Reti neurali convoluzionali
Suggerimento
Per altri dettagli, vedi la scheda Testo e immagini .
La possibilità di usare filtri per applicare effetti alle immagini è utile nelle attività di elaborazione delle immagini, ad esempio con il software di modifica delle immagini. Tuttavia, l'obiettivo della visione artificiale è spesso estrarre significato, o almeno informazioni interattive, dalle immagini; che richiede la creazione di modelli di Machine Learning sottoposti a training per riconoscere le funzionalità in base a grandi volumi di immagini esistenti.
Suggerimento
Questa unità presuppone che si abbia familiarità con i principi fondamentali di Machine Learning e che si abbia una conoscenza concettuale dell'apprendimento avanzato con le reti neurali. Se non si ha familiarità con l'apprendimento automatico, è consigliabile completare il modulo Introduzione ai concetti di Machine Learning in Microsoft Learn.
Una delle architetture di modelli di Machine Learning più comuni per visione artificiale è una rete neurale convoluzionale (CNN), un tipo di architettura di Deep Learning. Le CNN usano filtri per estrarre le mappe delle caratteristiche numeriche dalle immagini e quindi inserire i valori delle caratteristiche in un modello di deep learning per generare una previsione delle etichette. Ad esempio, in uno scenario di classificazione delle immagini , l'etichetta rappresenta il soggetto principale dell'immagine (in altre parole, qual è questa immagine di?). È possibile eseguire il training di un modello CNN con immagini di diversi tipi di frutta (ad esempio mela, banana e arancione) in modo che l'etichetta stimata sia il tipo di frutta in una determinata immagine.
Durante il processo di training per una CNN, i kernel di filtro vengono inizialmente definiti usando valori di peso generati in modo casuale. Quindi, man mano che il processo di training avanza, le stime dei modelli vengono valutate rispetto ai valori di etichetta noti e i pesi del filtro vengono modificati per migliorare l'accuratezza. Infine, il modello di classificazione delle immagini dei frutti sottoposto a training usa i pesi del filtro che consentono di estrarre meglio le caratteristiche che consentono di identificare diversi tipi di frutta.
Il diagramma seguente illustra il funzionamento di una rete CNN per un modello di classificazione delle immagini:
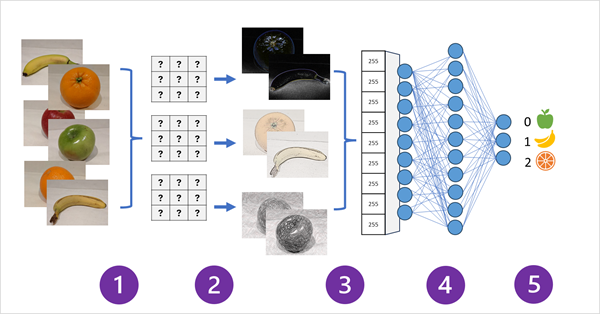
- Le immagini con etichette note (ad esempio, 0: mela, 1: banana o 2: arancione) vengono inserite nella rete per eseguire il training del modello.
- Uno o più livelli di filtri vengono usati per estrarre le caratteristiche da ogni immagine man mano che viene alimentato attraverso la rete. I kernel di filtro iniziano con pesi assegnati in modo casuale e generano matrici di valori numerici denominati mappe delle funzionalità. I livelli aggiuntivi possono "pool" o "ridimensionare" le mappe delle funzionalità per creare matrici più piccole che enfatizzano le principali caratteristiche visive estratte dai filtri.
- Le mappe delle caratteristiche vengono ridotte in una matrice unidimensionale di valori delle caratteristiche.
- I valori delle caratteristiche vengono inseriti in una rete neurale completamente connessa.
- Il livello di output della rete neurale usa una funzione softmax o simile per produrre un risultato che contiene un valore di probabilità per ogni classe possibile, ad esempio [0,2, 0,5, 0,3].
Durante il training, le probabilità di output vengono confrontate con l'etichetta di classe effettiva, ad esempio un'immagine di una banana (classe 1) deve avere il valore [0,0, 1,0, 0,0]. La differenza tra i punteggi di classe stimati e effettivi viene usata per calcolare la perdita nel modello e i pesi nella rete neurale completamente connessa e i kernel di filtro nei livelli di estrazione delle caratteristiche vengono modificati per ridurre la perdita.
Il processo di training si ripete in più periodi fino a quando non è stato appreso un set ottimale di pesi. Vengono quindi salvati i pesi e il modello può essere usato per stimare le etichette per le nuove immagini per le quali l'etichetta è sconosciuta.
Annotazioni
Le architetture CNN in genere includono più livelli di filtro convoluzionali e livelli aggiuntivi per ridurre le dimensioni delle mappe delle funzionalità, vincolare i valori estratti e modificare in caso contrario i valori delle funzionalità. Questi livelli sono stati omessi in questo esempio semplificato per concentrarsi sul concetto chiave, ovvero che i filtri vengono usati per estrarre caratteristiche numeriche dalle immagini, che vengono quindi usate in una rete neurale per stimare le etichette delle immagini.