Funzionamento di Azure Data Factory
Qui vengono fornite informazioni sui componenti e sui sistemi interconnessi di Azure Data Factory e sul loro funzionamento. Queste informazioni devono essere utili per determinare come usare al meglio Azure Data Factory per soddisfare i requisiti dell'organizzazione.
Azure Data Factory è una raccolta di sistemi interconnessi che si combinano per offrire una piattaforma di analisi dei dati end-to-end. In questa unità si apprendono le seguenti funzioni di Azure Data Factory:
- Connettersi e raccogliere
- Trasformare e arricchire
- Integrazione continua e recapito continuo (CI/CD) e pubblicazione
- Monitoraggio
Vengono inoltre illustrati questi componenti chiave di Azure Data Factory:
- Pipelines
- Attività
- Set di dati
- Servizi collegati
- Flussi di dati
- Runtime di integrazione
Funzioni di Azure Data Factory
Azure Data Factory include diverse funzioni che si combinano per mettere a disposizione dei data engineer una piattaforma di analisi dei dati completa.
Connettersi e raccogliere
La prima parte del processo è raccogliere i dati necessari dalle origini dati appropriate, Queste origini possono trovarsi in posizioni diverse, incluse le origini locali e nel cloud. I dati possono essere:
- dati strutturati
- Non strutturato
- dati semistrutturati
Inoltre, questi dati eterogenei potrebbero arrivare a velocità e intervalli diversi. Con Azure Data Factory, è possibile usare l'attività di copia per spostare i dati da diverse origini a un unico archivio dati centralizzato nel cloud. Dopo aver copiato i dati, è possibile usare altri sistemi per trasformarli e analizzarli.
L'attività di copia esegue i seguenti passaggi generali:
Leggere i dati dall'archivio dati di origine.
Eseguire le attività seguenti sui dati:
- Serializzazione/deserializzazione
- Compressione/decompressione
- Mapping delle colonne
Nota
Potrebbero essere previste attività aggiuntive.
Scrivere dati nell'archivio dati di destinazione (noto come sink).
Questo processo è illustrato in sintesi nella figura seguente:

Trasformare e arricchire
Dopo aver copiato correttamente i dati in una posizione centralizzata basata sul cloud, è possibile elaborare e trasformare i dati in base alle esigenze usando i flussi di dati di mapping di Azure Data Factory. I flussi di dati consentono di creare i grafi di trasformazione dei dati eseguiti in Spark. Tuttavia, non è necessario comprendere i cluster Spark o la programmazione Spark.
Suggerimento
Anche se non è necessario, può essere preferibile codificare manualmente le trasformazioni. In questo caso, Azure Data Factory supporta le attività esterne per l'esecuzione delle trasformazioni.
CI/CD e pubblicazione
Il supporto per CI/CD consente di sviluppare e distribuire i processi di estrazione, trasformazione, caricamento (ETL) in modo incrementale prima della pubblicazione. Azure Data Factory offre il processo CI/CD delle pipeline di dati usando:
- Azure DevOps
- GitHub
Nota
Integrazione continua è significa testare automaticamente ogni modifica apportata alla codebase non appena possibile. Subito dopo il test, il recapito continuo esegue il push delle modifiche a un sistema di gestione temporanea o produzione.
Dopo che Azure Data Factory affina i dati non elaborati, è possibile caricare i dati in qualsiasi motore di analisi a cui gli utenti aziendali possano accedere dagli strumenti di business intelligence, tra cui:
- Azure Synapse Analytics
- Database SQL di Azure
- Azure Cosmos DB
Monitoraggio
Dopo aver compilato e distribuito correttamente la pipeline di integrazione dei dati, è importante monitorare le attività e le pipeline pianificate. Il monitoraggio consente di tenere traccia delle percentuali di esito positivo e negativo. Azure Data Factory offre il supporto per il monitoraggio della pipeline usando uno dei metodi seguenti:
- Monitoraggio di Azure
- API
- PowerShell
- Log di Monitoraggio di Azure
- Pannelli di integrità nel portale di Azure
Componenti di Azure Data Factory
Azure Data Factory è costituito dai componenti descritti nella tabella seguente:
| Componente | Descrizione |
|---|---|
| Pipeline | Raggruppamento logico di attività che eseguono un'unità di lavoro specifica. Queste attività insieme svolgono un "task". Il vantaggio dell'uso di una pipeline è che è possibile gestire più facilmente le attività come set anziché come singoli elementi. |
| Attività | Singolo passaggio di elaborazione in una pipeline. Azure Data Factory supporta tre tipi di attività: attività di spostamento dei dati, attività di trasformazione dei dati e attività di controllo. |
| Set di dati | Rappresenta le strutture di dati all'interno degli archivi dati. I set di dati puntano (o fanno riferimento) ai dati che si desidera usare nelle attività come input o output. |
| Servizi collegati | Definire le informazioni di connessione necessarie per Azure Data Factory per connettersi alle risorse esterne, ad esempio un'origine dati. Azure Data Factory usa i servizi collegati per due scopi: per rappresentare un archivio dati o una risorsa di calcolo. |
| Flussi di dati | Consentire ai data engineer di sviluppare la logica di trasformazione dei dati senza dover scrivere codice. I flussi di dati vengono eseguiti come attività all'interno delle pipeline di Azure Data Factory che usano i cluster Apache Spark con scale-out. |
| Runtime di integrazione | Azure Data Factory usa l'infrastruttura di calcolo per offrire le funzionalità di integrazione dei dati seguenti in diversi ambienti di rete: flusso di dati, spostamento dei dati, invio attività ed esecuzione di pacchetti di SQL Server Integration Services (SSIS). In Azure Data Factory un runtime di integrazione funge da bridge tra l'attività e i servizi collegati. |
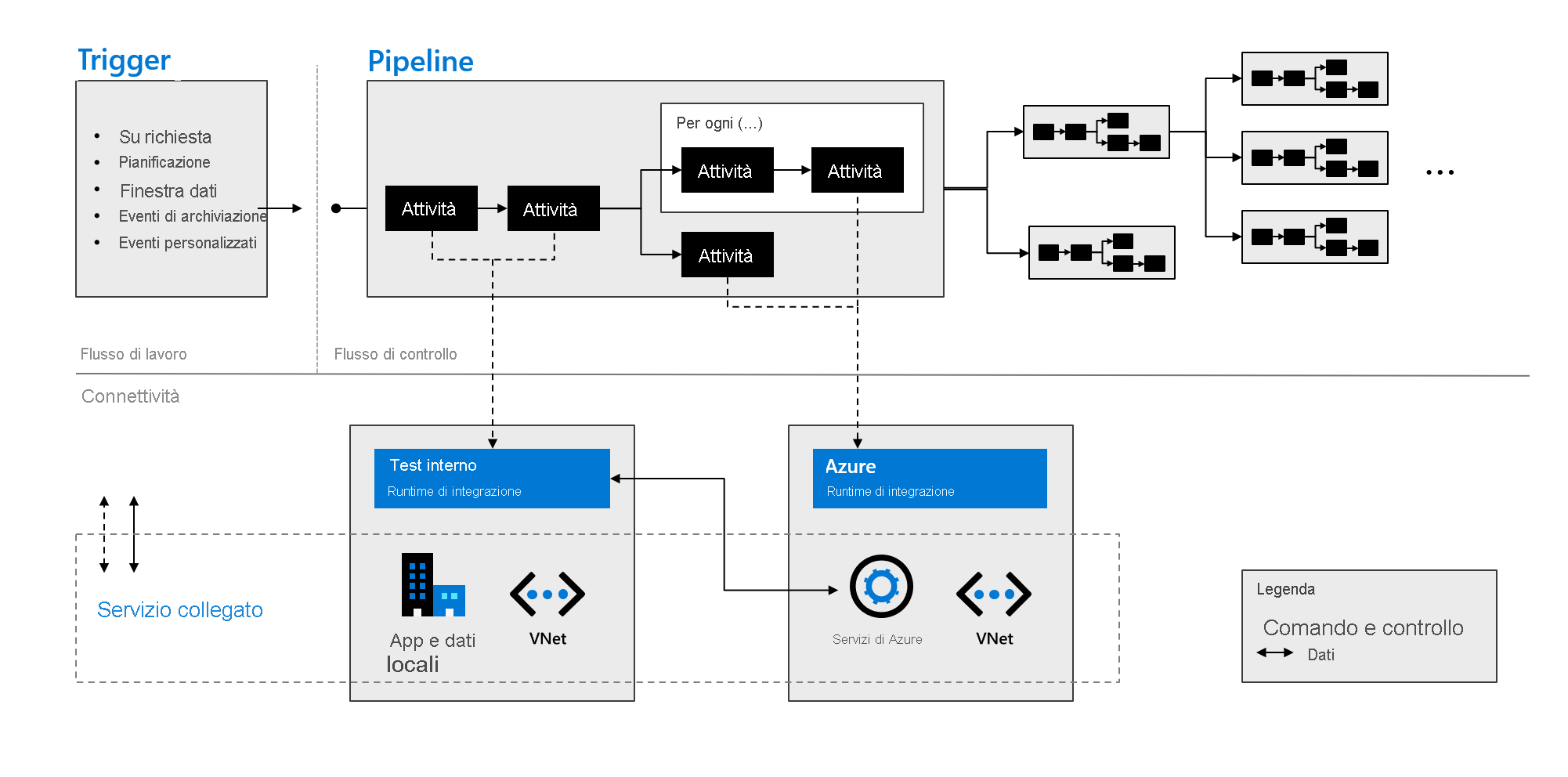
Come indicato nella figura seguente, questi componenti lavorano insieme per offrire una piattaforma end-to-end completa per i data engineer. Usando Data Factory, è possibile:
- Impostare i trigger su richiesta e pianificare l'elaborazione dei dati in base alle esigenze.
- Associare una pipeline a un trigger o avviarla manualmente come e quando necessario.
- Connettersi ai servizi collegati, ad esempio app e dati locali, o ai servizi di Azure usando i runtime di integrazione.
- Monitorare tutte le esecuzioni della pipeline in modo nativo nell'esperienza utente di Azure Data Factory o usando Monitoraggio di Azure.