumi. È possibile scegliere di valutare l'ottimizzazione per volume prima di abilitare la deduplicazione.
Casi d'uso di Deduplicazione dati
Nell'elenco seguente sono riportati gli scenari di deduplicazione tipici e la rispettiva ottimizzazione spazio del volume:
| Caso d'uso | Contenuto | Ottimizzazione spazio |
|---|---|---|
| Documenti degli utenti | Pubblicazione o condivisione del contenuto dei gruppi, home directory degli utenti e reindirizzamento del profilo per l'accesso ai file offline | Dal 30 al 50% |
| Condivisioni di distribuzione software | File binari del software, file CAB, file di simboli, immagini e aggiornamenti | Dal 70 all'80% |
| Librerie di virtualizzazione | archiviazione di file di disco rigido virtuale (file con estensione vhd e vhdx) per il provisioning in hypervisor | Dall'80 al 95% |
| Condivisioni file generali | combinazione di tutti i tipi di dati identificati in precedenza | Dal 50 al 60% |
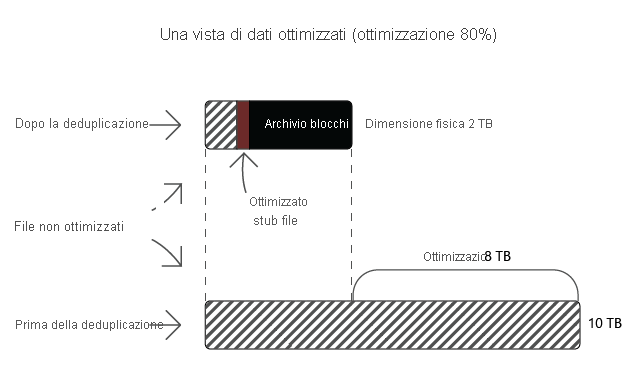
Casi d'uso consigliati per Deduplicazione dati
In base alle ottimizzazioni potenziali e all'utilizzo tipico delle risorse in Windows Server, i candidati alla distribuzione per la deduplicazione sono classificati come ideali, da valutare o candidati non ideali.
- Candidati ideali per la deduplicazione:
- Server di reindirizzamento cartelle.
- Archivio di virtualizzazione o libreria di provisioning.
- Condivisioni di distribuzione software.
- Volumi di backup di Microsoft SQL Server e Microsoft Exchange Server.
- File nei volumi condiviso cluster di File server di scalabilità orizzontale.
- Dischi rigidi virtuali di backup virtualizzati, ad esempio, Microsoft System Center Data Protection Manager.
- Dischi rigidi virtuali dell'infrastruttura VDI (Virtualized Desktop Infrastructure). Solo infrastrutture VDI personali.
Importante
Nella maggior parte delle distribuzioni dell'infrastruttura VDI è necessaria una pianificazione speciale per prendere in considerazione gli eventi "boot storm". Questo termine si riferisce alla situazione in cui molti utenti provano ad accedere simultaneamente alla propria infrastruttura VDI, in genere all'inizio di una giornata lavorativa. Un evento "boot storm" impone un carico elevato sul sistema di archiviazione VDI e può causare ritardi prolungati per gli utenti dell'infrastruttura VDI durante l'accesso iniziale. È possibile ridurre al minimo l'effetto degli eventi "boot storm" abilitando la deduplicazione. In questo modo, i blocchi letti dall'archivio di deduplicazione su disco durante l'avvio delle macchine virtuali vengono memorizzati nella cache in memoria. Le operazioni di lettura successive non richiedono quindi l'accesso frequente ai blocchi sul disco, perché sono disponibili nella cache.
Candidati da valutare in base al contenuto:
- Server line-of-business.
- Provider di contenuto statico.
- Server Web.
- HPC (High-performance computing).
Candidati non ideali per la deduplicazione:
- Windows Server Update Services (WSUS)
- Volumi di database di SQL Server ed Exchange Server.
Valutare il risparmio con lo strumento di valutazione della deduplicazione
È possibile usare lo strumento di valutazione della deduplicazione, DDPEval.exe, per determinare le ottimizzazioni previste dalla deduplicazione su un volume specifico. DDPEval.exe supporta la valutazione di unità locali e di condivisioni remote mappate o non mappate.
Suggerimento
Quando si installa la funzionalità di deduplicazione, DDPEval.exe viene installato automaticamente nella directory \Windows\System32\.
Interoperabilità di Deduplicazione dati
In Windows Server è consigliabile prendere in considerazione le tecnologie correlate seguenti e i potenziali problemi durante la distribuzione di Deduplicazione dati:
Windows BranchCache
È possibile ottimizzare l'accesso ai dati su rete WAN (Wide Area Network) abilitando BranchCache nei sistemi operativi Windows Server e Client Windows. Quando si combinano le due tecnologie, tutti i file deduplicati sono già indicizzati e con hash, e ciò accelera l'elaborazione delle richieste di dati da una succursale. Questo approccio è simile alla preindicizzazione o alla creazione preliminare di hash per un server abilitato per BranchCache.
Nota
BranchCache è una funzionalità che può ridurre l'uso di collegamenti WAN e migliorare la velocità di risposta delle applicazioni di rete quando gli utenti accedono al contenuto di un ufficio centrale dalle succursali. Quando si abilita BranchCache, una copia del contenuto recuperato dal server Web o dal file server viene memorizzata nella cache nella succursale. Se un altro client nella succursale richiede lo stesso contenuto, il client può scaricarlo direttamente dalla rete della succursale locale anziché dover usare di nuovo la WAN per recuperare il contenuto dalla sede centrale.
cluster di failover
I cluster di failover supportano completamente la deduplicazione dati, quindi i volumi deduplicati eseguono il failover normalmente tra i nodi del cluster. Ciò richiede tuttavia, l'installazione della funzionalità Deduplicazione dati in ogni nodo del cluster che partecipa a un failover.
Quote di Gestione risorse file server
Sebbene non sia necessario creare una quota rigida su una cartella radice del volume abilitata per la deduplicazione, è possibile usare Gestione risorse file server per creare una quota flessibile in tale scenario. Quando Gestione risorse file server rileva un file deduplicato, identifica le dimensioni logiche del file per i calcoli delle quote. L'utilizzo della quota, incluse eventuali soglie di quota, non cambia quindi quando la deduplicazione elabora un file. Tutte le altre funzionalità delle quote di Gestione risorse file server, incluse le quote flessibili della radice del volume e le quote nelle sottocartelle, funzioneranno come previsto durante l'uso della deduplicazione.
Nota
Gestione risorse file server è una suite di strumenti che consentono di identificare, controllare e gestire il tipo e la quantità dei dati archiviati nei server. Gestione risorse file server consente di configurare quote rigide o flessibili in cartelle e volumi. Una quota rigida impedisce agli utenti di salvare i file dopo che è stato raggiunto il limite di quota, mentre una quota flessibile non impone il limite di quota e genera una notifica quando i dati nel volume raggiungono una soglia.
Replica DFS
La funzionalità Deduplicazione dati è compatibile con Replica DFS (Distributed File System, file system distribuito). L'ottimizzazione o l'annullamento dell'ottimizzazione di un file non attiverà una replica perché il file non viene modificato. Per i salvataggi attraverso la rete, Replica DFS usa RDC (Remote Differential Compression), non i blocchi nell'archivio blocchi.