Implementare i cluster estesi
Tradizionalmente, i cluster di failover assicurano la disponibilità elevata in caso di errori localizzati per uno o più nodi del cluster che risiedono nella stessa posizione fisica. È possibile usare i cluster estesi quando è necessario fornire una funzionalità equivalente per più posizioni fisiche.
Che cosa sono i cluster estesi?
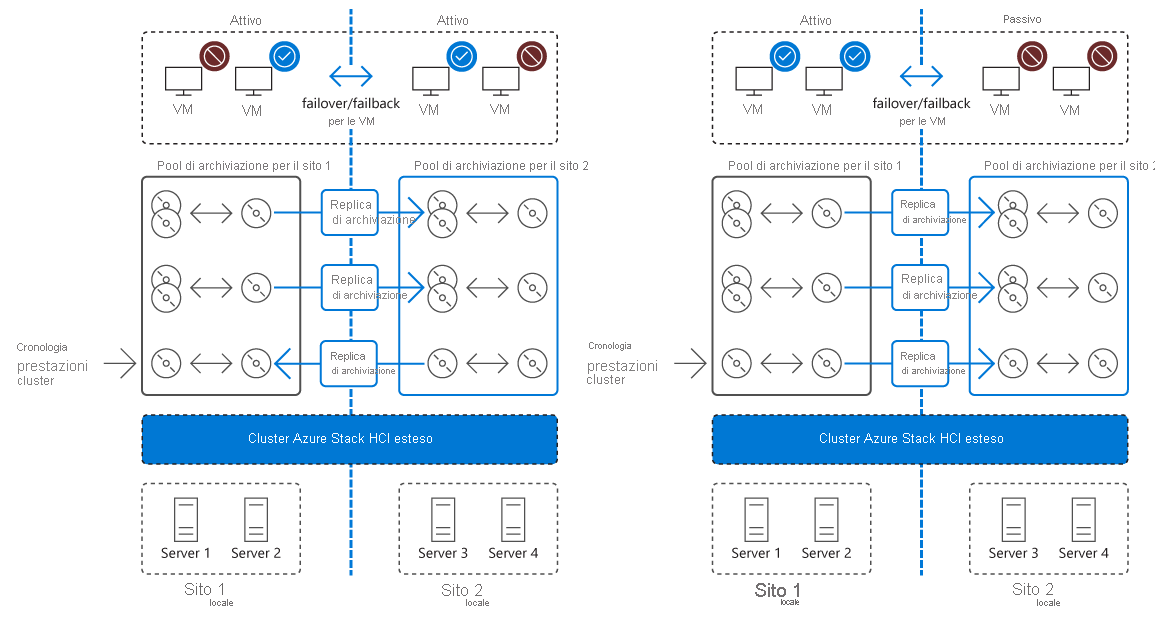
Un cluster esteso implementa la disponibilità elevata e il ripristino di emergenza in due posizioni fisiche distinte. In entrambe le posizioni è presente un sistema di archiviazione separato, con replica unidirezionale sincrona dal sito primario a quello secondario. Se si verifica un errore che ha impatto sulla disponibilità del sito primario, per ridurre al minimo i tempi di inattività, il cluster esegue automaticamente la transizione dei carichi di lavoro ai nodi nel sito secondario. Per gli eventi di manutenzione pianificata nel sito primario, è possibile usare Hyper-V Live Migration che consente di eseguire facilmente la transizione dei carichi di lavoro all'altro sito, evitando anche i tempi di inattività.
L'uso di cluster estesi offre diversi vantaggi rispetto alla gestione manuale di un sito di ripristino di emergenza:
- Replica e failover automatici dei carichi di lavoro del cluster.
- Riduzione del sovraccarico amministrativo.
- Riduzione del rischio di errore umano inerente ai processi manuali.
D'altro canto, i cluster estesi presentano maggiori difficoltà di progettazione e implementazione. In genere richiedono anche un investimento aggiuntivo nell'infrastruttura di archiviazione e di rete.
Panoramica di Replica archiviazione
I cluster estesi sfruttano Replica archiviazione, una funzionalità di Windows Server che consente la replica dei volumi tra server o cluster per il ripristino di emergenza. Usando Replica archiviazione, i cluster estesi possono sincronizzare i volumi di archiviazione collegati ai nodi del cluster estesi in due posizioni distinte.
La Storage Replica supporta la replica sincrona e asincrona.
- Con la replica sincrona, i dati vengono replicati su una rete a bassa latenza, con un tempo di round trip dell'ordine di millisecondi, assicurando che non si verifichi alcuna perdita di dati a livello di file system durante un failover.
- Con la replica asincrona, i dati vengono replicati su distanze più lunghe soggette a latenze più elevate, ma senza garantire che entrambi i siti abbiano copie identiche dei dati al momento di un failover.
Importante
I cluster estesi richiedono la replica sincrona. Questo requisito impone il limite di 5 ms di latenza di round trip tra due gruppi di nodi del cluster nei siti replicati. A seconda delle caratteristiche di connettività della rete fisica, questo vincolo si traduce in genere in una distanza di circa 20-30 miglia.
Funzionalità di Replica archiviazione
Nella tabella seguente sono elencate le funzionalità principali di Replica archiviazione.
| Caratteristica / Funzionalità | Descrizione |
|---|---|
| Replica a livello di blocco | La replica a livello di blocco non consente di bloccare i file. |
| Semplicità | È possibile basarsi su Windows Admin Center per ottenere indicazioni sul processo di creazione di una relazione di replica tra due server. Per distribuire un cluster esteso, è possibile usare una procedura guidata basata su Gestione cluster di failover. |
| Uso di SMB (Server Message Block) 3.0 | Replica archiviazione si basa su SMB 3.x, introdotto in Windows Server 2012 e notevolmente migliorato nelle versioni successive di Windows Server. Tutte le caratteristiche avanzate di SMB, ad esempio SMB multicanale e SMB diretto, sono disponibili per Replica archiviazione. |
| Sicurezza | Replica archiviazione offre un'ampia gamma di meccanismi di sicurezza, tra cui la firma di pacchetti, la crittografia completa dei dati AES-128-GCM, il supporto per l'accelerazione della crittografia di terze parti e la prevenzione degli attacchi man-in-the-middle all'integrità prima dell'autenticazione. Replica archiviazione si basa inoltre su Kerberos AES256 per tutte le autenticazioni tra i nodi. |
| Vincoli di rete | Nei casi in cui sono presenti più percorsi di rete tra i volumi replicati, è possibile configurare il traffico di Replica archiviazione per l'uso di schede di rete designate. Ciò consente di ridurre al minimo il potenziale impatto del traffico di replica sui carichi di lavoro di produzione. |
| Thin provisioning | È possibile implementare il thin provisioning in Spazi di archiviazione diretta, riducendo al minimo i tempi di replica iniziali. |
Prerequisiti per la distribuzione di cluster estesi
Per l'implementazione di cluster estesi sono previsti i prerequisiti seguenti:
I nodi del cluster devono essere membri della stessa foresta Active Directory Domain Services o di una foresta attendibile dello stesso tipo.
Ogni nodo del cluster deve avere almeno 2 GB di RAM e due core CPU per server.
Ogni nodo del cluster deve eseguire Windows Server 2025 Datacenter o Windows Server 2016 Datacenter Edition. È possibile usare Windows Server 2025 Standard Edition, ma questa configurazione supporta la replica di un singolo volume con dimensioni fino a 2 terabyte (TB).
Ogni nodo del cluster deve avere almeno una scheda Ethernet Gigabit per la replica sincrona, anche se è preferibile RDMA (Remote Direct Memory Access).
Devono essere presenti due set di volumi (uno per i dati e l'altro per i log) nel sito primario e in quello secondario, con le impostazioni seguenti:
I dischi devono essere inizializzati come tabella delle partizioni GUID (GPT), anziché come record di avvio principale (MBR).
- I volumi devono essere formattati con ReFS o NTFS.
- Le dimensioni dei volumi di dati devono corrispondere alle dimensioni dei settori.
- Le dimensioni dei volumi di log devono corrispondere alle dimensioni dei settori.
- I volumi di log devono usare risorse di archiviazione più veloci rispetto ai volumi di dati.
- I volumi di log non devono essere usati per altri carichi di lavoro.
Tra i due siti deve essere supportata la connettività bidirezionale tramite ICMP (Internet Control Message Protocol), SMB (porta 445, più la porta 5445 per SMB diretto) e WS-MAN (Web Services-Management) (porta 5985).
I server devono essere collegati tramite una rete con larghezza di banda sufficiente per la corrispondenza delle scritture di I/O dei carichi di lavoro del cluster e una latenza di round trip inferiore a 5 ms.
Considerazioni relative alla distribuzione di un cluster esteso
I cluster estesi non sono adatti a qualsiasi tipo di carico di lavoro e scenario. Quando si progetta una soluzione di clustering esteso, identificare chiaramente i requisiti e le aspettative della propria organizzazione. Tenere inoltre presente che i cluster estesi impongono un sovraccarico di gestione maggiore rispetto ai cluster tradizionali, in cui tutti i nodi si trovano nella stessa posizione fisica. È inoltre consigliabile valutare attentamente la scelta del server di controllo del quorum per massimizzare la disponibilità se si verifica una situazione di emergenza che interessa un intero sito fisico.
Importante
Le applicazioni e i servizi con stato, come Microsoft SQL Server, Hyper-V, Microsoft Exchange Server e Active Directory Domain Services, devono usare i propri meccanismi di resilienza nativi anziché basarsi sui cluster estesi per la disponibilità elevata.
Considerazioni relative al failover e al failback in un cluster esteso
Come parte della pianificazione per la distribuzione di un cluster esteso, è necessario definire la configurazione di failover e failback tenendo conto delle considerazioni seguenti:
- Dipendenze dell'infrastruttura. È necessario definire chiaramente i servizi critici, ad esempio Active Directory Domain Services, DNS e DHCP, che devono rimanere disponibili in seguito a un failover nel sito secondario.
- Modello di quorum. È importante scegliere il modello di quorum che consente di mantenere le funzionalità del cluster in seguito a un failover.
- Pubblicazione dei servizi e risoluzione dei nomi. Se si hanno servizi pubblicati per utenti interni o esterni, ad esempio la posta elettronica e le pagine Web, tenere presente che in alcuni casi il failover in un altro sito richiede una modifica del nome o dell'indirizzo IP. In tal caso, è necessario predisporre una procedura per modificare i record DNS nel DNS interno o pubblico. Per limitare i tempi di inattività, è consigliabile ridurre il valore TTL (Time to Live) dei record DNS critici.
- Connettività client. In caso di emergenza, un piano di failover deve supportare la connettività dalle applicazioni client ai carichi di lavoro del cluster. Questo requisito interessa i client interni ed esterni.
- Procedura di failback. È necessario pianificare e implementare un processo di failback da eseguire dopo che il sito primario sarà tornato online. Il failback è importante quanto il failover poiché, se non viene eseguito nel modo corretto, possono verificarsi perdite di dati e tempi di inattività del servizio.
Creare un cluster esteso
Per creare un cluster esteso è possibile usare Windows Admin Center, Gestione cluster di failover o Windows PowerShell. Windows Admin Center semplifica l'implementazione dei cluster estesi guidando l'utente attraverso il processo di provisioning e automatizzando la maggior parte delle attività di configurazione. Ciò include il supporto per:
- Cluster iperconvergenti (Clustering di failover, Hyper-V e Spazi di archiviazione diretta).
- Cluster di archiviazione (Clustering di failover e Spazi di archiviazione diretta).
Annotazioni
La creazione di un cluster esteso tramite Gestione cluster di failover o Windows PowerShell è più complessa. Entrambi i metodi richiedono l'esecuzione di tutti i passaggi di implementazione intermedi. In termini più semplici, questo processo inizia con la creazione di un cluster di failover tradizionale non esteso, costituito da tutti i nodi nel sito primario e in quello secondario. Una volta creato il cluster e completata la convalida, in ogni sito viene creato un set separato di volumi di archiviazione. Infine viene eseguita la configurazione di Replica archiviazione in modo da replicare i volumi di archiviazione tra i due siti.