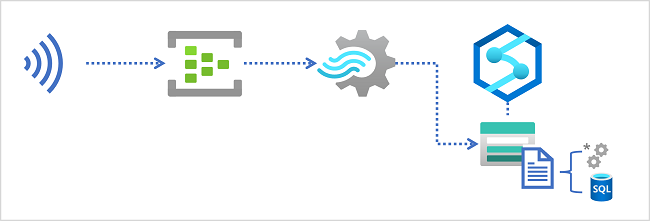
Scenari di inserimento dei flussi
Azure Synapse Analytics offre diversi modi per analizzare grandi volumi di dati. Due degli approcci più comuni all'analisi dei dati su larga scala sono:
- Data warehouse: database relazionali, ottimizzati per l'archiviazione distribuita e l'elaborazione di query. I dati vengono archiviati in tabelle e sottoposti a query tramite SQL.
- Data lake : archiviazione di file distribuita in cui i dati vengono archiviati come file che possono essere elaborati e sottoposti a query usando più runtime, tra cui Apache Spark e SQL.
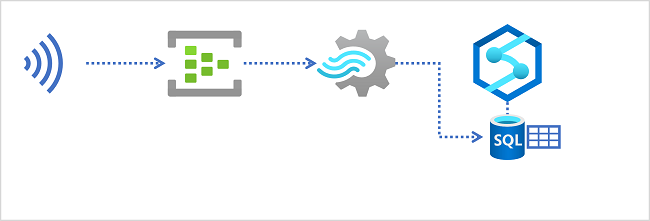
Data warehouse in Azure Synapse Analytics
Azure Synapse Analytics offre pool SQL dedicati che è possibile usare per implementare data warehouse relazionali su scala aziendale. I pool SQL dedicati si basano su un'istanza MPP ( Massively Parallel Processing ) del motore di database relazionale di Microsoft SQL Server in cui i dati vengono archiviati e sottoposti a query nelle tabelle.
Per inserire dati in tempo reale in un data warehouse relazionale, la query di Analisi di flusso di Azure deve scrivere i risultati in un output che fa riferimento alla tabella in cui si vogliono caricare i dati.
Data lake in Azure Synapse Analytics
Un'area di lavoro di Azure Synapse Analytics include in genere almeno un servizio di archiviazione usato come data lake. In genere, il data lake è ospitato in un account di archiviazione di Azure usando un contenitore configurato per supportare Azure Data Lake Storage Gen2. I file nel data lake sono organizzati gerarchicamente in directory (cartelle) e possono essere archiviati in più formati di file, tra cui testo delimitato (ad esempio valori delimitati da virgole o CSV), Parquet e JSON.
Quando si inseriscono dati in tempo reale in un data lake, la query di Analisi di flusso di Azure deve scrivere i risultati in un output che fa riferimento al percorso nel contenitore di archiviazione di Azure Data Lake Gen2 in cui salvare i file di dati. Gli analisti dei dati, i tecnici e gli scienziati possono quindi elaborare ed eseguire query sui file nel data lake eseguendo il codice in un pool di Apache Spark o eseguendo query SQL tramite un pool SQL serverless.