Acquisire modelli con reti neurali ricorrenti
Nell'unità precedente sono state illustrate rappresentazioni semantiche avanzate del testo. L'architettura usata acquisisce il significato aggregato delle parole in una frase, ma non tiene conto dell'ordine delle parole, perché l'operazione di aggregazione che segue gli incorporamenti rimuove queste informazioni dal testo originale. Poiché questi modelli non sono in grado di rappresentare l'ordinamento delle parole, non possono risolvere attività più complesse o ambigue, ad esempio la generazione di testo o la risposta alle domande.
Per acquisire il significato di una sequenza di testo, si usa un'architettura di rete neurale denominata rete neurale ricorrente o RNN. Quando si usa un RNN, si passa la frase attraverso la rete un token alla volta e la rete produce uno stato, che viene quindi passato di nuovo alla rete con il token successivo.
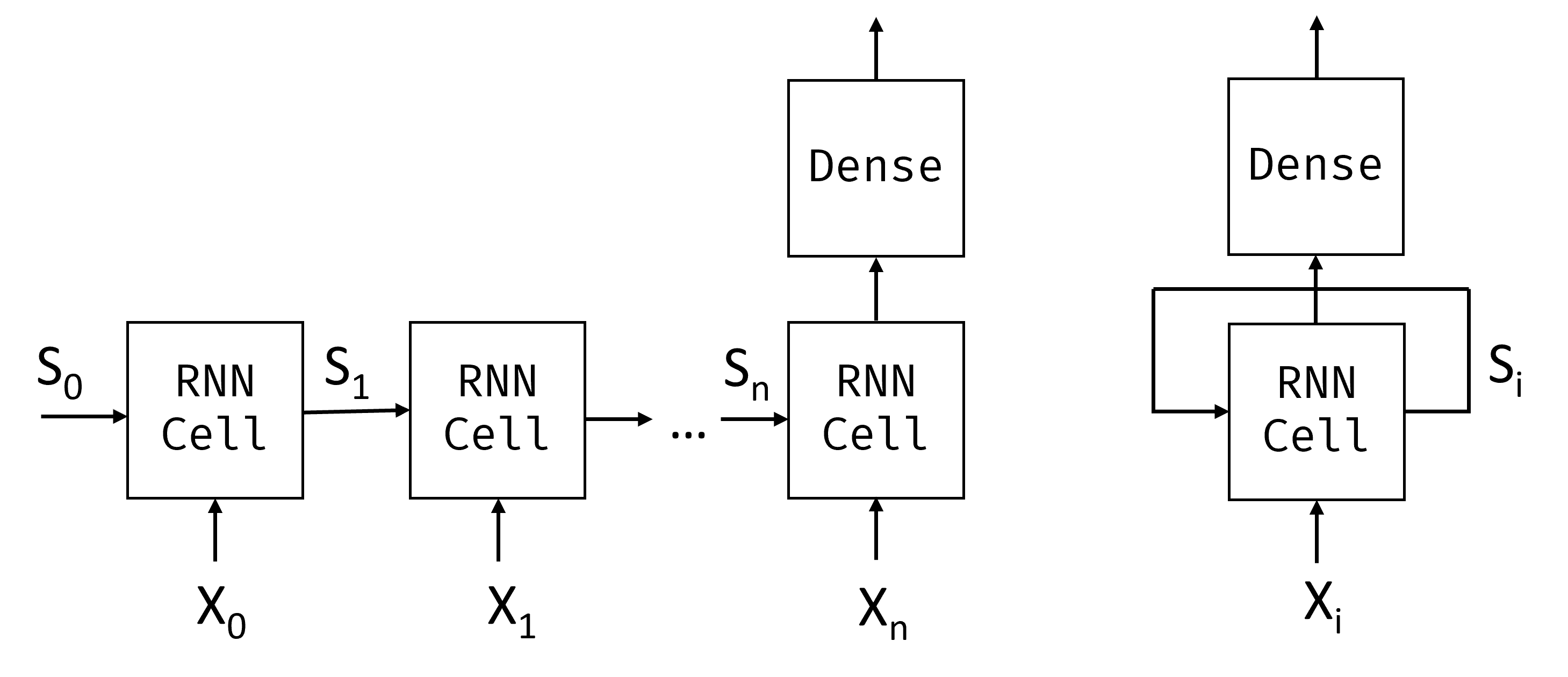
Data la sequenza di input dei token $X_0,\dots,X_n$, l'RNN crea una sequenza di blocchi di rete neurale e allena questa sequenza end-to-end usando la retropropagazione. Ogni blocco di rete accetta una coppia $(X_i,S_i)$ come input e produce $S_{i+1}$ di conseguenza. Lo stato finale $S_n$ o output $Y_n$ viene inserito in un classificatore lineare per produrre il risultato. Tutti i blocchi di rete condividono gli stessi pesi e vengono addestrati da capo a fine usando un solo passaggio di backpropagation.
Poiché i vettori di stato $S_0,\dots,S_n$ vengono passati attraverso la rete, la rete RNN è in grado di apprendere le dipendenze sequenziali tra le parole. Ad esempio, quando la parola non viene visualizzata da qualche parte nella sequenza, può imparare a negare determinati elementi all'interno del vettore di stato.
All'interno, ogni cella RNN contiene due matrici di peso: $W_H$ e $W_I$, e distorsione $b$. In ogni passaggio RNN, dato l'input $X_i$ e lo stato di input $S_i$, lo stato di output viene calcolato come $S_{i+1} = f(W_H\times S_i + W_I\times X_i+b)$, dove $f$ è una funzione di attivazione (spesso $\tanh$).
Annotazioni
Con problemi come la generazione di testo o la traduzione automatica, si vuole ottenere anche un valore di output in ogni passaggio RNN. In questo caso, è presente anche un'altra matrice $W_O$e l'output viene calcolato come $Y_i=f(W_O\times S_{i+1}+b_O)$, dove $S_{i+1}$ è lo stato aggiornato dal passaggio corrente.
Vediamo come le reti neurali ricorrenti possono essere utili per classificare il set di dati delle notizie con il codice seguente:
import tensorflow as tf
import keras
import tensorflow_datasets as tfds
import numpy as np
# We are going to be training pretty large models. In order not to face errors, we need
# to set tensorflow option to grow GPU memory allocation when required
physical_devices = tf.config.list_physical_devices('GPU')
if len(physical_devices)>0:
tf.config.set_memory_growth(physical_devices[0], True)
dataset = tfds.load('ag_news_subset')
ds_train = dataset['train']
ds_test = dataset['test']
Quando si esegue il training di modelli di grandi dimensioni, l'allocazione di memoria GPU può diventare un problema. Potrebbe anche essere necessario sperimentare con dimensioni di minibatch diverse, affinché i dati si adattino alla memoria GPU, ma l'addestramento sia abbastanza veloce. Se si esegue questo codice nel proprio computer GPU, è possibile provare a regolare le dimensioni del minibatch per velocizzare il training.
Annotazioni
Alcune versioni dei driver nVidia sono note perché non rilasciano la memoria dopo il training del modello. In questa unità vengono eseguiti diversi esempi e la memoria potrebbe essere esaurita in determinate configurazioni, soprattutto se si eseguono esperimenti personalizzati. Se si verificano alcuni errori insoliti durante l'avvio del training del modello, è consigliabile riavviare l'ambiente Python.
batch_size = 16
embed_size = 64
Classificatore RNN semplice
Nel caso di un RNN semplice, ogni unità ricorrente è una semplice rete lineare, che accetta un vettore di input e un vettore di stato e produce un nuovo vettore di stato. In Keras, questo può essere rappresentato dallo strato SimpleRNN.
Anche se è possibile passare direttamente i token con codifica one-hot al livello RNN, questa non è una buona idea a causa della loro elevata dimensionalità. Verrà quindi usato un livello di incorporamento per ridurre la dimensionalità dei vettori di parola, seguito da un livello RNN e infine da un Dense classificatore.
Annotazioni
Nei casi in cui la dimensionalità non è così elevata, ad esempio quando si usa la tokenizzazione a livello di carattere, potrebbe essere opportuno passare i token con codifica one-hot direttamente nel modulo RNN.
# We use a smaller vocabulary (20,000) here than in previous units because
# RNN models have more parameters per token, and a smaller vocabulary
# helps keep training time and memory usage manageable.
vocab_size = 20000
vectorizer = keras.layers.TextVectorization(max_tokens=vocab_size)
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, embed_size),
keras.layers.SimpleRNN(16),
keras.layers.Dense(4,activation='softmax')
])
model.summary()
L'esecuzione di questo codice produce l'output seguente:
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ text_vectorization │ (None, None) │ 0 │
│ (TextVectorization) │ │ │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ embedding (Embedding) │ (None, None, 64) │ 1,280,000 │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ simple_rnn (SimpleRNN) │ (None, 16) │ 1,296 │
├──────────────────────────────┼───────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 4) │ 68 │
└──────────────────────────────┴───────────────────────────┴───────────────┘
Total params: 1,281,364 (4.89 MB)
Trainable params: 1,281,364 (4.89 MB)
Non-trainable params: 0 (0.00 B)
Annotazioni
In questo caso viene usato un livello di incorporamento non sottoposto a training per semplicità, ma per ottenere risultati migliori è possibile usare un livello di incorporamento con training preliminare usando Word2Vec, come descritto nell'unità precedente. Sarebbe buona norma adattare questo codice per il funzionamento con incorporamenti con training preliminare.
Ora addestriamo il nostro RNN. Le reti RNN in generale sono difficili da addestrare, perché una volta che le celle della RNN vengono srotolate lungo la lunghezza della sequenza, il numero risultante di livelli coinvolti nella retropropagazione è elevato. È quindi necessario selezionare una frequenza di apprendimento più piccola ed eseguire il training della rete in un set di dati più grande per ottenere buoni risultati. Questo può richiedere molto tempo, quindi è preferibile usare una GPU.
Per velocizzare le operazioni, verrà eseguito il training del modello RNN solo sui titoli delle notizie, omettendo la descrizione. È possibile provare ad addestrare utilizzando una descrizione e verificare se riesci ad addestrare il modello.
def extract_title(x):
return x['title']
def tupelize_title(x):
return (extract_title(x),x['label'])
print('Training vectorizer')
vectorizer.adapt(ds_train.take(2000).map(extract_title))
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize_title).batch(batch_size),validation_data=ds_test.map(tupelize_title).batch(batch_size))
Annotazioni
È probabile che l'accuratezza sia inferiore, perché stiamo eseguendo il training solo sui titoli delle notizie.
Revisione delle sequenze di variabili
Tenere presente che il livello TextVectorization riempirà automaticamente le sequenze di lunghezza variabile in un mini-batch con token di riempimento. Si scopre che anche questi token partecipano al training e possono complicare la convergenza del modello.
Esistono diversi approcci che è possibile adottare per ridurre al minimo la quantità di spaziatura interna. Uno di essi consiste nel riordinare il set di dati in base alla lunghezza della sequenza e raggruppare tutte le sequenze in base alle dimensioni. Questa operazione può essere eseguita usando la funzione (vedere la tf.data.bucket_by_sequence_lengthdocumentazione).
Un altro approccio consiste nell'usare la maschera. In Keras alcuni livelli supportano input aggiuntivi che mostrano quali token devono essere presi in considerazione durante il training. Per incorporare la maschera nel modello, è possibile includere un livello separato Masking (docs) oppure specificare il mask_zero=True parametro del livello Embedding .
Annotazioni
Quando si usa mask_zero=True, l'indice token 0 viene considerato come riempimento e non è una voce di vocabolario valida. Ciò significa che tutti gli indici delle parole del vocabolario vengono spostati di uno. Il TextVectorization layer riserva già l'indice 0 per il riempimento per impostazione predefinita, quindi funziona perfettamente quando i due vengono usati insieme.
def extract_text(x):
return x['title']+' '+x['description']
def tupelize(x):
return (extract_text(x),x['label'])
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size,embed_size,mask_zero=True),
keras.layers.SimpleRNN(16),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),validation_data=ds_test.map(tupelize).batch(batch_size))
Ora che si usa la maschera, è possibile eseguire il training del modello sull'intero set di dati di titoli e descrizioni.
LSTM: Long Short-Term Memory
Uno dei problemi principali delle reti neurali a RNN è la fuga dei gradienti. Le reti RNN possono essere lunghe e possono avere difficoltà a propagare i gradienti fino al primo strato della rete durante la retropropagazione. In questo caso, la rete non può apprendere le relazioni tra token distanti. Un modo per evitare questo problema consiste nell'introdurre una gestione esplicita dello stato usando le porte. Le due architetture più comuni che introducono porte sono la memoria a lungo termine (LSTM) e l'unità ricorrente con porte (GRU). Qui trattiamo gli LSTM.

Una rete LSTM è organizzata in modo simile a una rete RNN, ma esistono due stati passati dal livello al livello: lo stato effettivo $c$e il vettore nascosto $h$. In ogni unità, il vettore nascosto $h_{t-1}$ viene combinato con l'input $x_t$ e insieme controllano cosa accade allo stato $c_t$ e all'output $h_{t}$ attraverso le attività di controllo. Ogni attività di controllo ha attivazione sigmoidale (output nell'intervallo $[0,1]$), che può essere considerato come una maschera bit per bit quando moltiplicato per il vettore di stato. Le LSTM hanno i cancelli seguenti (da sinistra a destra nella foto precedente, seguendo la convenzione del blog di Olah):
- forget gate che determina quali componenti del vettore $c_{t-1}$ dobbiamo dimenticare, e quali passare attraverso.
- attività di controllo dell'input che determina la quantità di informazioni del vettore di input e del vettore nascosto precedente devono essere incorporate nel vettore di stato.
- gate di output che accetta il nuovo vettore di stato e decide quale dei relativi componenti verrà usato per produrre il nuovo vettore nascosto $h_t$.
I componenti dello stato $c$ possono essere considerati come flag che possono essere accesi e disattivati. Ad esempio, quando incontriamo il nome Alice nella sequenza, supponiamo che si riferisca a una donna e alziamo la bandiera nello stato che segnala che abbiamo un sostantivo femminile nella frase. Quando incontriamo ulteriormente le parole e Tom, verrà alzata la bandiera che dice che abbiamo un sostantivo plurale. Di conseguenza, modificando lo stato è possibile tenere traccia delle proprietà grammaticali della frase.
Anche se la struttura interna di una cella LSTM può sembrare complessa, Keras nasconde questa implementazione all'interno del LSTM livello, quindi l'unica operazione da eseguire nell'esempio precedente consiste nel sostituire il livello ricorrente:
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, embed_size),
keras.layers.LSTM(8),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),validation_data=ds_test.map(tupelize).batch(batch_size))
Annotazioni
Anche il training degli LSTM è lento e potrebbe non mostrare un notevole aumento dell'accuratezza all'inizio del training. Potrebbe essere necessario continuare il training per un certo periodo di tempo per ottenere una buona accuratezza.
RNN bidirezionali e multilivello
Negli esempi finora le reti ricorrenti operano dall'inizio di una sequenza fino alla fine. Questo si sente naturale per noi perché segue la stessa direzione in cui leggiamo o ascoltiamo il discorso. Tuttavia, per gli scenari che richiedono l'accesso casuale della sequenza di input, è più opportuno eseguire il calcolo ricorrente in entrambe le direzioni. Le reti RNN che consentono calcoli in entrambe le direzioni sono denominate RNN bidirezionali e possono essere create eseguendo il wrapping del livello ricorrente con un livello speciale Bidirectional .
Annotazioni
Il livello Bidirectional crea due copie di sé stesso e imposta la proprietà go_backwards su una di queste copie a True, facendola procedere nella direzione opposta lungo la sequenza.
Reti ricorrenti, unidirezionali o bidirezionali, catturano schemi all'interno di una sequenza e li archiviano in vettori di stato o li restituiscono come output finale. Come per le reti convoluzionali, è possibile creare un altro livello ricorrente dopo il primo per acquisire modelli di livello superiore, creati da modelli di livello inferiore estratti dal primo livello. Questo ci porta alla nozione di RNN multi-layer, costituita da due o più reti ricorrenti, in cui l'output del livello precedente viene passato al livello successivo come input.
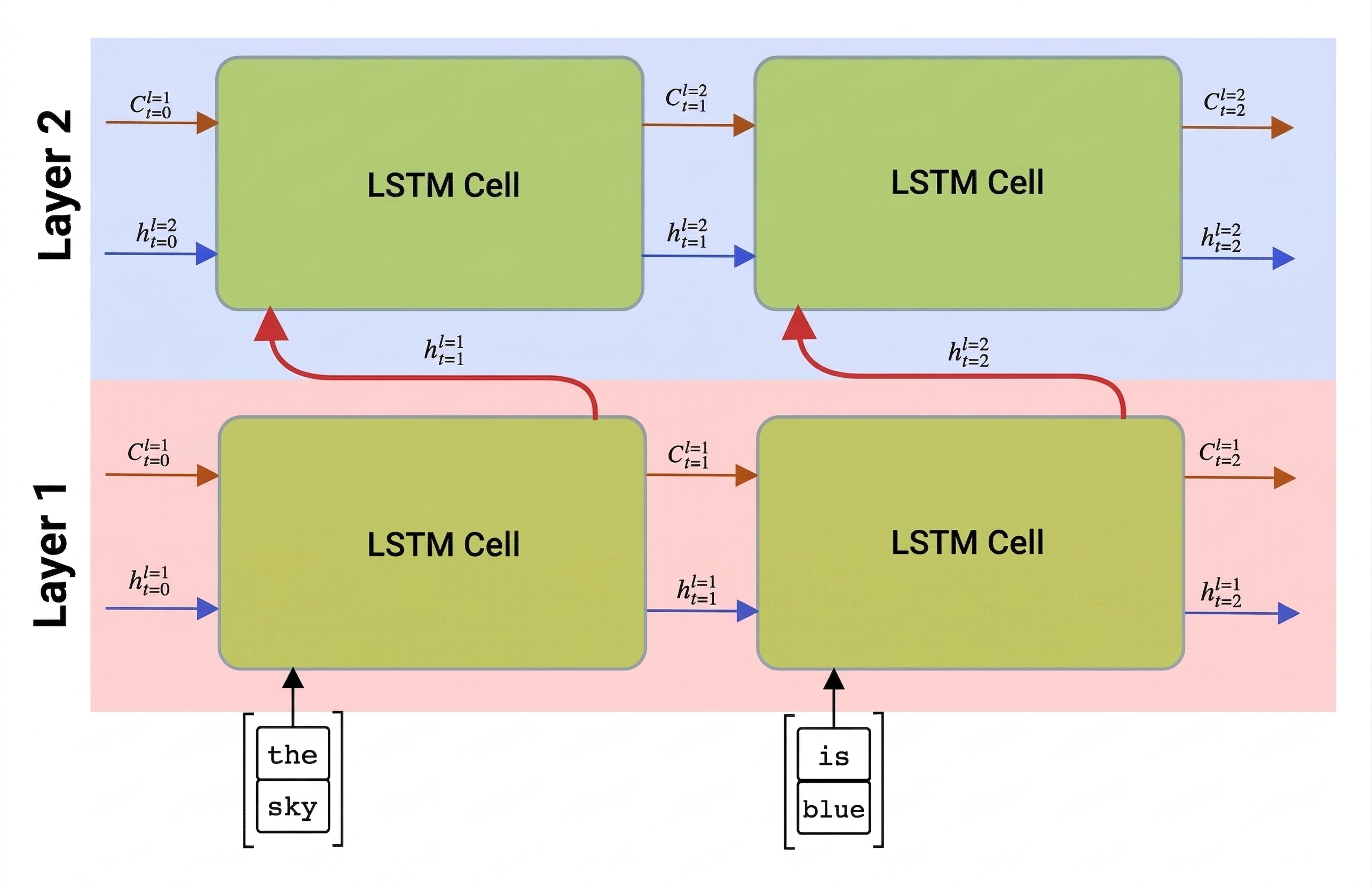
Foto di nel post sugli LSTM multistrato di Fernando López.
Keras rende la costruzione di queste reti un'attività semplice, perché è sufficiente aggiungere più livelli ricorrenti al modello. Per tutti i livelli tranne l'ultimo, è necessario specificare return_sequences=True il parametro, perché è necessario che il livello restituisca tutti gli stati intermedi e non solo lo stato finale del calcolo ricorrente.
Il codice seguente implementa un LSTM bidirezionale a due livelli per il problema di classificazione.
model = keras.Sequential([
keras.Input(shape=(1,), dtype=tf.string),
vectorizer,
keras.layers.Embedding(vocab_size, 128, mask_zero=True),
keras.layers.Bidirectional(keras.layers.LSTM(64,return_sequences=True)),
keras.layers.Bidirectional(keras.layers.LSTM(64)),
keras.layers.Dense(4,activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(batch_size),
validation_data=ds_test.map(tupelize).batch(batch_size))