Che cos'è la scalabilità?
- 6 minuti
Nel mondo del business, la crescita può essere vantaggiosa. Tuttavia, quando la crescita si verifica troppo rapidamente e quando non si è adeguatamente preparati per esso, la crescita può creare problemi. Uno di questi problemi è l'effetto della crescita sull'affidabilità delle applicazioni e dei servizi che non sono stati progettati per gestire un elevato aumento del traffico.
Per i clienti e gli utenti, un'interruzione del servizio è un'interruzione. Non sanno né si preoccupano se non sono in grado di accedere al sito a causa di codice buggy o perché troppe altre persone stanno cercando di usare il sito perfettamente codificato contemporaneamente.
La scalabilità è la possibilità di adattarsi a esigenze più elevate o a esigenze mutevoli. Le applicazioni e i servizi devono essere in grado di gestire una quantità maggiore di carico di lavoro per supportare la crescita. Le applicazioni scalabili sono in grado di gestire un numero di richieste in espansione nel tempo senza alcun effetto negativo sulla disponibilità o sulle prestazioni.
In questa unità si apprenderà la relazione tra scalabilità e affidabilità, l'importanza della pianificazione della capacità per ottenere la scalabilità e brevemente esaminare alcuni concetti e termini di base correlati al ridimensionamento.
Relazione di scalabilità/affidabilità
La buona notizia è che rendere l'app più scalabile può anche renderla più affidabile. Ad esempio, se il sistema esegue la scalabilità automatica, in seguito a un errore del componente in una singola macchina virtuale, il servizio di scalabilità automatica fornisce un'altra istanza per soddisfare i requisiti minimi del numero di macchine virtuali. Il sistema diventa più affidabile. In un altro esempio si usa un servizio di livello superiore, ad esempio Archiviazione di Azure intrinsecamente scalabile. Se si verifica un problema di archiviazione, il servizio è progettato per essere affidabile, in modo che i dati vengano replicati.
Ecco un'analogia: si pensi alle rampe di accessibilità che spesso si vedono all'esterno di edifici progettati inizialmente per ospitare persone in sedia a rotelle. Servono a questo scopo. Ma, sono utilizzati anche dai genitori con bambini in passeggino o carrozze, o da bambini piccoli per i quali i gradini della scala sono troppo profondi o alti. Questo utilizzo è un vantaggio secondario.
L'affidabilità è spesso un vantaggio secondario della scalabilità. Se si progettano i sistemi in modo che siano scalabili, è probabile che siano più affidabili.
Pianificazione della scalabilità e della capacità
La pianificazione della capacità comporta la determinazione delle risorse necessarie per soddisfare le esigenze attuali e future. Questa pianificazione viene eseguita analizzando l'utilizzo corrente delle risorse e quindi proiettando la crescita futura.
Per stimare le esigenze di capacità in futuro, è necessario considerare questi fattori:
- Crescita aziendale prevista
- Fluttuazioni periodiche (stagionale e così via)
- Vincoli dell'applicazione
- Identificazione di colli di bottiglia e fattori limitanti
È anche necessario impostare gli obiettivi del livello di servizio in modo da poter creare un piano di gestione della capacità che soddisfi o superi in modo affidabile tali obiettivi man mano che cambia il carico di lavoro e l'ambiente.
La pianificazione della capacità è un processo iterativo. Questo modulo illustra come eseguire il mapping dei requisiti delle risorse per i componenti dell'applicazione.
Concetti e terminologia
Prima di comprendere appieno i concetti e le strategie riscontrati in questo modulo, sono necessarie alcune conoscenze preliminari di alcuni concetti di base e termini fondamentali correlati alla scalabilità.
- Aumento delle prestazioni: aumentare le dimensioni di un componente in modo da gestire un carico di lavoro maggiore. Detto anche ridimensionamento verticale.
- Scalabilità orizzontale: aggiunta di più componenti o risorse per distribuire il carico su un'architettura distribuita. Ad esempio, usando un'architettura semplice che ha più back-end dietro un insieme di front-end. Con l'aumentare del carico, vengono aggiunti altri server back-end (e front-end) per gestirlo. Detto anche ridimensionamento orizzontale.
- Ridimensionamento manuale: l'azione umana è necessaria per aumentare la quantità di risorse.
- Scalabilità automatica: il sistema regola automaticamente la quantità di risorse in base al carico. Per essere chiari, l'importo viene regolato sia verso l'alto che verso il basso in base a un carico aumentato o diminuito.
- Scalabilità DIY: Configurazione fai-da-te della scalabilità, per cui è necessario impostare l'autoscaling.
- Scalabilità intrinseca: i servizi creati per essere scalabili e gestire questa scalabilità in background senza alcun intervento da parte dell'utente. Dal punto di vista dell'utente, sembrano quasi infinitamente scalabili perché è possibile usare solo più risorse senza dover eseguirne manualmente il provisioning.
Architettura di Tailwind Traders
In questo modulo si userà un'architettura di esempio di una società di hardware fittizia denominata Tailwind Traders. La piattaforma di e-commerce è simile alla seguente:
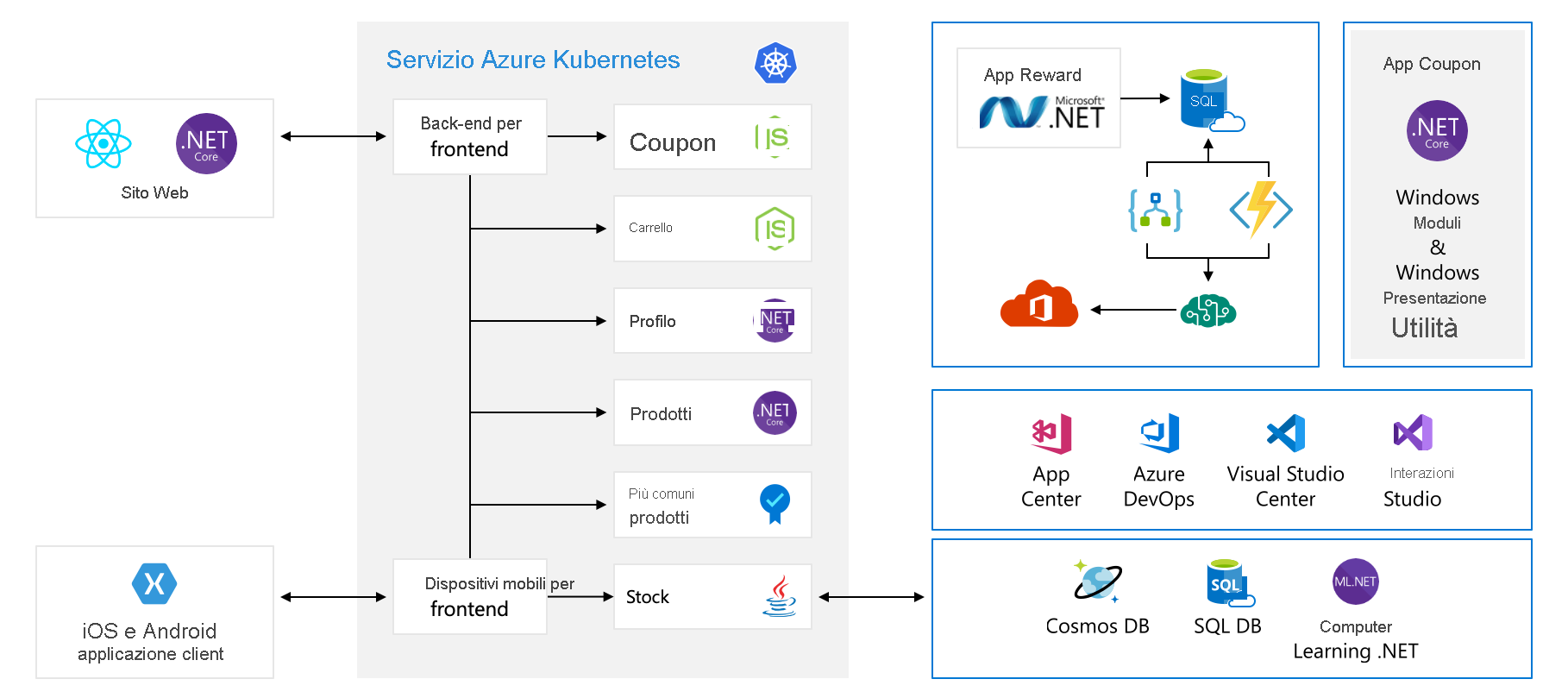
Questo diagramma è piuttosto complesso a prima vista, quindi esaminiamolo. Il sito Web ha un front-end. Si tratta del servizio con cui si parla quando si accede al sito tailwindtraders.com.
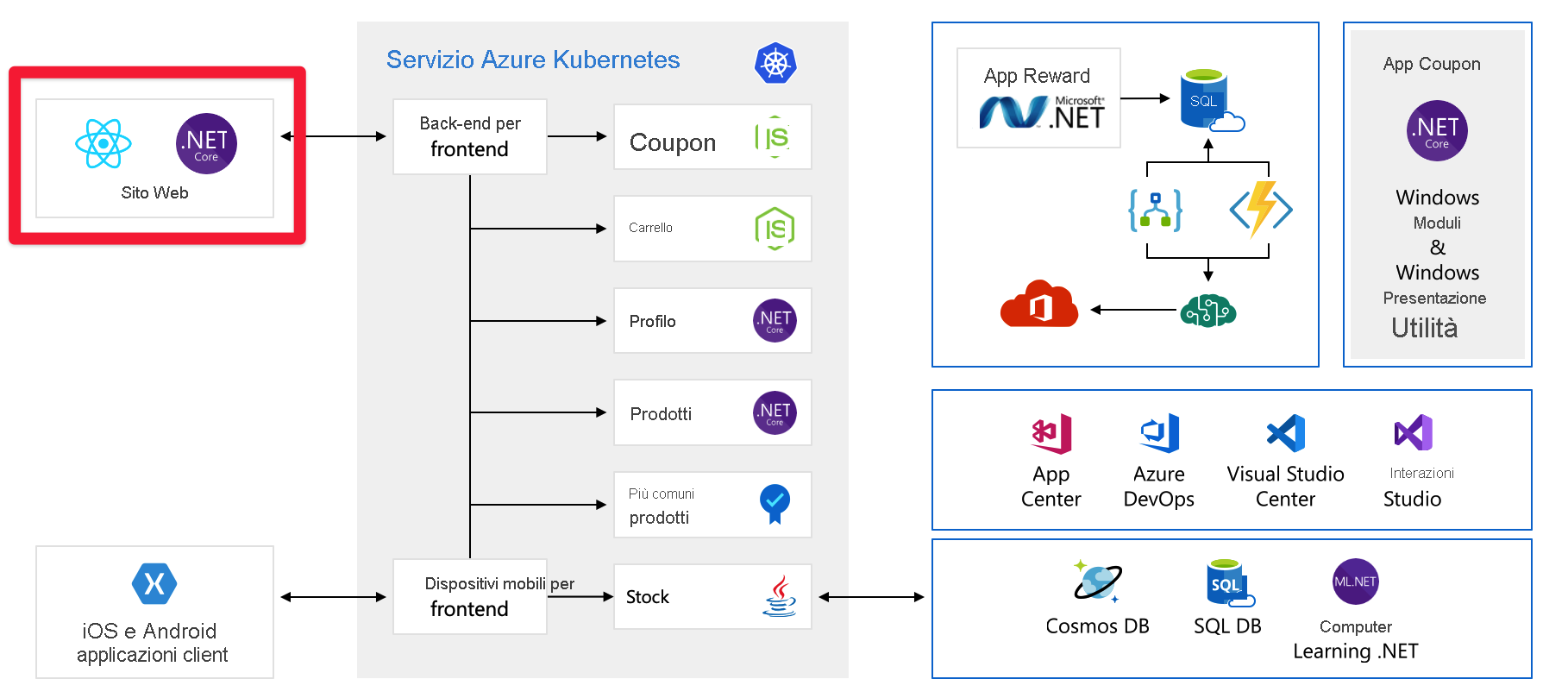
Il front-end comunica con un set di servizi back-end. Questi servizi back-end includono gli elementi comuni, ad esempio un servizio coupon, un servizio carrello acquisti, un servizio di inventario e così via. Sono tutti in esecuzione in servizio Azure Kubernetes. Ci sono altre parti e tecnologie in gioco con questa applicazione. È sufficiente concentrarsi sul front-end e sui servizi back-end in esecuzione in Kubernetes.
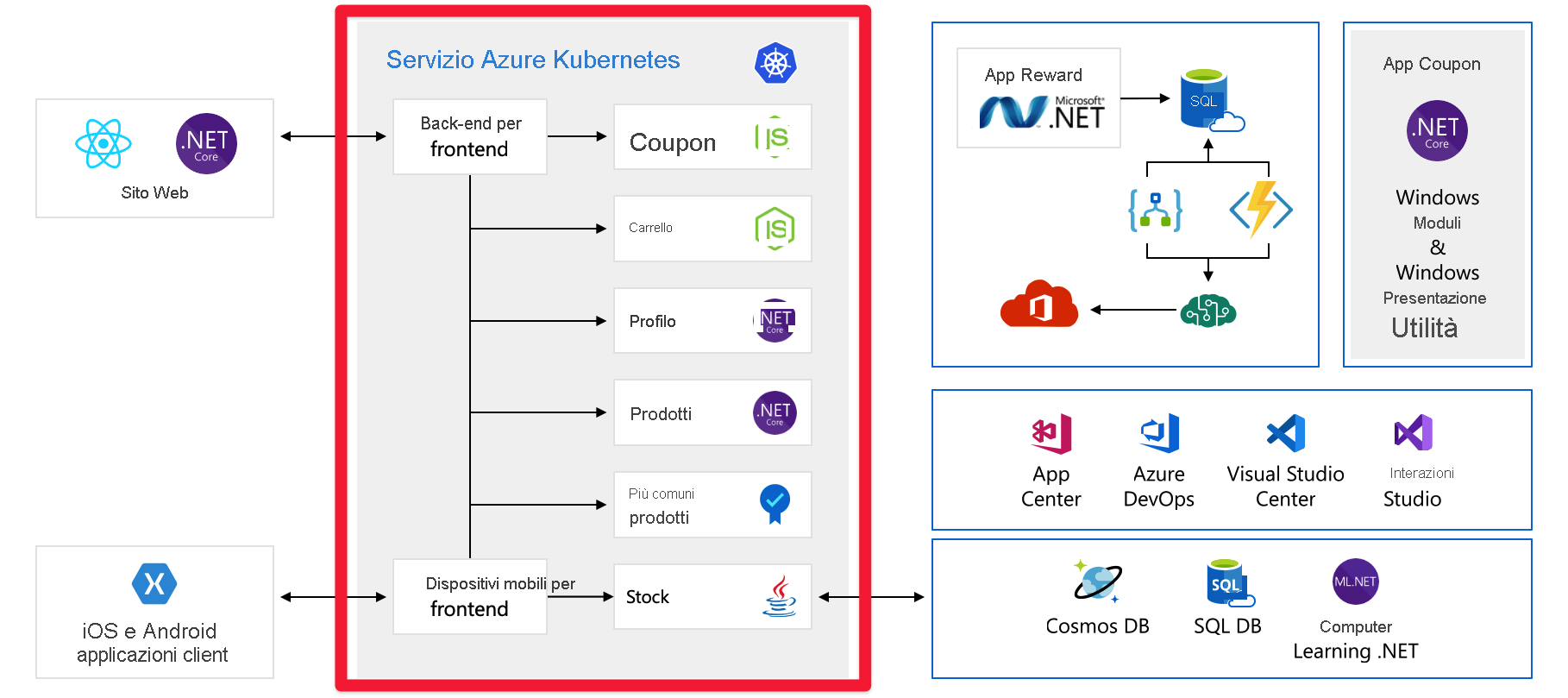
Singoli punti di guasto
Dopo aver visto l'intera architettura, è possibile esaminare i singoli punti di guasto e i punti in cui è possibile prestare attenzione quando si pensa alla scalabilità.
Ognuno di questi servizi è un singolo punto di errore, non è progettato per la resilienza o per la scalabilità. Se uno di essi viene sovraccaricato, è probabile che si blocchi, e non c'è un modo semplice per risolverlo nel momento in cui si verifica.
Più avanti in questo modulo verranno esaminati altri modi per progettare questi servizi in modo che siano più scalabili e affidabili.
Pre-provisioning della capacità
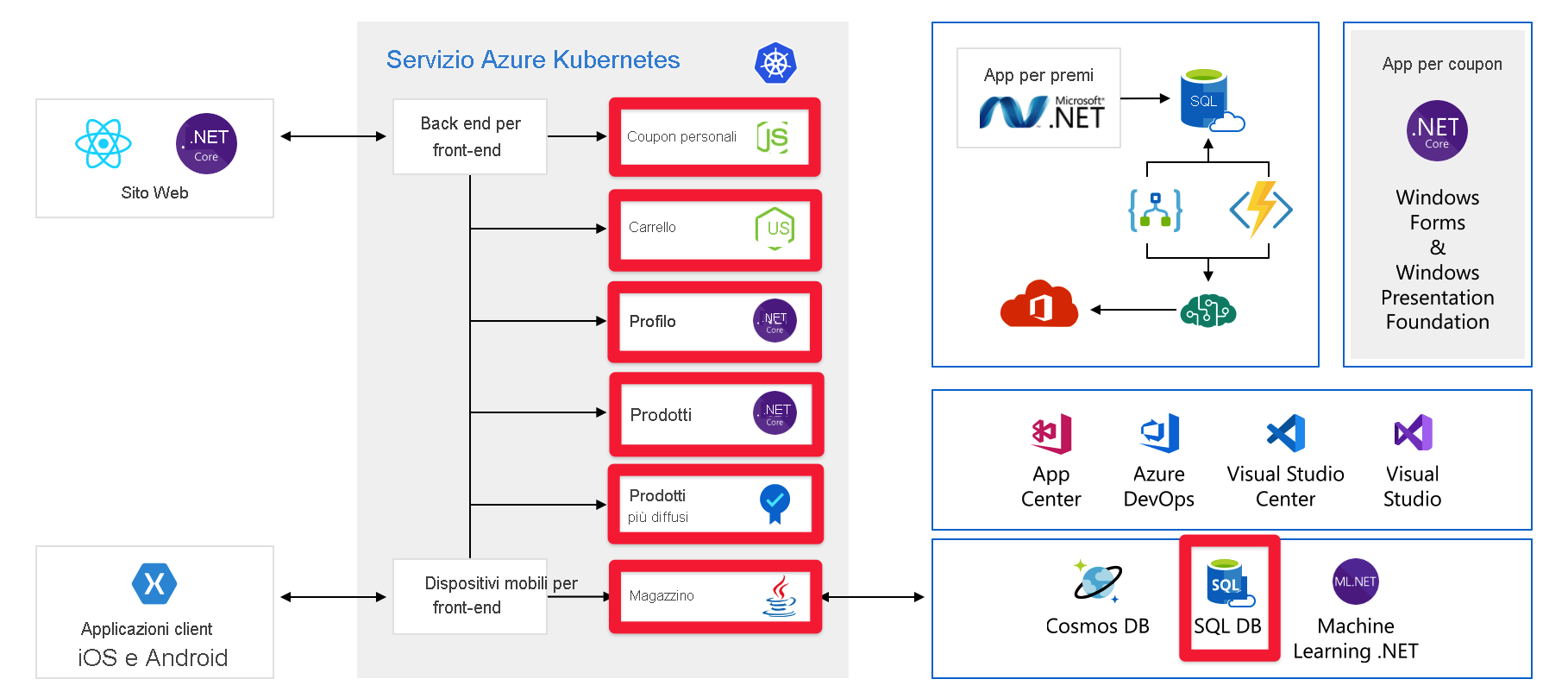
Esaminiamo un altro problema che potrebbe rivelarsi problematico. Ecco i servizi/componenti per i quali è necessario effettuare il pre-provisioning della capacità:
Diagramma completo dell'architettura dell'applicazione con i servizi Azure AI, Cosmos DB e SQL DB evidenziati.
Ad esempio, con Cosmos DB, preconfiguriamo il throughput. Se si superano questi limiti, si inizierà a restituire messaggi di errore ai clienti. Con Servizi di Azure AI, si seleziona il livello e il livello ha un numero massimo di richieste al secondo. Dopo aver raggiunto uno di questi limiti, i client verranno rallentati.
Un picco significativo del traffico, ad esempio l'avvio di un nuovo prodotto, ci farà raggiungere questi limiti? Al momento, non lo sappiamo. Questa questione è un'altra che verrà esaminata più avanti in questo modulo.
Costi
Anche quando facciamo le cose giuste, dobbiamo ancora pianificare la crescita. Ecco i servizi con pagamento in base all'uso:
diagramma completo dell'architettura dell'applicazione con App per la logica di Azure e Funzioni di Azure evidenziati.
In questo caso si usano App per la logica di Azure e Funzioni di Azure, che sono entrambi esempi di tecnologia serverless. Questi servizi vengono ridimensionati automaticamente e si paga per richiesta. La fattura aumenta man mano che la base clienti cresce. Dovremmo almeno essere consapevoli dell'impatto degli eventi imminenti, ad esempio un lancio di prodotto, sulla spesa cloud. Si lavora anche per comprendere e prevedere la spesa cloud più avanti in questo modulo.